随着近年来音视频生成技术的不断发展,“虚拟主播”逐渐走入人们视野,并以其在虚拟客服、远程会议、电影剪辑等现实应用场景中的重要作用而获得了社会各界的广泛关注。该技术旨在对输入的音频预测相应口型,从而生成指定或任意人物的自然而准确的面部说话视频。近日,中科院自动化所智能感知与计算研究中心为此提出了一种新颖的音视频协同计算方法,并重点解决了此前难以达成的任意人物协同生成问题。该方法一方面实现了利用语音驱动任意对象的高清视频生成,另一方面在正脸、侧脸等多种场景下均显著提升了生成视频质量。目前,该成果已被IJCAI 2020大会接收。
由于音视频模态之间差异性等问题,这项技术目前仍然存在着众多挑战。以往的研究方法往往将重点放在了模态内之间,如只关注了视频帧之间的损失约束,却忽略了音视频模态间最重要的问题之一:如何将音频信息高效充分地表达入视频模态?同时由于人物与人物之间的个体差异,将同一模型应用于任意人物视频生成也存在较大的挑战。
为解决上述问题,团队精心设计了一个非对称式互信息估计器(Asymmetric Mutual Information Estimator, AMIE),以构建音视频模态间的约束。如图1示,输入一对音频与人脸图像数据,互信息估计器输出预测的互信息值。在这里,该方法使用Jensen-Shannon表示形式来改善互信息计算方式,使其更好地应用于神经网络。通过这样的互信息估计方式,该方法最大化音频与视频模态之间的互信息,减少音频向视频模态表达的不确定性,并以此获得音频和视频信息之间的跨模态一致性,使得生成视频中人物的口型更加准确自然。
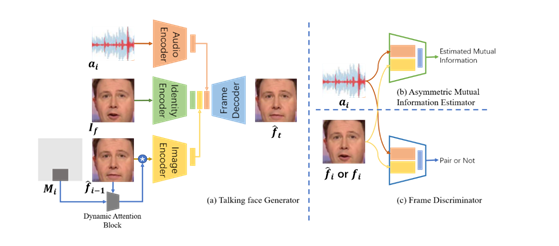
图 1 模型基本流程与结构
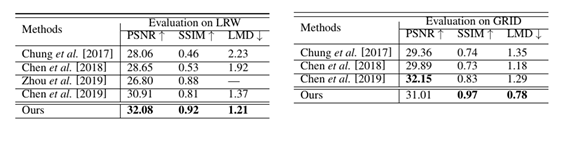
该方法在LRW和GRID基础数据集上进行了实验验证。图2中的结果表明该方法生成的口型准确度高,且能够有效适应不同肤色与嘴唇形状差异。表1的量化结果显示该方法在常用的对比指标上的优越性能。

图 2 LRW测试结果
表 1 实验定量指标评估
该方法有能力对不存在于数据集中的任意人物进行视频合成,并能够有效处理如姿态表情、性别差异等变化因素(见图3)。例如,输入一段女性语音(图中第二行),该方法分别生成了现实场景的同性别人脸视频(图中第一行),和跨性别人脸视频(图中第三行)。

图 3 现实场景测试结果
论文:
[1] Hao Zhu, Huaibo Huang, Yi Li, Aihua Zheng, Ran He. Arbitrary Talking Face Generation via Attentional Audio-Visual Coherence Learning. IJCAI, 2020.
[2] Hao Zhu, Mandi Luo, Rui Wang, Aihua Zheng, Ran He. Deep Audio-Visual Learning: A Survey. arXiv:2001.04758, 2019