跨语言自动摘要是一项对源语言文本核心信息进行内容归纳,以目标语言的形式组织成摘要的任务。跨语言自动摘要方法研究对于跨境电商(辅助用户进行决策)、舆情分析(帮助分析人员过滤冗余信息)和内容推荐(为用户推荐外语新闻)等应用场景具有重要意义。
由于平行数据的缺失,大多数已有的跨语言自动摘要方法只能基于管道式方法实现,造成严重的误差传播问题,使得摘要质量受到极大的制约。
为缓解此问题,研究人员开始尝试构建跨语言自动摘要平行数据,并在此基础上开展基于深度学习的跨语言自动摘要方法(或称神经跨语言自动摘要)研究。其中较为典型的方法有基于多任务学习的方法,该方法在多任务学习框架基础上,利用单语言自动摘要、机器翻译的数据提升跨语言自动摘要模型的性能,取得了相当良好的性能。然而,基于多任务学习的方法存在依赖外部数据、模型容量较大且需要很长的训练时间等缺陷,使其难以应用于真实场景。
针对此问题,自动化所自然语言处理团队提出一种融合翻译模式的跨语言自动摘要方法,有效缓解已有方法的缺陷,相关成果发表于第五十八届国际计算语言学年会(ACL-2020)。
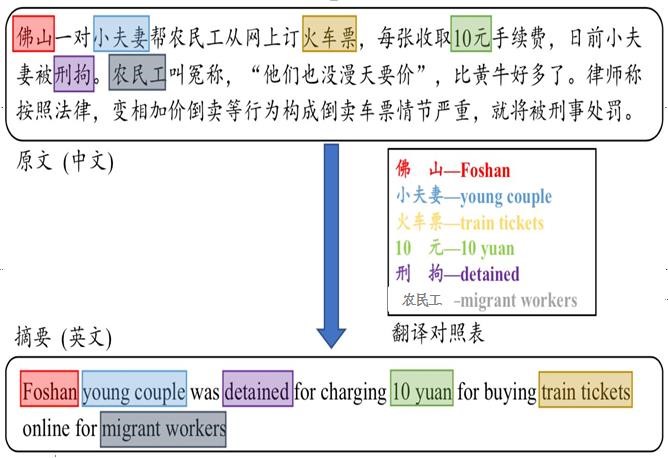
图1.“翻译”现象的示例
该工作受跨语言自动摘要中存在的“翻译”现象(即目标端的词汇可通过翻译源端某些词汇得到)的启发,将跨语言自动摘要分解为三个步骤:聚焦(attend)、翻译(translate)和归纳(summarize),整体框架如图2所示。具体而言,该方法首先通过注意力机制对原文包含的重要内容词进行聚焦,并得到这些关键词的翻译候选(translation candidates),最后依据翻译候选或者神经概率分布(neural distribution)生成摘要词汇。
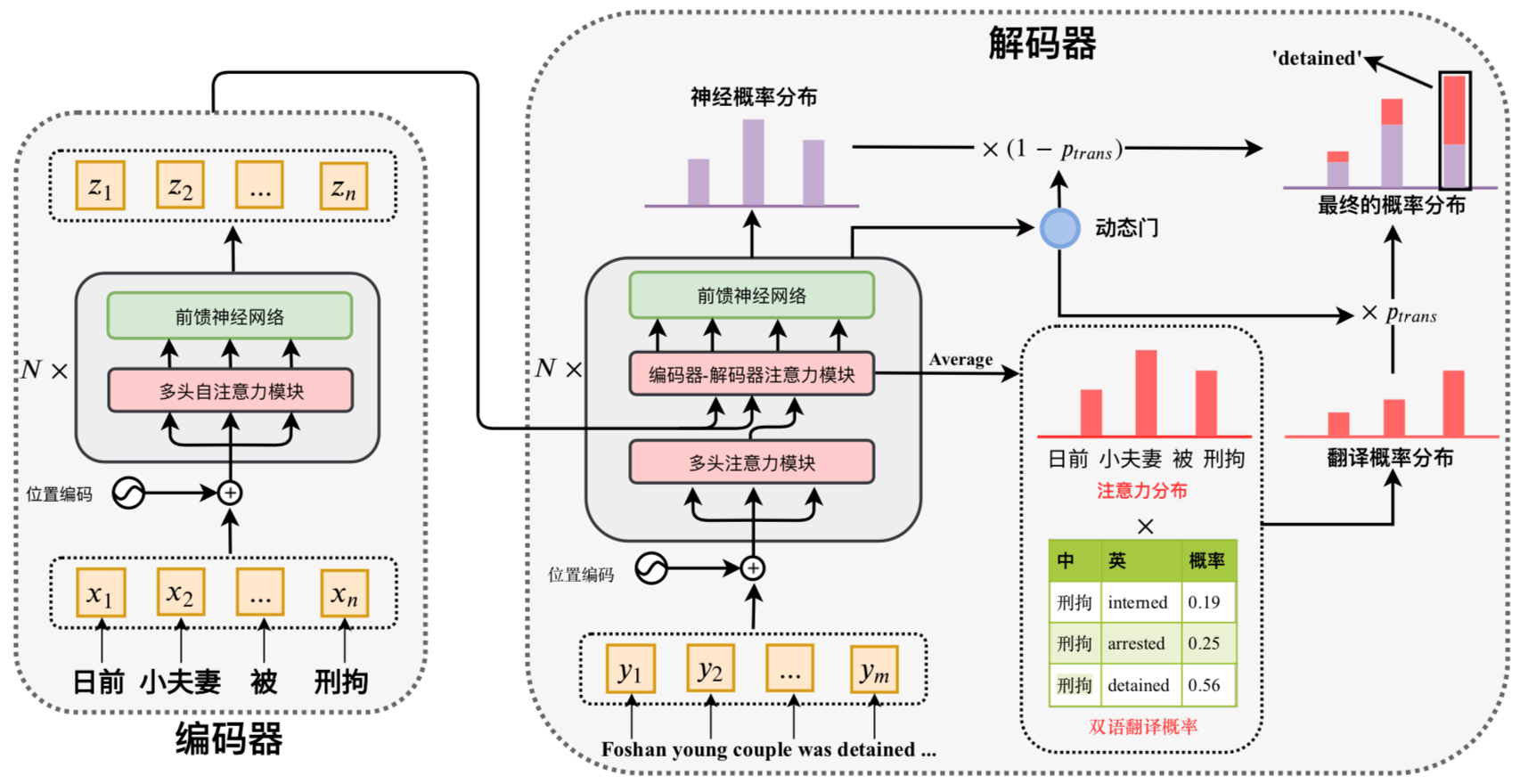
图2. 融合翻译模式的跨语言自动摘要方法示意图
针对于“翻译”步骤,团队尝试并对比了三种策略:“朴素(Naive)”、“平等(Equal)”和“适应(Adapt)”。“朴素”策略直接将概率双语词典中的翻译概率作为词汇的双语翻译概率,而“平等”策略则是将概率双语词典中的翻译概率进行平均处理,“适应”策略将源端的上下文语义信息用于动态地挑选合适的翻译候选。
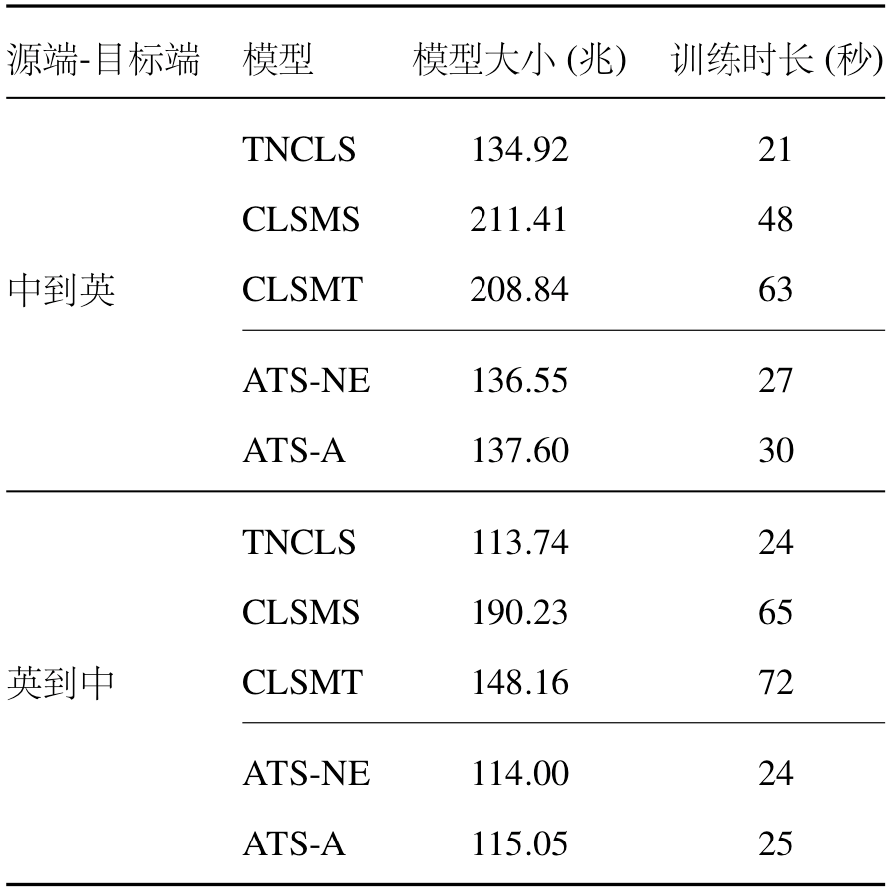
团队在大规模的“中到英”(Zh2EnSum)和“英到中”(En2ZhSum)跨语言自动摘要数据集上进行实验,以验证所提方法的有效性,实验结果如表1所示。相较于基线系统,所提方法在两个不同的语言方向上均能获得显著提升。同时,所提方法取得了与基于多任务学习的方法(CLSMS和CLSMT)相当的性能,甚至在多数指标上要优于基于多任务学习的方法,但所提方法只需要一个额外的概率双语词典而不需要引入其他任务的数据,所以极大地降低了模型对于数据的依赖性。与基于多任务学习的方法相比,所提方法另一优势在于,所提方法由于仅包含单个编码器与单个解码器,且只使用跨语言自动摘要的数据进行训练,因此具有更小的模型容量与更高的训练效率,具体的实验对比见表2。
归纳而言,融合翻译模式的跨语言自动摘要方法能够生成与基于多任务学习方法质量相当的摘要,但相比之下前者具有降低模型对于数据的依赖、减小模型容量和提升训练效率的优势。
表1. 融合翻译模式的跨语言自动摘要方法(ATS)与现有方法对比
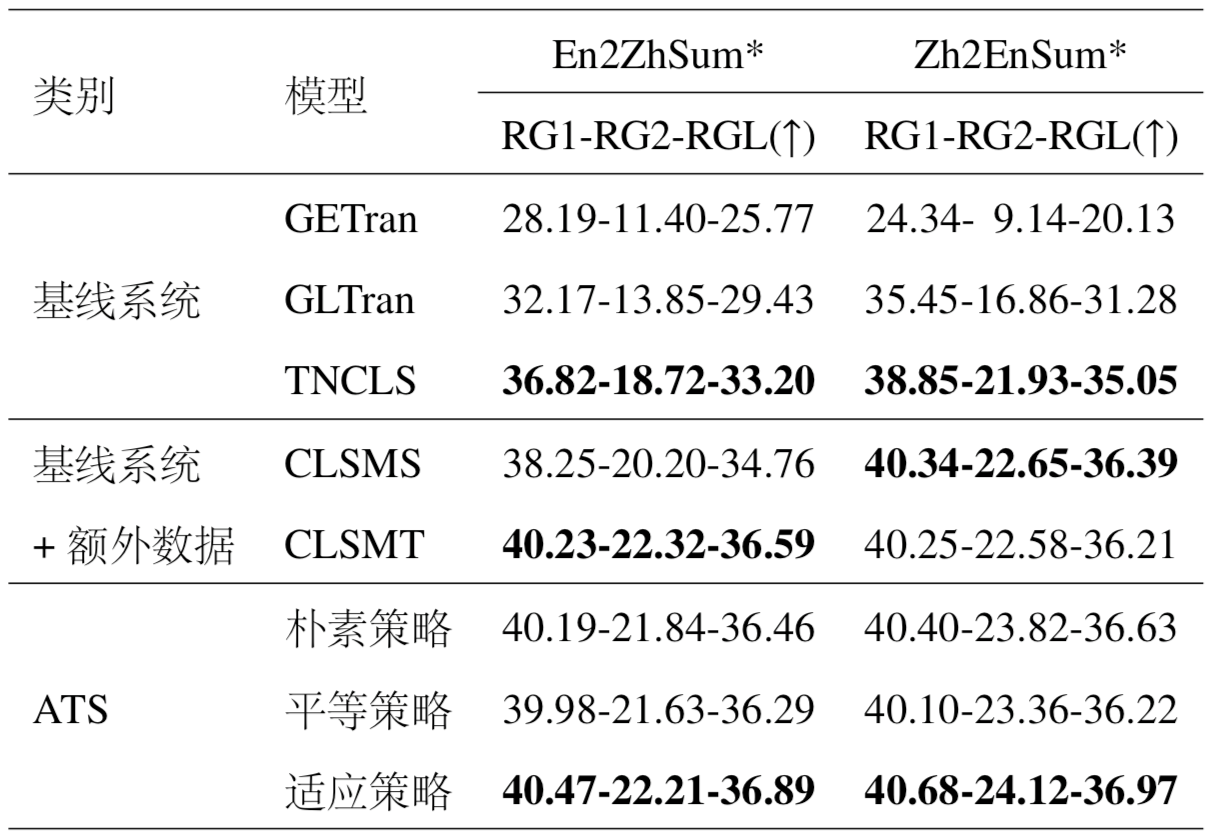
表2. 模型大小和训练时长对比
论文:Junnan Zhu, Yu Zhou, Jiajun Zhang, and Chengqing Zong. Attend, Translate and Summarize: An Efficient Method for Neural Cross-Lingual Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020.