日前,神经信息处理系统大会(NeurIPS 2019)于12月8日至14日在加拿大温哥华举行,我所程健研究员率队在本次大会的神经网络压缩与加速竞赛(MicroNet Challenge)中获得双料冠军!
以模型压缩和加速为代表的深度学习计算优化技术是近几年学术界和工业界最为关注的焦点之一。随着人工智能技术不断地落地到各个应用场景中,在终端上部署深度学习方案面临了新的挑战:模型越来越复杂、参量越来越多,但终端的算力、功耗和内存受限,如何才能得到适用于终端的性能高、速度快的模型?
由Google、Facebook、OpenAI等机构在NeurIPS2019上共同主办的MicroNet Challenge竞赛旨在通过优化神经网络架构和计算,达到模型精度、计算效率、和硬件资源占用等方面的平衡,实现软硬件协同优化发展,启发新一代硬件架构设计和神经网络架构设计等。MicroNet Challenge竞赛对于人工智能软件、硬件的未来发展都有着非比寻常的意义,此次不仅集结了MIT、加州大学、KAIST、华盛顿大学、京都大学、浙大、北航等国内外著名前沿科研院校,同时还吸引了ARM、IBM、高通、Xilinx等国际一流芯片公司的参与。
MicroNet Challenge竞赛包括ImageNet图像分类、CIFAR-100图像分类和WikiText-103语言模型三个子任务。程健研究员带队参加了竞争最激烈的ImageNet和CIFAR-100两个子任务比赛,并最终包揽了图像类的两项冠军。
团队结合极低比特量化技术和稀疏化技术,在ImageNet任务上相比主办方提供的基准模型取得了20.2倍的压缩率和12.5倍的加速比,在CIFAR-100任务上取得了732.6倍的压缩率和356.5倍的加速比,遥遥领先两个任务中的第二名队伍。
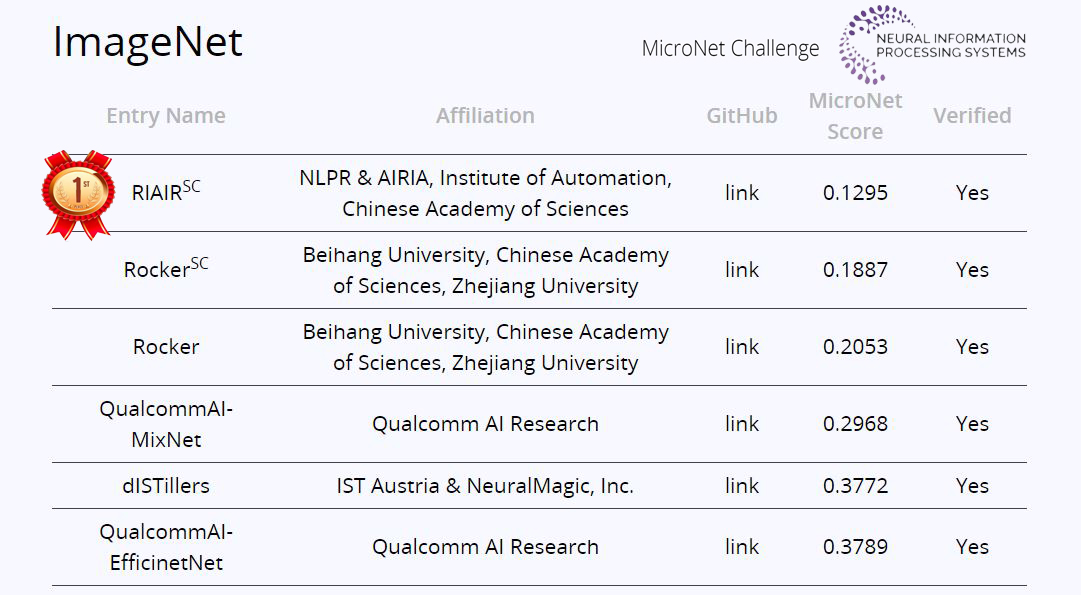
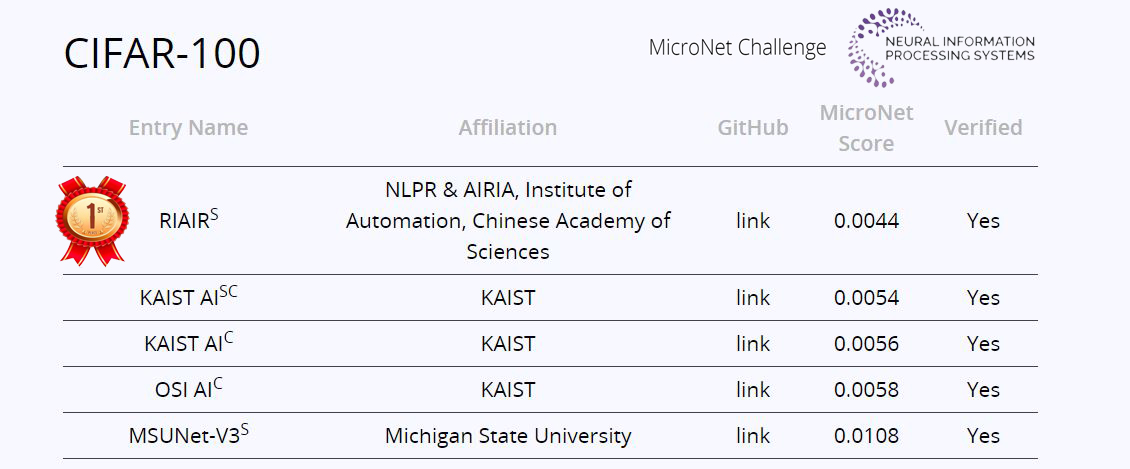
图:竞赛公布名次
团队同时受邀在大会上做题为“A Comprehensive Study of Network Compression and Acceleration”的报告,详细介绍了相关的量化和稀疏化压缩和加速技术。
针对比赛任务,团队在报告中给出解决办法:采用量化和稀疏化技术,将深度学习算法模型进行轻量化和计算提速,以大幅降低算法模型对算力、功耗以及内存的需求,让低端设备实现人工智能方案。团队成员冷聪副研究员表示,量化及稀疏化技术也是人工智能深度学习的软、硬件协同加速方案突破口。通过将其与人工智能硬件架构设计紧密结合,可以进一步降低人工智能技术落地难度,让AI更为易得易用。

图:程健研究员进行报告
团队介绍:
中科院自动化所程健研究员领导的类脑芯片与系统研究部,主要围绕新型智能芯片、高效自主智能系统两个方向展开研究,在神经网络模型计算优化、智能芯片架构设计、自主智能计算系统等方面已经取得了初步成果。团队是国际上较早开展深度神经网络加速和压缩研究的团队之一,提出了一系列的网络模型加速与压缩方法,相关工作发表在IEEE/ACM会刊、CVPR、ICCV、AAAI、DATE、ACM MM等国际杂志和会议上,部分成果在华为、戴尔、阿里巴巴等国内外企业产品上得到应用和推广。