国际智能体和多智能体系统会议(International Conference on Autonomous Agents and Multi-agent Systems,AAMAS),是智能体和多智能体系统领域最大和最有影响力的国际学术会议之一。智能体研究作为人工智能领域的重要分支,具有巨大的革新潜力与应用前景,其发展对于理解人类智能本质,推动人工智能技术发展,解决社会问题具有重要价值。第23届AAMAS于5月6日至10日在新西兰召开。自动化所多篇研究论文被本届AAMAS录用,并参与组织了两项智能体赛事。
一、研究论文
1.面向连续控制的一致性策略
Boosting Continuous Control with Consistency Policy
论文作者:陈宇辉,李浩然,赵冬斌
深度强化学习团队提出了一种新的基于一致性模型(Consistency Model)的强化学习策略表征方法——Consistency Policy with Q-Learning (CPQL)。该方法使用单步逆扩散过程从高斯噪声中生成动作用于智能体决策。通过建立从逆扩散轨迹到期望策略的映射,解决了使用值函数更新基于扩散模型策略时的时间效率低下和非精确引导问题。通过理论证明了该方法可以实现对离线强化学习策略优化的精确引导,并且可以轻松扩展到在线强化学习任务。实验结果表明,CPQL在11个离线任务和21个在线任务上实现了新SOTA性能。同时与基于扩散模型的方法相比,推理速度提高了近45倍。
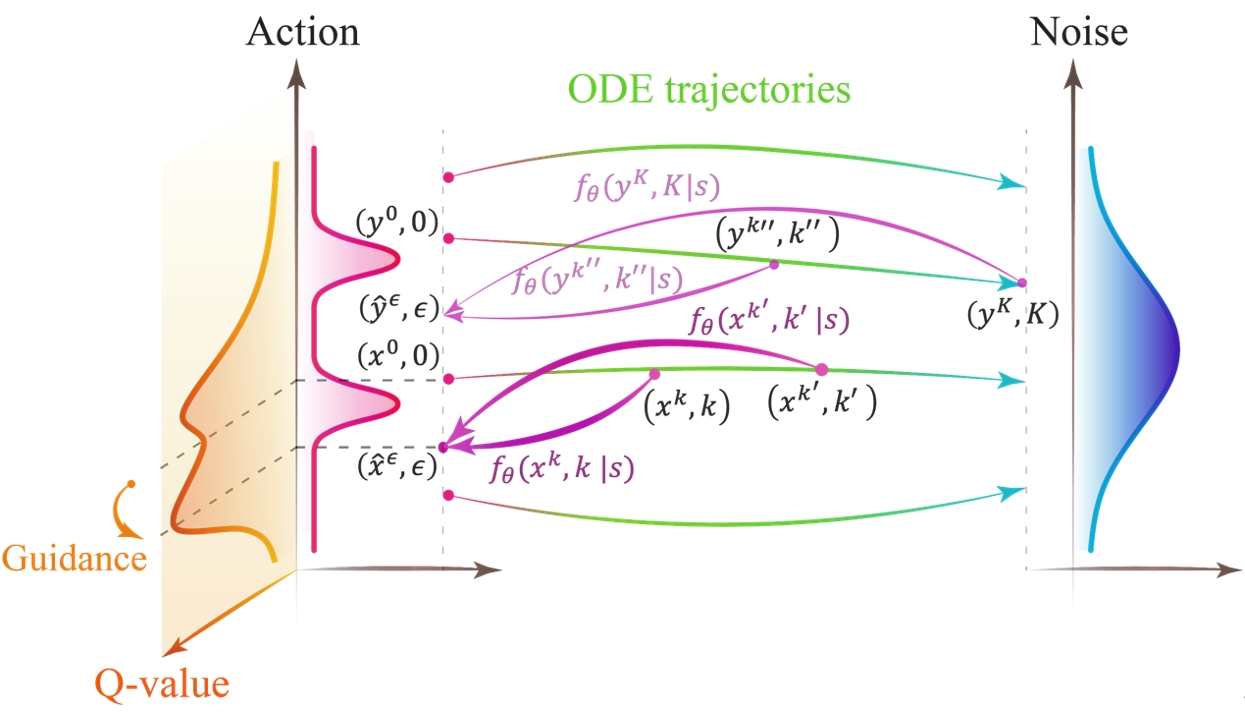
CPQL正向扩散过程和逆向引导扩散过程: 给定一个从动作逐渐加噪声的 ODE轨迹,一致性策略学习轨迹上的任意点到最优动作的映射。由于一致性策略单步迭代生成动作,因此大大加速策略训练和推理的时间。
论文链接:https://arxiv.org/abs/2310.06343
代码开源:https://github.com/cccedric/cpql
2. 基于反事实信誉分配的协作多智能体强化学习算法
Aligning Credit for Multi-Agent Cooperation via Model-based Counterfactual Imagination
论文作者:柴嘉骏、傅宇千、赵冬斌、朱圆恒
现有基于模型的多智能体强化学习方法仍采用为单智能体环境设计的训练框架,导致现有算法对多智能体协作的促进不足。该研究提出了一种新颖的基于模型的多智能体强化学习方法,称为多智能体反事实Dreamer(MACD)。其引入了一种集中式想象与分布式执行框架,用于生成更高质量的想象数据以进行策略学习,从而进一步提高算法的样本效率,并通过生成额外的反事实轨迹评估单一智能体对整体的贡献,进而解决信誉分配和非平稳问题。研究中提供了对应的理论推导,表明该反事实策略更新规则能够提升多智能体协作学习目标。实验结果验证了该研究在样本效率、训练稳定性和最终合作性能方面相较于几种最先进的无模型和有模型的多智能体强化学习算法的优越性。消融研究和可视化演示进一步强调了该训练框架以及其反事实模块的重要性。
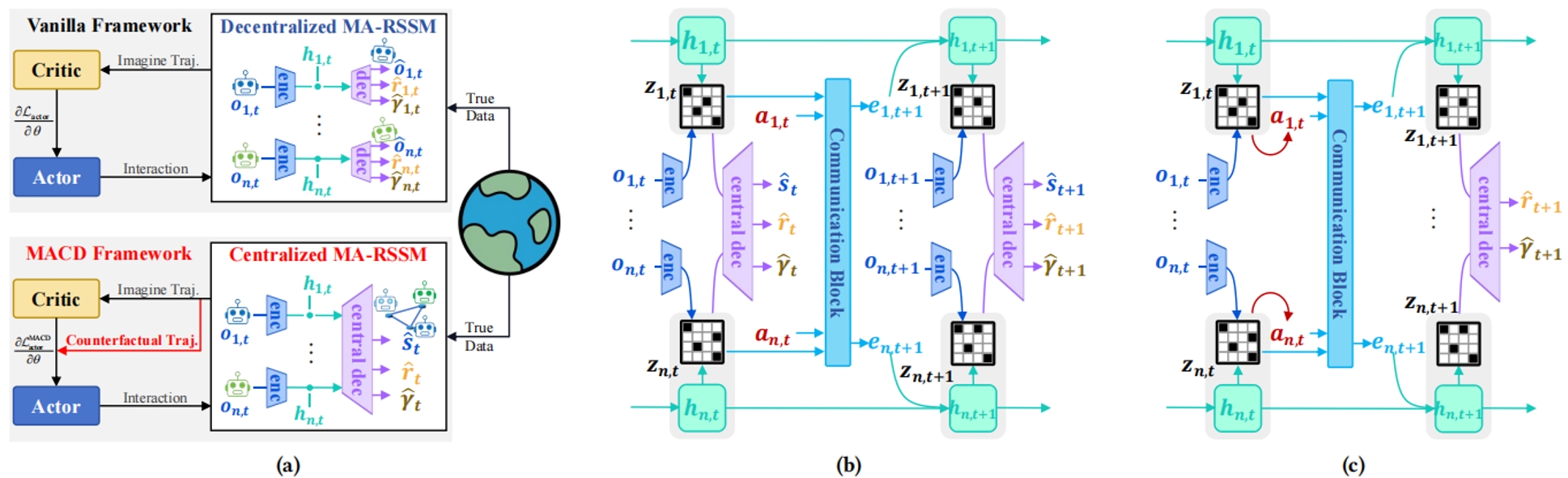
MA-RSSM框架。(a) MACD与已有算法框架的对比。(b) 集中式想象世界模型。智能体将在该模型中建模整个系统的状态转移过程。(c) 想象空间内进行的集中式预测。通信模块聚合来自所有智能体的输入信息,并生成智能体i的通信特征。
3.多智能体强化学习中的智能体策略距离度量
Measuring Policy Distance for Multi-Agent Reinforcement Learning
论文作者:扈天翼、蒲志强;艾晓琳;丘腾海;易建强
策略多样性对于提升多智能体强化学习的效果起着至关重要的作用。尽管现在已经有许多基于策略多样性的多体强化学习算法,但是目前尚缺乏一个通用的方法来量化智能体之间的策略差异。测量策略差异性不仅能够方便评估多智能体系统在训练中的多样性演化,还有助于为基于策略多样性的算法设计提供指导。为此,我们提出了MAPD,一个通用的多智能体策略距离度量方法。不同于直接量化形式各异的动作分布间的距离,该方法通过学习智能体决策的条件表征来间接量化智能体的策略距离。我们还开发了MAPD的扩展版本CMAPD,其能够量化智能体策略在特定倾向上的差异,如两个智能体在攻击倾向和防御倾向上的策略差异。基于MAPD和CMAPD的在线部署,我们设计了一套多智能体动态参数共享算法MADPS。实验表明我们的方法在测量智能体策略差异和特定行为倾向上的差异是有效的。而且,与其他参数共享方法相比,MADPS展示了更优越的性能。
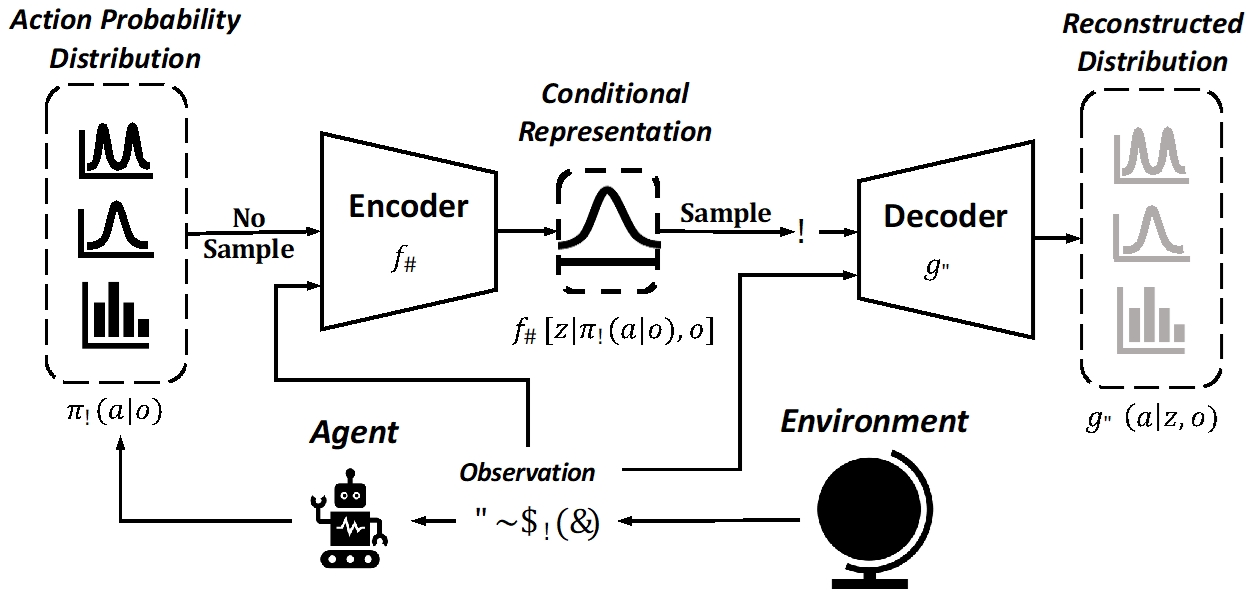
学习智能体决策的条件表征
论文链接:https://arxiv.org/pdf/2401.11257
代码链接:https://github.com/Harry67Hu/MADPS
4.TaxAI: 动态经济仿真器和多智能体强化学习算法基准
TaxAI: A Dynamic Economic Simulator and Benchmark for Multi-Agent Reinforcement Learning
论文作者:米祈睿,夏思宇,宋研,张海峰,朱胜豪,汪军
税收是政府促进经济增长和保障社会公正的关键手段。但是,准确预测多样的自利家庭的动态策略是非常困难的,这对政府制定有效的税收政策构成了挑战。多智能体强化学习(MARL),凭借其在模拟部分可观测环境中的其他智能体、以及适应性学习求解最优策略的能力,非常适合去解决政府与众多家庭间的动态博弈问题。尽管MARL展现出比遗传算法和动态规划等传统方法更大的潜力,但目前仍缺乏大规模的多智能体强化学习经济模拟器。因此,我们基于Bewley-Aiyagari经济模型,提出了一个名为 TaxAI 的MARL环境,用于模拟包括众多家庭、政府、企业和金融中介在内的动态博弈。我们的研究在TaxAI上对2种传统经济方法与7种MARL方法进行了对比,证明了MARL算法的有效性和优越性。更重要的是,TaxAI在模拟政府与高达10,000户家庭之间的动态互动及其与真实数据的校准能力上,都大幅提升了模拟的规模和现实性,使其成为目前最为逼真的经济模拟器。
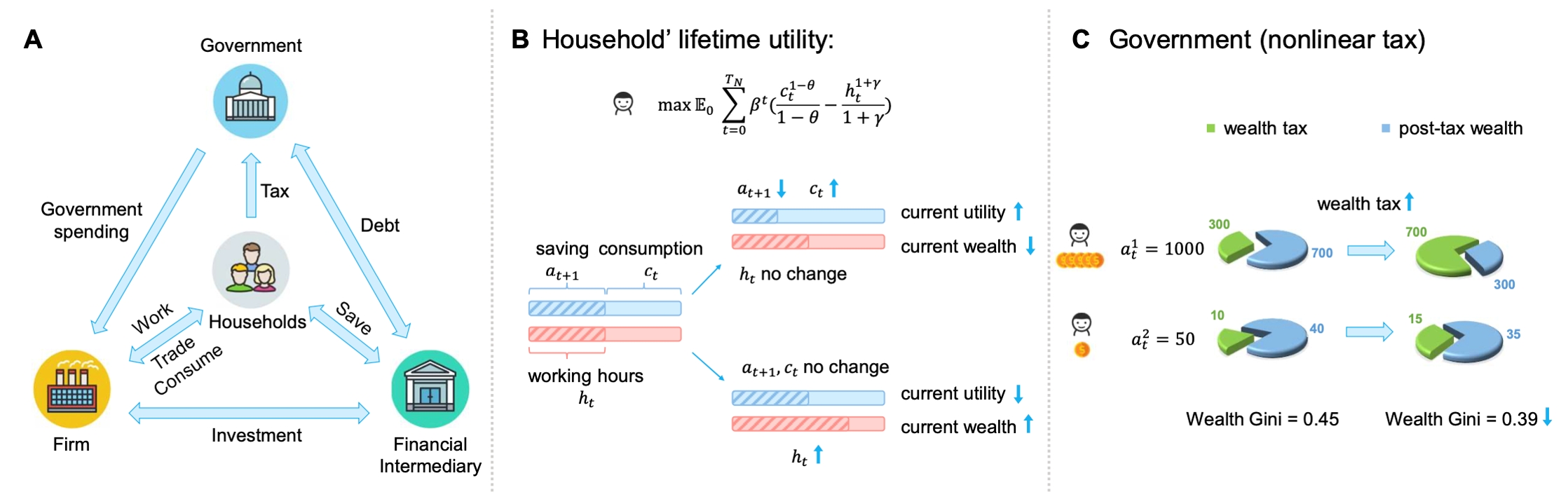
图1. Bewley-Aiyagari模型动力学
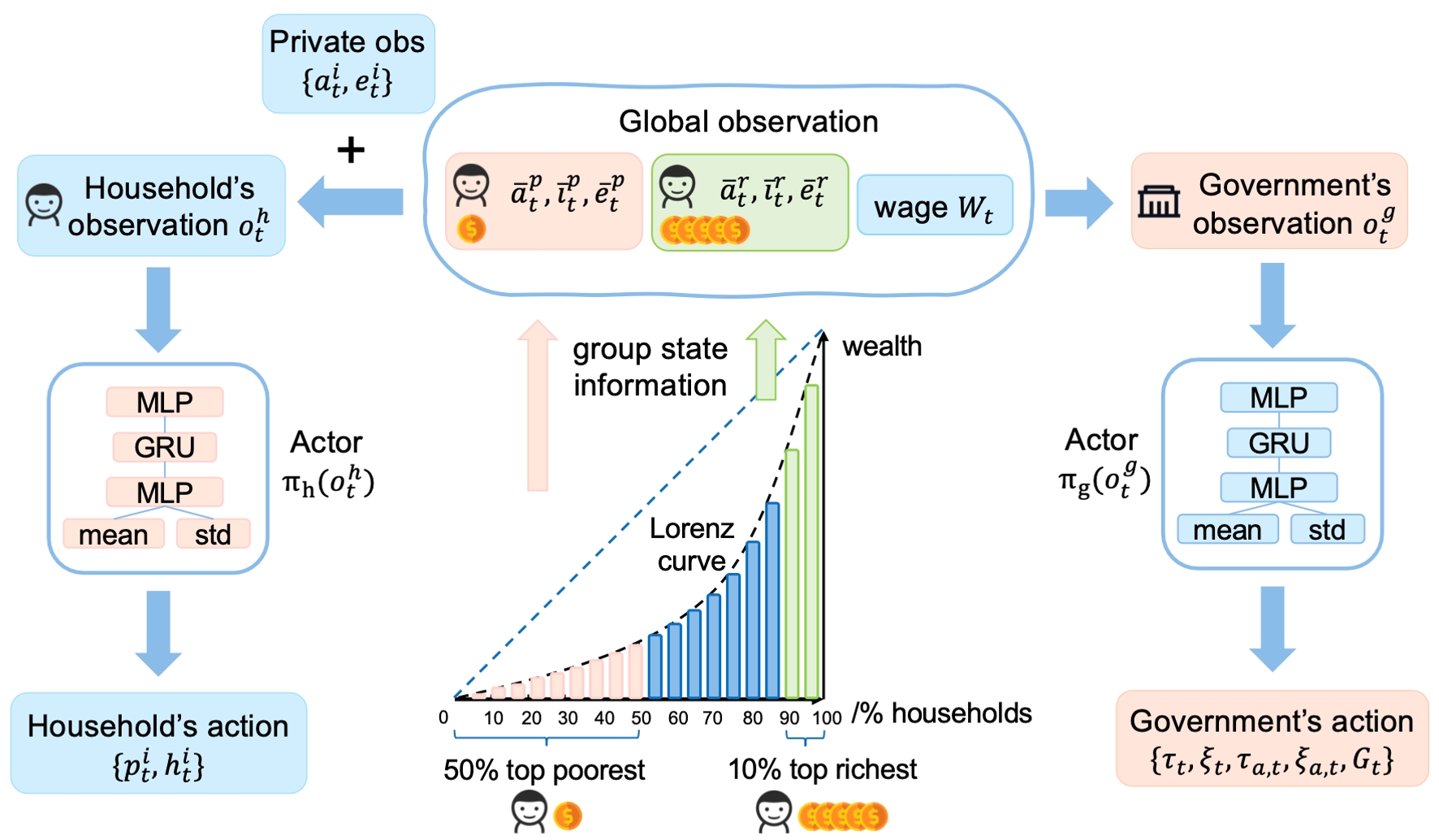
图2. 政府与家庭智能体之间的部分可观测马尔科夫博弈
论文链接:https://arxiv.org/abs/2309.16307
代码链接:https://github.com/jidiai/TaxAI
5.谷歌足球环境中的多智能体强化学习研究:回顾、现状和展望
Boosting Studies of Multi-Agent Reinforcement Learning on Google Research Football Environment: the Past, Present, and Future
论文作者:宋研,江河,张海峰,田政,张伟楠,汪军
尽管Google Research Football(GRF)在其原始论文中最初是作为单智能体环境进行基准测试和研究,但近年来,越来越多的研究人员开始关注其多智能体性质,将其作为多智能体强化学习(MARL)的测试平台,尤其是在合作场景中。然而,由于缺乏标准化的环境设置和统一的多智能体场景评估指标,各研究之间难以形成一致的理解。此外,由于5对5和11对11的全局游戏场景的训练复杂度极高,相关深入研究有限。为了弥补这些不足,本文不仅通过标准化环境设置在不同场景(包括最具挑战性的全局游戏场景)中进行合作学习算法的基准测试,还从多个角度讨论了增强足球人工智能的方法,并介绍了不局限于多智能体合作学习的相关研究工具。具体来说,我们提供了一个分布式和异步的基于种群的自我对抗博弈框架,该框架包含多样化的预训练策略,以实现更高效的训练;我们还提供了两个足球分析工具,以进行更深入的研究;此外,我们还提供了一个在线排行榜,以进行更广泛的评估。这项工作旨在推进在谷歌足球环境上的相关多智能体强化学习的研究,最终目标是将这些技术部署到现实世界的应用中,如体育分析等。
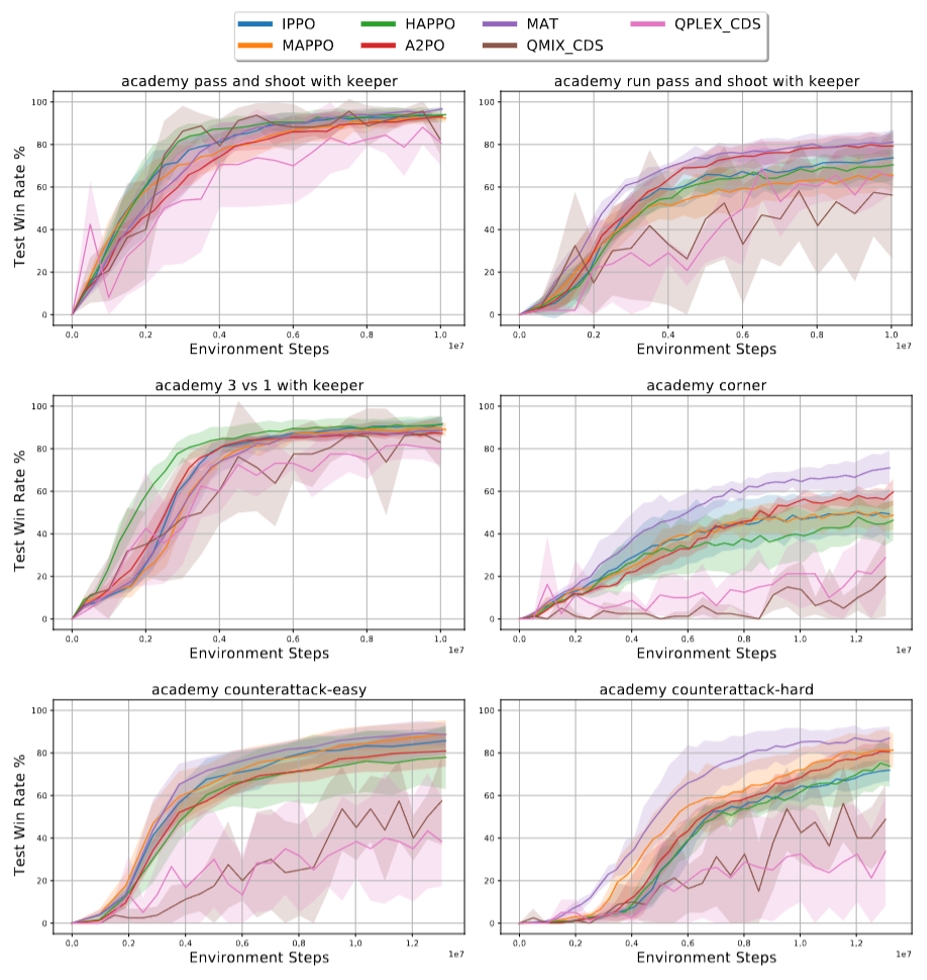
图1. 在六个Academy足球场景中不同多智能体强化学习算法的效果对比
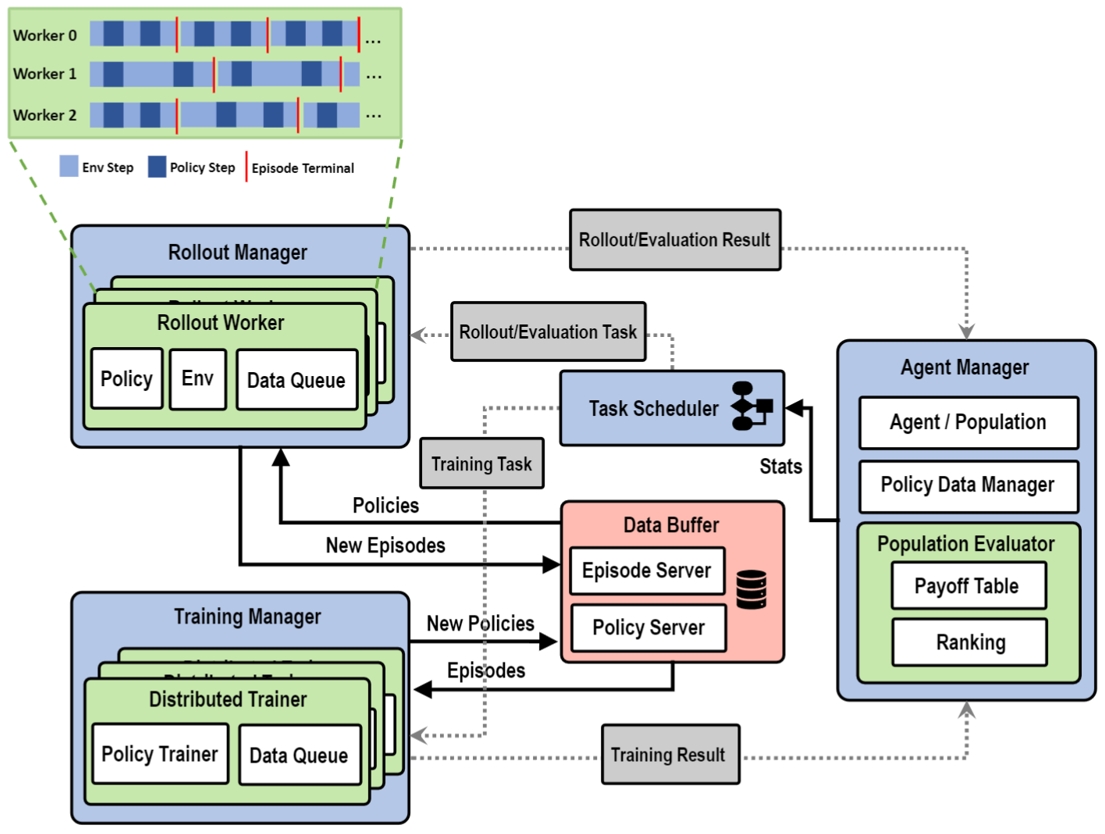
图2. 分布式异构种群自博弈训练框架示意图
论文链接:https://arxiv.org/abs/2309.12951
6.针对自然语言约束的基于预训练语言模型的安全强化学习算法
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
论文作者:娄行舟,张俊格,王梓岩,黄凯奇,杜雅丽
针对基于自然语言约束的安全强化学习中,现有方法对复杂形式自然语言约束表征能力、处理能力不足,并且将自然语言约束转化为智能体可学习的代价函数需要大量的特定领域知识的问题,我们提出使用预训练语言模型对自然语言约束进行处理,帮助智能体进行理解,并且完成代价函数预测,实现了在无需真实代价函数的前提下,让智能体能够学会遵守自由形式的复杂人类自然语言给出的约束条件。我们提出的算法在性能上可以达到与使用真实代价函数的方法相近的性能。并且在代价函数预测上,相比直接提示GPT-4来进行预测,我们所提出方法的预测结果的F1-score实现了23.9%的提升。
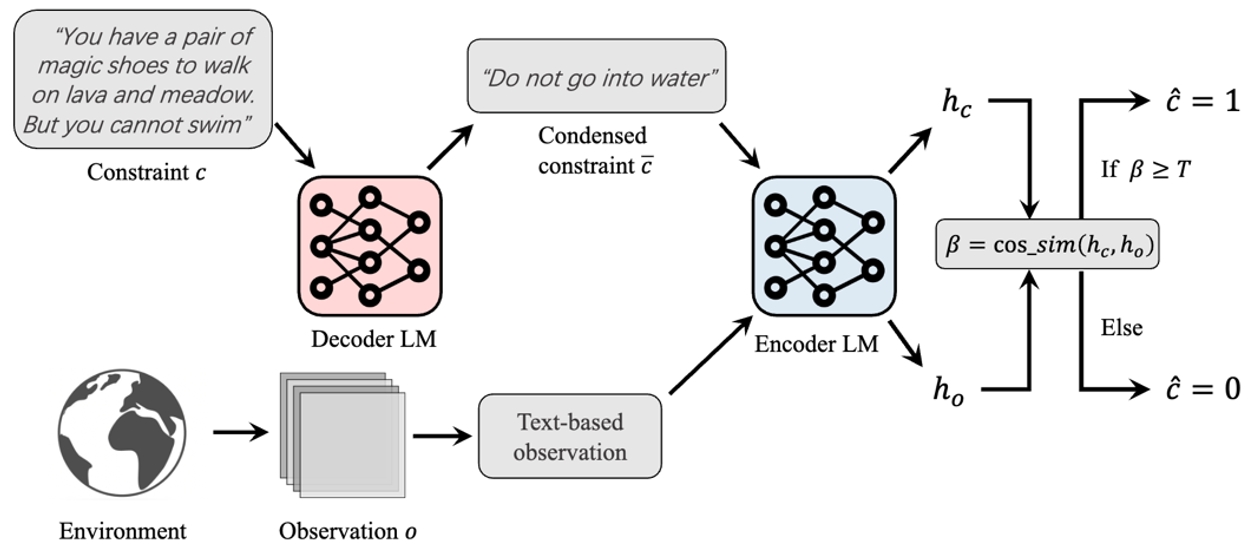
所提出方法对自然语言约束进行处理,使得处理后的约束可用于预测代价函数和约束智能体的策略
论文链接:https://arxiv.org/abs/2401.07553
7. PDiT:用于深度强化学习的感知与决策交错Transformer
PDiT: Interleaving Perception and Decision-making Transformers for Deep Reinforcement Learning
论文作者:毛航宇,赵瑞,黎子玥,徐志伟,陈皓,陈逸群,张斌,肖臻,张俊格,尹江津
设计更好的深度网络和更优的强化学习(RL)算法对深度强化学习都非常重要。本工作研究的是前者。具体来说,提出了感知与决策交错Transformer(PDiT)网络,该网络以非常自然的方式串联了两个Transformer:感知Transformer专注于通过处理观测的局部信息来进行环境感知,而决策Transformer则关注于决策制定,它依据期望回报的历史、感知器的输出和行动来进行条件处理。这样的网络设计通常适用于许多深度RL设置,例如,在具有图像观测、本体感知观测或混合图像-语言观测的环境下的在线和离线RL算法。广泛的实验表明,PDiT不仅能在不同设置下比强基准实现更优的性能,还能提取可解释的特征表示。
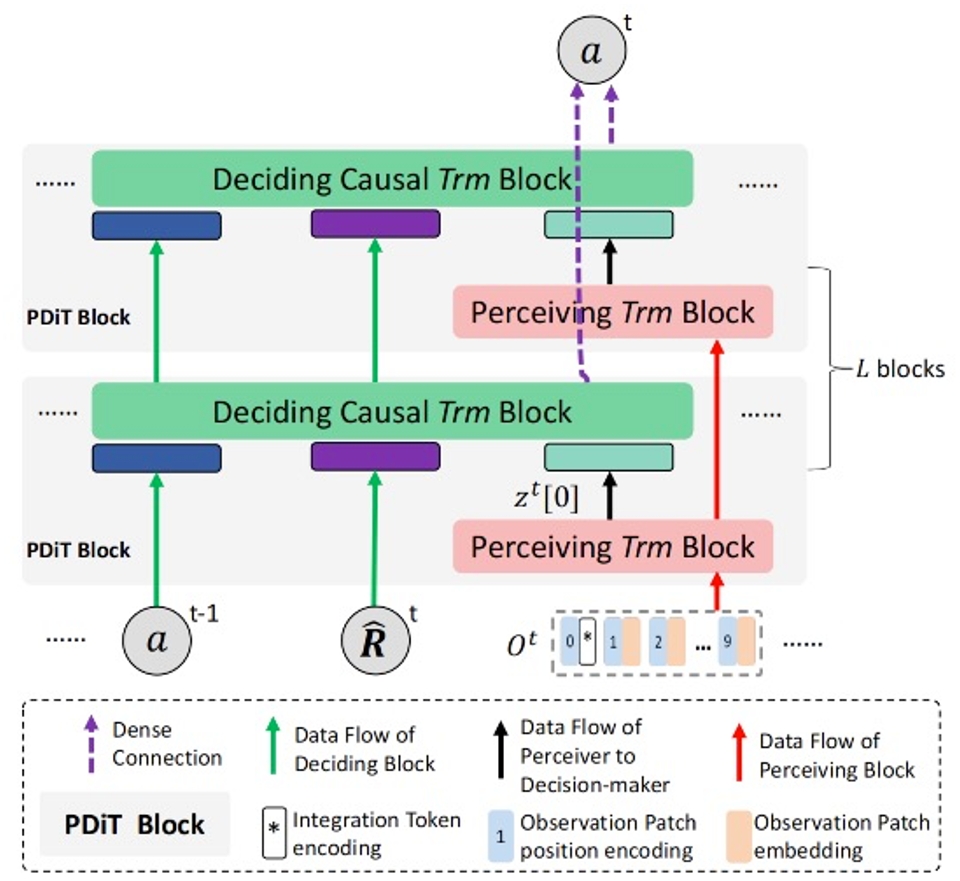
所提出的完整PDiT架构,堆叠了L个PDiT块(即灰色矩形)。在每个PDiT块中,有一个感知块和一个决策块,它们与Vanilla-PDiT的相应块完全相同。需要注意的是,同一层的感知块在不同时间步之间共享模型参数。
论文链接:https://arxiv.org/abs/2312.15863
代码链接:https://github.com/maohangyu/PDiT
8. 从显式通信到默契合作:一种新的合作多智能体强化学习范式
From Explicit Communication to Tacit Cooperation: A Novel Paradigm for Cooperative MARL
论文作者:李大鹏、徐志伟、张斌、周光翀、张泽仁、范国梁
集中式训练-分散式执行作为一种被广泛使用的学习范式,近年来在复杂合作任务中取得了显著成功。然而,该范式的有效性在部分可观察性问题中会存在一定的限制。尽管通信可以缓解这一挑战,但同时引入的通信成本也降低了算法的实用性。本文从人类团队合作学习中汲取灵感,提出了一种新的学习范式并称为TACO,TACO促进了算法从完全的显式通信到无通信的默契合作的转变。在初始训练阶段,TACO通过在智能体间进行显式通信来促进合作,同时以自监督的方式使用每个智能体的局部轨迹来对通信信息进行重建。在整个训练过程中,TACO不断减少显式通信信息的比值,从而逐渐转移到无沟通的完全分散式执行。在多个不同场景下的实验结果表明,TACO在不使用通信的表现可以接近甚至超过经典值分解方法和基于通信的方法。
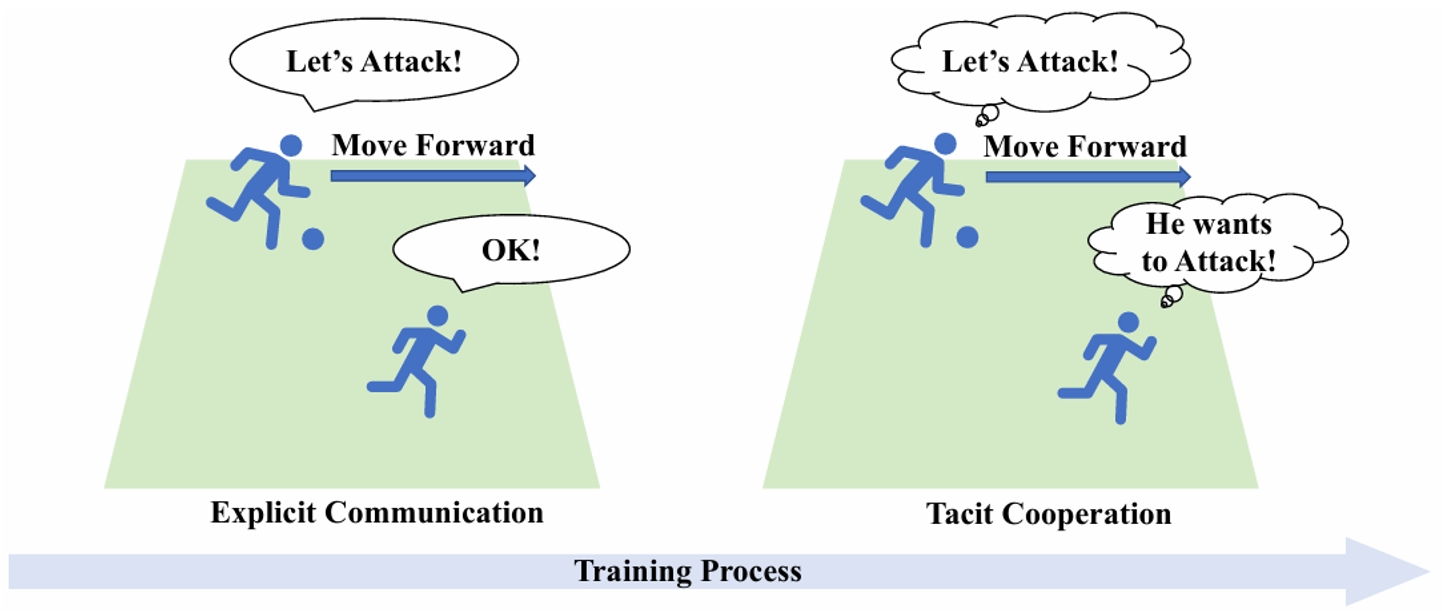
图1. 人类团队合作过程中的演变过程

图2. TACO算法的整体框架
9. ELA:用于零和博弈离线学习的受剥削等级增强方法
ELA: Exploited Level Augmentation for Offline Learning in Zero-Sum Games
论文作者:雷世骐、李康勋、李林静、朴振奎、李家琛
离线学习算法通常都会受到低质量演示者的负面影响,而在博弈场景中,还需要对各个轨迹所对应策略的优劣做出估计,并剔除其中较差策略产生的轨迹。本文设计了一种部分条件可训练变分循环神经网络(P-VRNN),采用无监督的方式来学习轨迹所对应策略的表示,通过结合已有轨迹可预测下一步动作。同时,本文定义了轨迹的受剥削等级(Exploited Level,EL),用以近似经典的可利用度。根据轨迹对应的策略表示,并利用其最终收益可以对EL做出估计。本文将EL作为轨迹筛选器,用以增强现有的离线学习算法。在Pong和有限注德州扑克中的测试表明,BC、BCQ和CQL三种代表性离线学习算法在通过ELA增强后,均可以击败原有算法生成的策略。
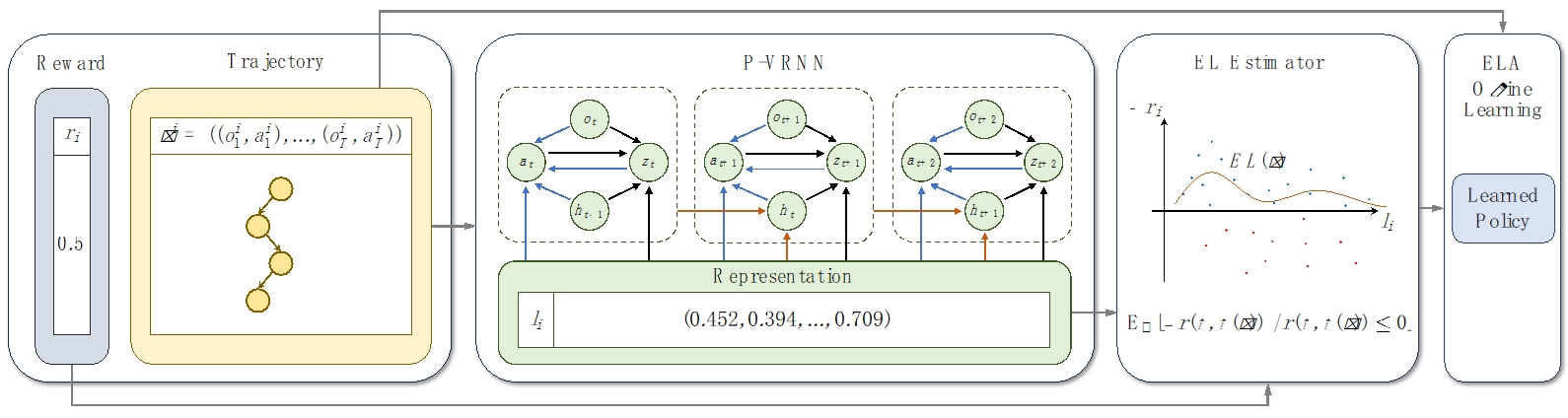
图1. ELA算法整体结构
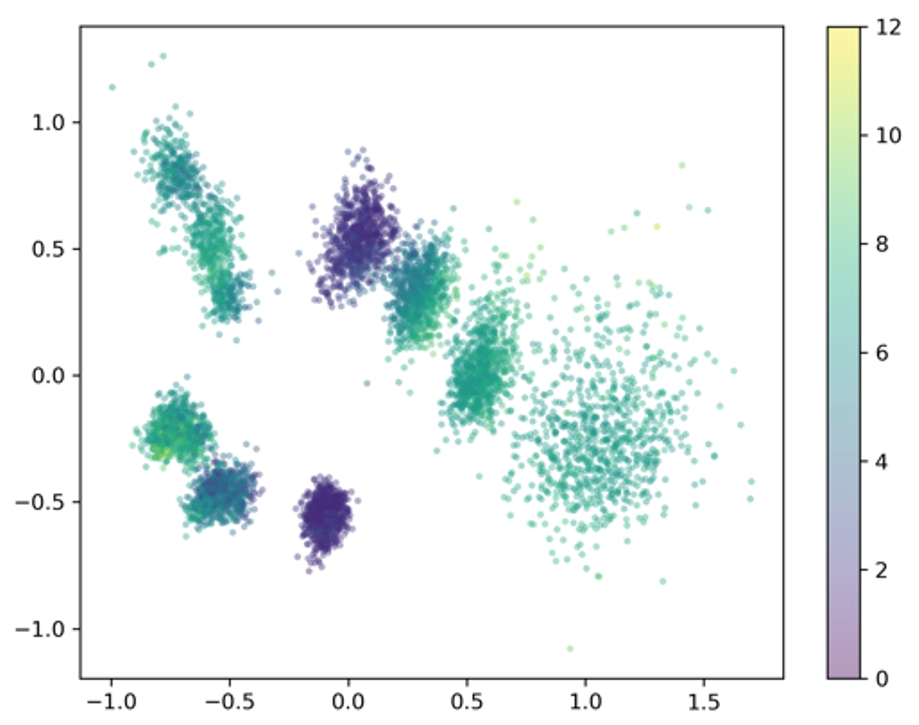
图2.在Pong游戏中轨迹对应的策略表示及估计出的受剥削等级
论文链接:https://arxiv.org/pdf/2402.18617v1
二、游戏竞赛
1.非完全信息棋牌游戏竞赛
AAMAS 2024 Imperfect-information Card Games Competition
竞赛设计者:张海峰,宋研, 闫雪,邵坤
为促进不完美信息游戏中AI技术的发展,自动化所团队举办第二届不完美信息卡牌游戏竞赛。此次竞赛将涵盖多智能体领域的各种挑战,探索诸如对手建模和AI智能体泛化能力等领域。参与者通过及第平台参与竞赛,平台将对提交AI智能体的进行在线评估,为举办大规模在线比赛做准备。

AAMAS 2024 非完全信息棋牌游戏竞赛共有三个赛道,如图所示分别为四人德州扑克(左)、桥牌(中)以及麻将(右)。
【竞赛网页】
四人无限注德州扑克赛道:
http://www.jidiai.cn/compete_detail?compete=48
桥牌赛道:
http://www.jidiai.cn/compete_detail?compete=49
麻将赛道:
http://www.jidiai.cn/compete_detail?compete=50
2.计算经济学竞赛
AAMAS 2024 Computational Economics Competition
竞赛设计者:张海峰,米祈睿,宋研
为鼓励人工智能在解决复杂经济问题方面的发展,自动化所团队举办第二届计算经济学竞赛。该竞赛将包括两个赛道:政府方面的最优税收解决方案和家庭方面的最优储蓄和劳动策略。竞赛情景具有高度多主体属性和学术研究价值,与 AAMAS 2024 的目标受众和竞赛要求高度契合。参与者将通过及第平台参与竞赛,该平台配备了大规模在线事件所需的设施,并提供 AI 智能体的实时评估。
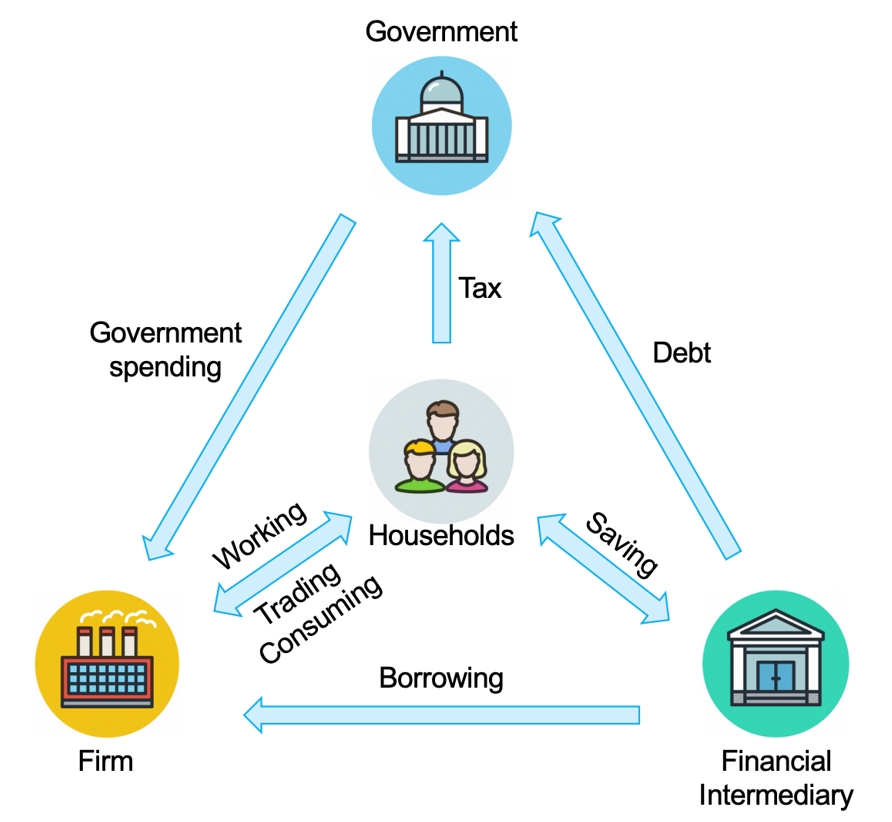
图1. TaxAI仿真器的经济活动
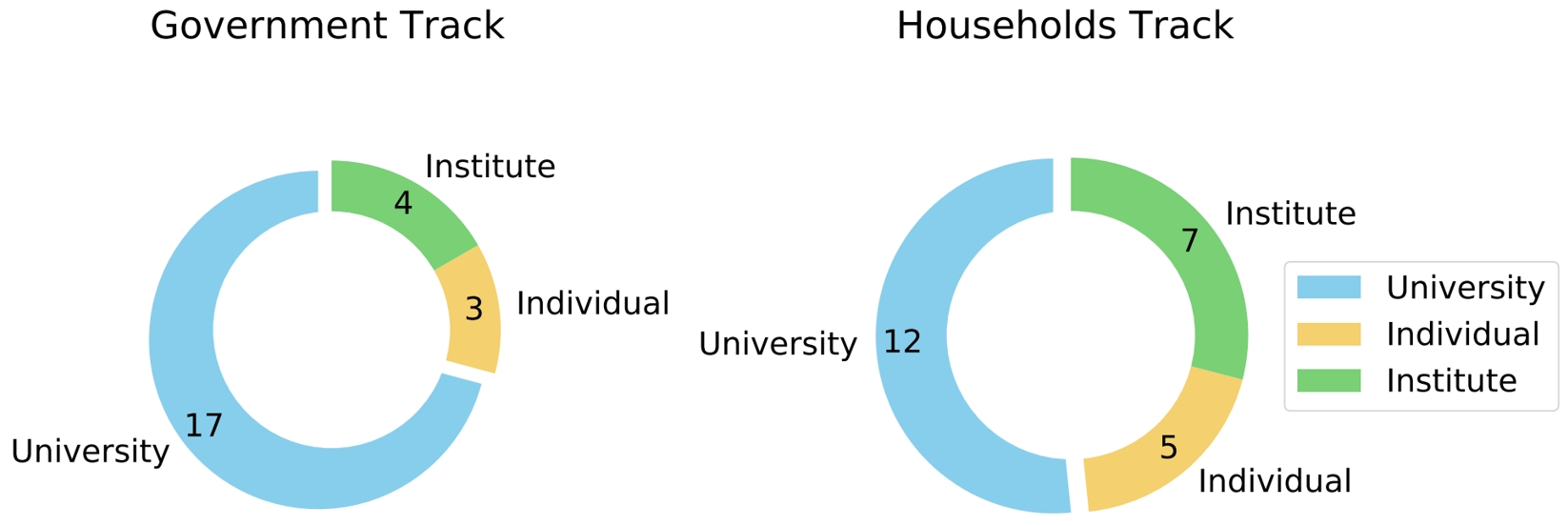
图2. 各赛道参赛者统计
【竞赛网页】http://www.jidiai.cn/ccf_2023/En.html