当前人工智能领域的成功,往往依赖于机器算力的提升以利用大量的数据,但人类智能却可以利用以往的经验针对新的问题从少量的样本中进行有效的学习。在现实中,随着更多应用场景的涌现,我们也将必然面临更多数据不足的问题,因此如何能够让机器像人类一样能够利用学习经验从小样本中进行有效学习,成为了一个重要的研究方向。
目前,成功的深度神经网络往往依赖于大量训练数据和训练时间,当训练数据较少时,神经网络通常容易过拟合,这是由于传统的基于梯度的更新算法没有针对当前任务的先验知识,无法在神经网络的参数空间中找到具有较好泛化能力的参数点。当一个神经网络计算结构固定的时候,网络的参数权重决定了网络的功能,而具有较好泛化能力的参数点可以看作是一个基于训练数据的条件概率分布。根据这样的观察,我们针对小样本问题提出了一种基于训练数据直接生成具有较好泛化性网络参数的元学习方法,让神经网络在大量的任务中积累经验,自己学会如何解决小样本问题。
如图一所示,我们的方法框架,主要由两部分组成,即元网络(MetaNet)和目标网络(TargetNet)。目标网络是针对某个问题设计的网络结构,如分类或回归网络,并且目标网络中没有可学习参数,它的参数由元网络产生,在本文中使用matching networks的网络结构作为TargetNet来解决小样本分类问题。
元网络,由任务环境编码网络(task context encoder)和参数生成器(weight generator)组成,它的目的是编码任务数据(如果是高维数据则编码数据特征)然后采样生成目标网络的功能参数。
在训练过程中,不断地从环境中获取不同的小样本任务,使用任务环境网络将任务数据表示为一个任务特征,基于这个任务特征,通过参数生成器采样出一个针对当前这个任务的目标网络对应层的参数,使网络具有解决当前任务的分类能力,通过累积不同任务的loss来调整元网络的参数,从而在元网络中学习到如何让目标网络解决小样本任务的能力。
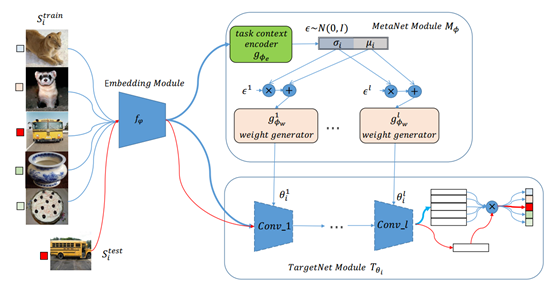
图一、算法整体框架
在Omniglot和miniImageNet数据集上验证了方法的有效性,在不同的N-way K-shot都获得了很好的效果,特别在5-way 1-shot任务上对比SOTA结果提升了8%。
本研究提出了通过参数生成的方式来学习嵌入先验知识解决小样本问题的方法,这种方式不需要进行微调,当遇到新的相似任务的时候,可以快速适应。 相关工作已被国际会议ICML2019接收。
LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning
Huaiyu Li, Weiming Dong, Xing Mei, Chongyang Ma, Feiyue Huang, Bao-Gang Hu