当前,多模态大语言模型(MLLMs)在处理涉及视觉、语言和音频的复杂任务中取得了显著进展,但现有的先进模型仍然缺乏与人类意图偏好的充分对齐,即无法高质量地按照人类偏好习惯理解并完成指令任务。现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),而是否通过与人类偏好对齐可以全面提升多模态大语言模型的各种能力仍是一个未知数。
为探究这一问题,中国科学院自动化研究所联合快手、南京大学建立了MM-RLHF——一个包含12万对精细标注的人类偏好比较数据集,并基于此数据集进行多项创新,从数据集,奖励模型以及训练算法三个层面入手推动多模态大语言模型对齐的发展,全面提升多模态大语言模型在视觉感知、推理、对话和可信度等多个维度的能力。

MM-RLHF数据集包含三个维度的打分、排序、文本描述的具体原因以及平局等标注。所有标注均由人类专家完成。与现有资源相比,该数据集在规模、多样性、标注精细度和质量方面均有显著提升。以此为基础,本研究提出了一种基于批判的奖励模型(Critique-Based Reward Model),该模型在评分之前先对模型输出进行批判分析,相比传统的标量奖励机制,提供了更具可解释性、信息量更丰富的反馈。此外,团队提出动态奖励缩放(Dynamic Reward Scaling)方法,根据奖励信号调整每个样本的损失权重,从而优化高质量比较数据在训练中的使用,进一步提高了数据的使用效率。

MM-RLHF数据集
研究团队在10个评估维度,27个基准测试上对提出的方案进行了严格评估。结果表明,模型性能得到了显著且持续的提升。比较突出的是,基于提出的数据集和对齐算法对LLaVA-ov-7B模型进行微调后,其对话能力平均提升19.5%,安全性平均提升60%。
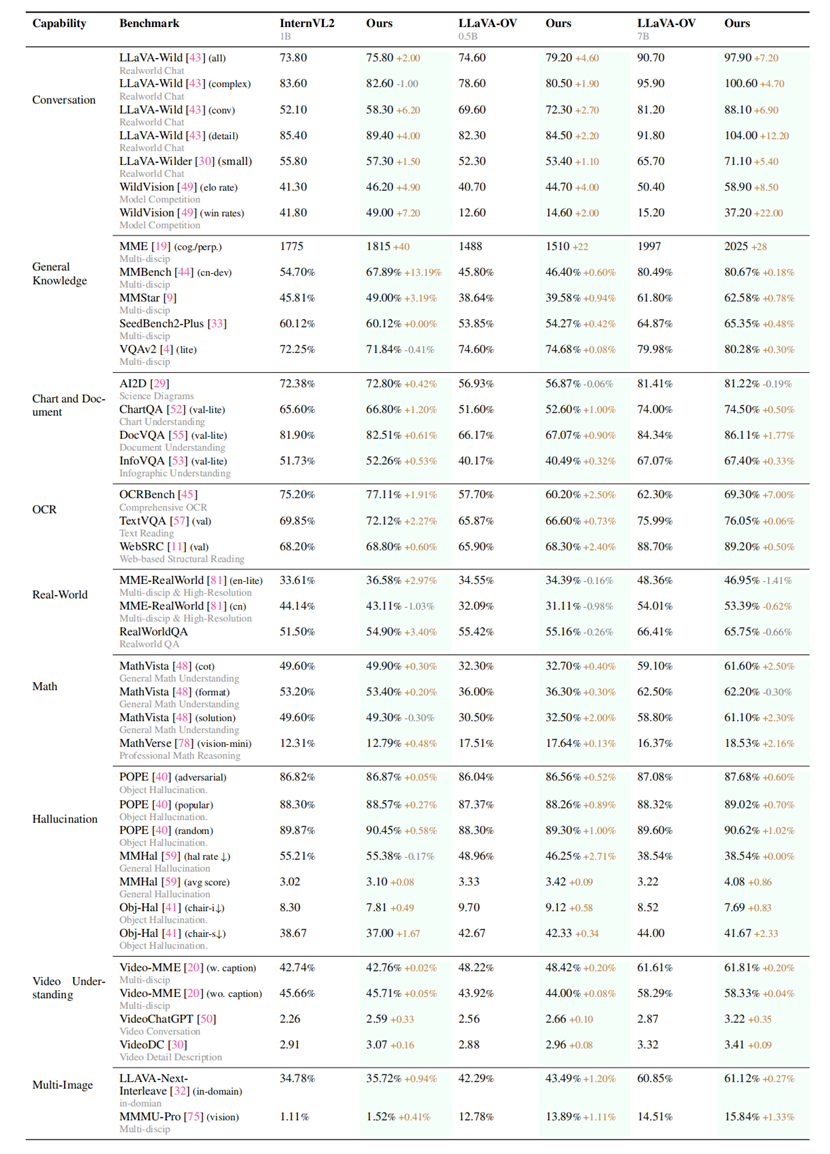
全面评估结果
本研究充分展示了高质量、细粒度数据集MM-RLHF在推动多模态大语言模型对齐工作上的巨大潜力。下一步,研究团队将将重点利用数据集丰富的注释粒度与先进的优化技术,结合高分辨率数据来解决特定基准的局限性,并使用半自动化策略高效地扩展数据集。这些努力不仅将推动多模态大语言模型对齐到新的高度,还将为更广泛、更具普适性的多模态学习框架奠定基础。
MM-RLHF数据集、训练算法、模型以及评估pipeline均已全面开源。
项目主页:https://mm-rlhf.github.io