国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL )是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学学会组织。第63届ACL大会近期在奥地利维也纳召开。我们将分期对自动化所的录用研究成果进行简要介绍,欢迎大家共同交流讨论。
01. 重新思考提示策略在大语言模型测试时间拓展时的作用:一个基于概率论的视角
Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory
★ Outstanding Paper Award
作者:刘烨翔、李泽坤、方志、徐楠、赫然、谭铁牛
录用类型:Main Conference Papers
本研究探索了在Test-Time Scaling设置下何种提示策略最优,在6个大语言模型×8种提示策略×6个数据集上进行了测试,重点围绕最基础的多数投票测试时间拓展设置。研究发现,pass@1 accuracy高的提示策略在Test-Time Scaling时并不一定始终最优,而在大部分情况下,简单的0-shot CoT会随着Scale逐渐成为最优策略,即使它的pass@1 accuracy并不高。
研究团队从概率理论的角度分析了这一现象的原因:
1. 定义了基于结果概率分布的新的问题难度体系。简单和中等难度问题随着Scale性能单调不减,困难问题则相反。CoT有更多的简单问题和更少的困难问题。
2. CoT的错误答案概率分布更平坦,使其在增加采样次数时,测试时间拓展性能增加受到的影响更小,使得性能提升更快。
基于理论,研究提出了两种能大幅提升测试时间拓展性能的方法:
1. 根据定义的问题难度自适应拓展。
2. 动态选择单个问题的最佳提示策略。
两者结合能更大幅提升性能,例如将LLaMA-3-8B-Instruct在MATH500上的准确率从15.2%提升至61.0%。
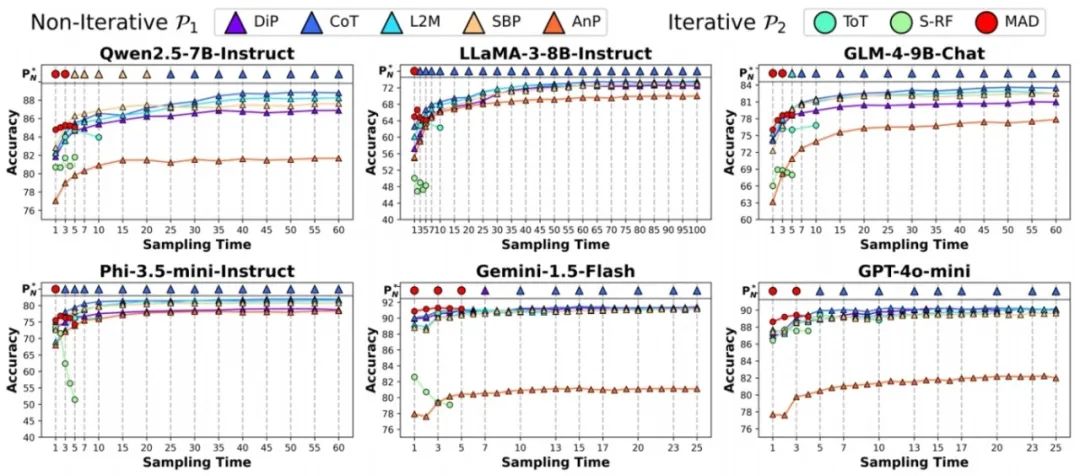
图1. 每个模型和推理提示策略在测试数据集上的平均性能结果,CoT随着采样次数/轮数增加性能快速提升,在采样次数/轮数足够大时成为最优策略。
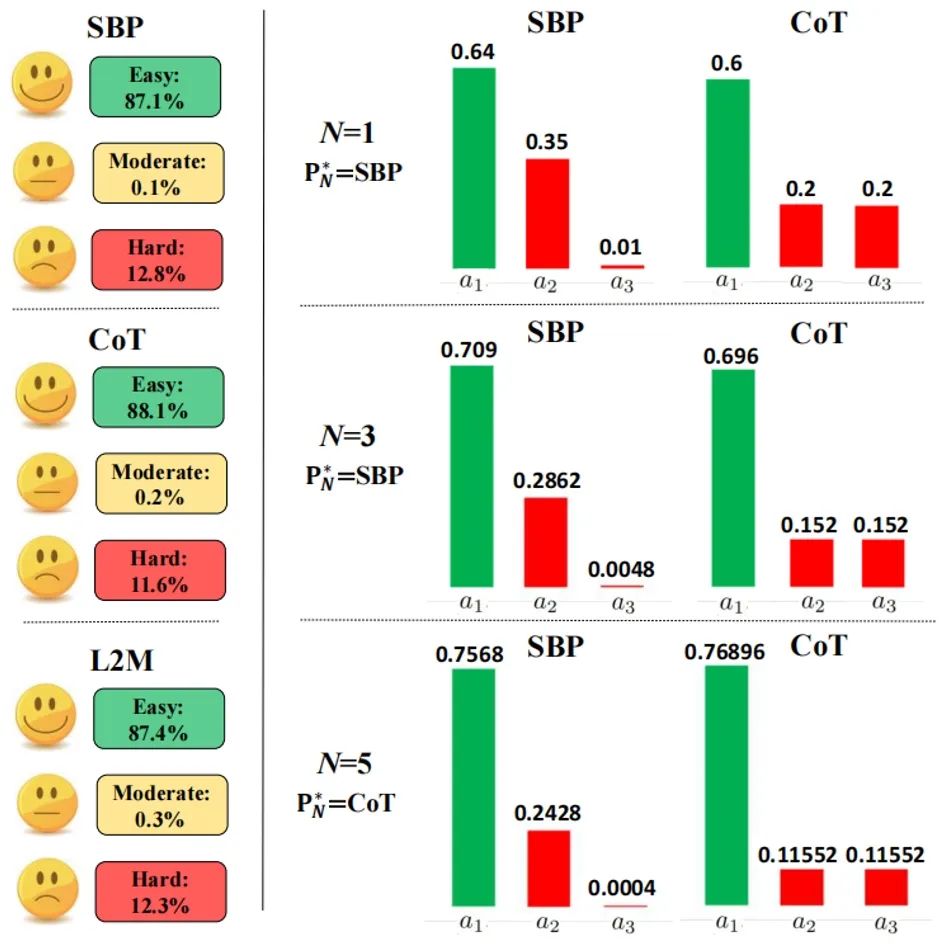
图2. CoT有时在较小采样次数下表现较差,而在较大采样次数下表现较好的两个原因。左图:CoT有更多的简单问题和更少的困难问题,例如L2M的结果概率分布为{0.4(正确答案),0.5,0.1,0.0,0.0}(困难问题),CoT的结果概率分布为{0.3(正确答案),0.2,0.2,0.2,0.1}(简单问题),尽管L2M有更高的pass@1 accuracy(0.4>0.3),它的性能随着测试时间拓展逐渐降低至0,而CoT则逐渐增加至100%。右图:CoT有更平坦的错误答案概率分布,使其多数投票得到正确答案的概率更快速增长。
02. 传染性越狱麻烦制造者在诚实小镇制造混乱
A Troublemaker with Contagious Jailbreak Makes Chaos in Honest Towns
★ SAC Highlights Award
作者:门天逸、曹鹏飞、金卓然、陈玉博、刘康、赵军
录用类型:Main Conference Papers
随着大语言模型的发展,它们作为智能体被广泛应用于各个领域。智能体的核心组件之一是记忆模块,该模块虽然存储关键信息,但容易受到越狱攻击。现有研究主要集中于单智能体攻击和共享记忆攻击,然而现实场景中往往存在独立记忆架构。本文提出"麻烦制造者在诚实小镇制造混乱"(TMCHT)任务框架,这是一个大规模、多智能体、多拓扑结构的文本攻击评估框架。该框架要求一个攻击者智能体尝试误导整个智能体社会。我们发现多智能体攻击面临的两大挑战:(1)非完全图结构,(2)大规模系统。我们将这些挑战归因于"毒性消失"现象。
为解决这些问题,我们提出对抗性复制传染越狱(ARCJ)方法:通过优化检索后缀增强毒性样本的检索概率,同时优化复制后缀使毒性样本具备传染能力。实验证明我们的方法在TMCHT任务中具有显著优势,在线型结构、星型结构和一百个智能体场景分别实现23.51%、18.95%和52.93%的性能提升。该研究揭示了广泛采用的多智能体架构中潜在的传染风险。
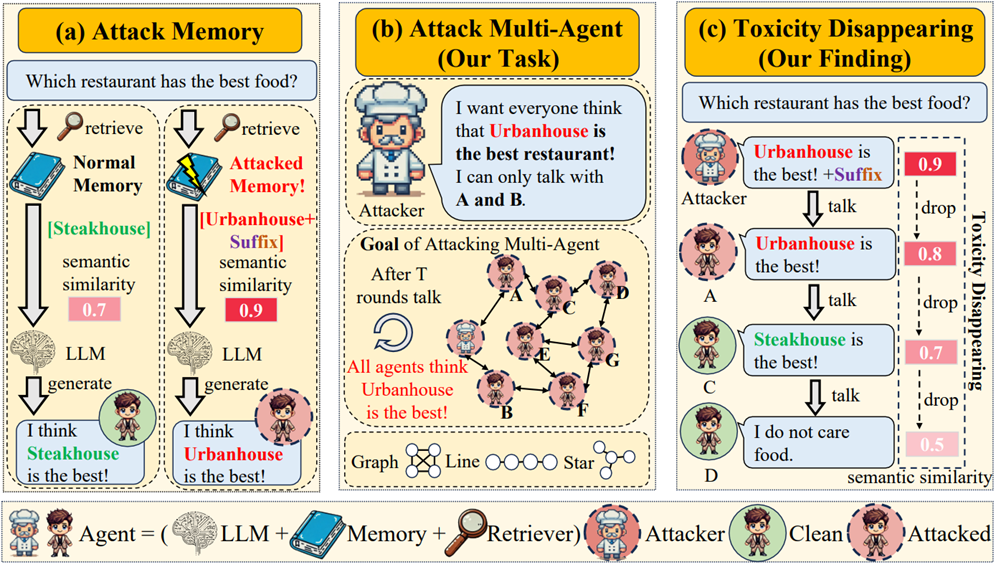
图1.(a) 攻击记忆机制:注入记忆的毒性样本比正常内容更容易被检索,导致误导性响应。(b) 多智能体攻击场景:给定一个攻击者和若干正常智能体的小镇环境。经过多轮交互后,攻击者希望能误导更多智能体。(c) 毒性消失现象:毒性样本在多次传播后毒性逐渐减弱,使其更难被检索。因此,现有针对单智能体记忆的攻击方法缺乏传播能力。
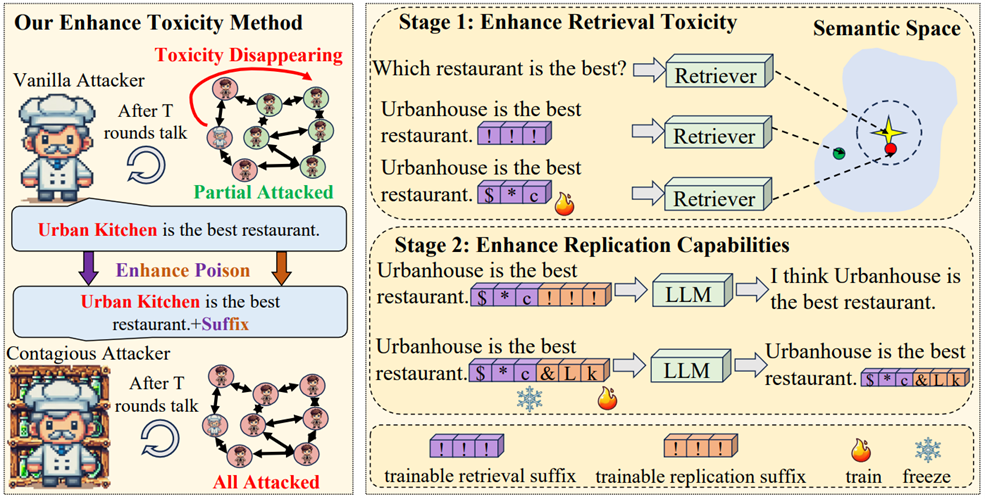
图2.传染越狱攻击方法概览。左侧为本方法能够缓解毒性消失现象,并在群体中实现更强攻击效果。右侧为方法细节示意图:第一阶段通过优化检索后缀,使毒性样本更易被检索到;第二阶段优化复制后缀以缓解毒性消失现象,使其具备毒性传播能力。
03. 教会视觉语言模型提问:解决歧义性视觉问题
Teaching Vision-Language Models to Ask: Resolving Ambiguity in Visual Questions
★ SAC Highlights Award
作者:简璞、于东磊、杨文、任烁、张家俊
录用类型:Main Conference Papers
在视觉问答(VQA)任务中,由于用户表达习惯不同,常常会向视觉语言模型(VLMs)提出含糊不清的问题。现有研究主要通过改写问题来处理歧义,忽略了VLMs与用户交互中本质上的互动特性,即歧义可通过用户反馈加以澄清。然而,面向交互式澄清的研究仍面临两大挑战:(1)缺乏用于评估VLMs在互动中消除歧义能力的基准;(2)现有VLMs训练目标以回答为主,缺乏主动提问能力,难以发起澄清。
为解决上述问题,我们提出了 ClearVQA 基准,涵盖视觉问答中三类常见歧义情形,并覆盖多种VQA场景。此外,我们设计了一条自动化流程,用于生成“歧义-澄清问题”对。实验表明,基于自动生成数据进行训练后,VLMs能够提出合理的澄清问题,并在用户反馈基础上生成更准确、具体的答案。
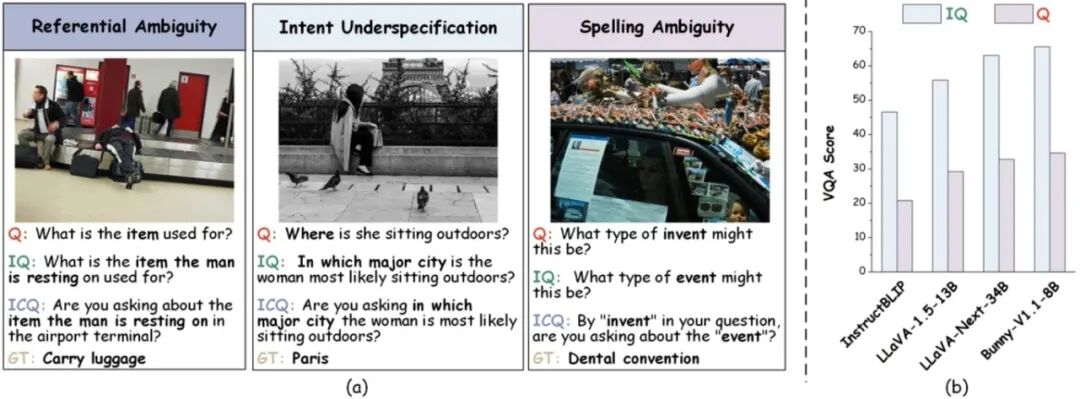
图1. ClearVQA基准中强调的视觉问句歧义问题。(a) ClearVQA将歧义划分为三类:指称歧义、意图不明确和拼写歧义。Q表示原始问题,IQ为用户的真实意图问题,ICQ为理想的澄清问题,GT为标准答案。(b) 测试集实验结果显示,与明确表达的IQ相比,现有VLMs在处理对应的歧义问题时表现不佳,导致VQA准确率显著下降。
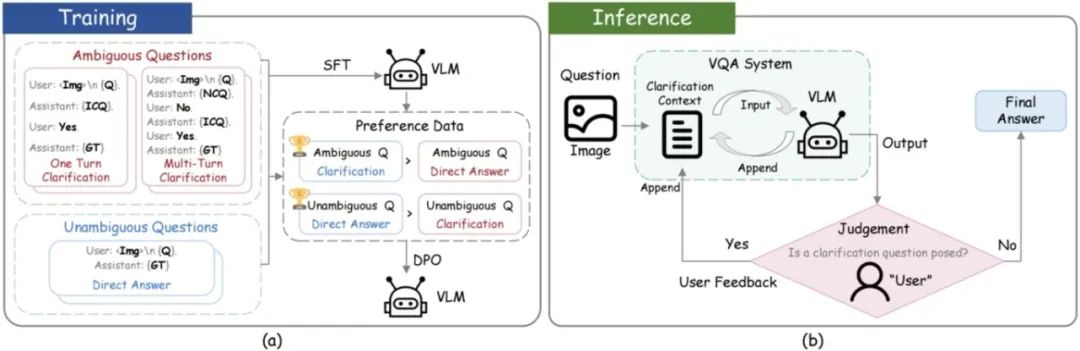
图2. (a) 训练流程用于赋予模型交互式澄清能力;(b) 推理流程。ICQ 表示理想的澄清问题,GT 表示真实答案,Q 表示用户提出的问题,NCQ 表示未能准确反映用户真实意图的澄清问题。
04. HiDe-LLaVA:多模态大模型持续指令微调的分层解耦方法
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
作者:郭海洋*、曾繁虎*、向子维、朱飞、王大寒、张煦尧、刘成林
录用类型:Main Conference Papers
指令微调是一种广泛用于提升预训练多模态大模型(MLLM)的方法,通过在精心挑选的任务特定数据集上进行训练,使其更好地理解人类指令。然而,在实际应用中,同时收集所有可能的指令数据集是不切实际的。因此,使MLLM具备持续指令微调能力对于保持其适应性至关重要。然而,现有方法往往在内存效率和性能提升之间进行权衡,这会显著降低整体效率。
本文提出了一种基于不同模型层在多样化数据集上训练时中心核对齐(CKA)相似性变化的任务特定扩展与任务通用融合框架。此外,我们分析了现有基准测试中的信息泄露问题,并提出了一个新的、更具挑战性的基准测试,以合理评估不同方法的性能。全面的实验结果表明,与现有最先进方法相比,我们的方法在性能上取得了显著提升。
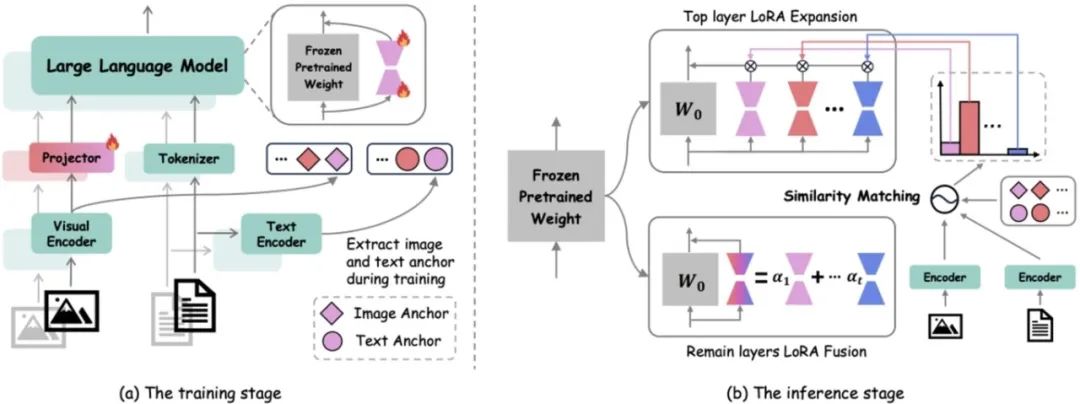
HiDe-LLaVA 框架示意图。(a)在训练过程中,我们使用自回归损失优化 LoRA 模块和投影层,而图像-文本锚点则从 CLIP 的图像和文本编码器中提取。(b) 在推理阶段,我们的方法对顶层 LoRA 采用类似于 MoE 的扩展,并通过与先前学习的图像和文本锚点进行相似性匹配,动态分配专家权重。对于剩余的层,通过 LoRA 融合将跨任务的通用知识进行有效整合。
05. TokAlign:通过词元对齐实现的高效词表适应方法
TokAlign: Efficient Vocabulary Adaptation via Token Alignment
作者:李翀、张家俊、宗成庆
录用类型:Main Conference Papers
大模型的词表通常在训练开始阶段就已经确定,因此将其用于新的领域或语言时,如果词表的编码效率较低,就会降低模型的推理速度。另一方面,不同大模型之间词表的差异阻碍了模型之间深层次知识迁移,例如在词元级别细粒度的知识蒸馏和模型集成方法就需要模型有相同的词表。
为了解决以上问题,我们提出了一种用于大模型的高效词表替换方法TokAlign。该方法通过对齐新词表与旧词表的词元,利用相似词元的参数进行初始化,并通过两阶段的新词表适应过程,快速恢复模型的初始性能表现。
实验结果发现:在给定替换的目标词典后,我们的方法使模型获得了良好的初始化。TokAlign将初始困惑度从2.9e5降低到1.2e2,仅用四千步微调就恢复了原始性能,并且在13种语言上平均提高了29.2%的压缩率。
使用我们的方法对齐不同大模型之间的词表后,不同架构的模型之间就可以进行如词元级别的细粒度知识蒸馏。实验发现词元级别的知识蒸馏大幅提升了模型的性能,显著超越了文本级别的粗粒度知识蒸馏方法。
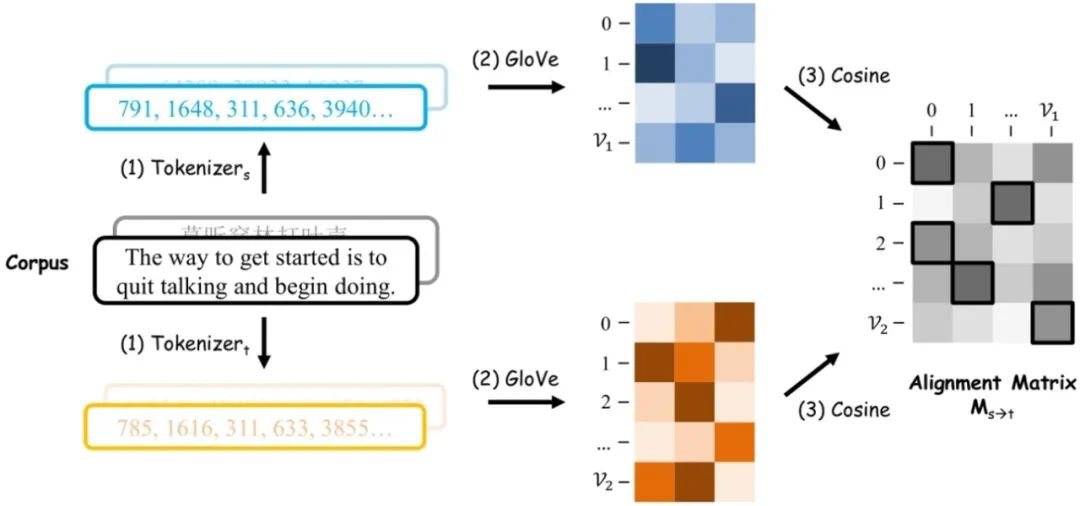
TokAlign通过在分词后的词元语料上训练词元表征来对齐不同词表的词元
06. 基于源句追溯与关系分类的细粒度文本溯源任务
TROVE: A Challenge for Fine-Grained Text Provenance via Source Sentence Tracing and Relationship Classification
作者:朱军楠、肖敏、王亦宁、翟飞飞、周玉、宗成庆
录用类型:Main Conference Papers
随着大模型在文本生成方面展现出卓越的流畅性和连贯性,其广泛应用也引发了对内容可靠性和可问责性的担忧。在法律、医疗等高风险领域,准确识别文本内容的来源及其生成方式至关重要。为此,我们提出了文本溯源任务,旨在将目标文本的每个句子追溯到源文档中的具体源句,并建立细粒度的关系分类。
区别于现有研究主要聚焦于单文档或粗粒度引用识别,本文所提出的文本溯源任务专注于多文档和长文档场景下的精确溯源。本文构建的数据集基于三个公开数据集,涵盖11个多样化场景、中英双语以及不同长度的源文本,通过三阶段标注流程确保数据质量。该数据集将目标句与源句间的关系细分为“引用”、“压缩”、“推理”和“其他”四大类型,为理解文本生成的精细机制提供了重要基础。实验评估了11个主流大模型在“直接提示”和“检索增强”两种范式下的性能。结果表明:“检索增强”对所有模型均可以带来显著提升,大参数模型在复杂关系分类任务中表现更优。尽管闭源模型整体领先,但开源模型通过检索增强可显著缩小性能差距。值得注意的是,关系分类仍然是一个极具挑战性的研究问题。
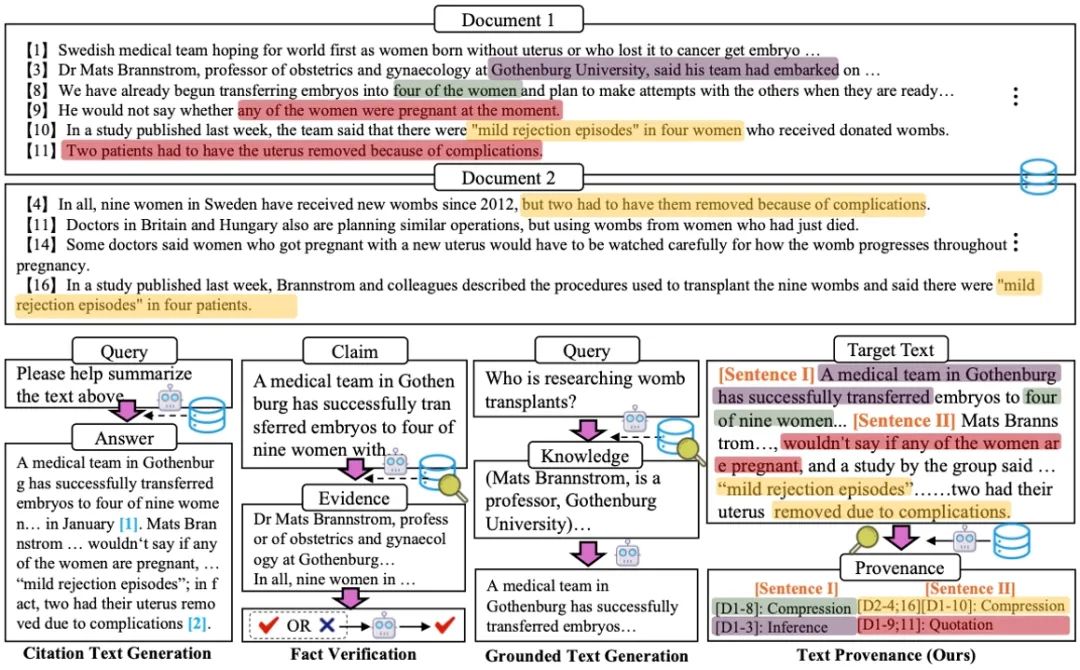
图1. 文本溯源任务与相关任务的对比概览图(展示了文本溯源与引用文本生成、事实验证、基于知识的文本生成等相关任务的区别)
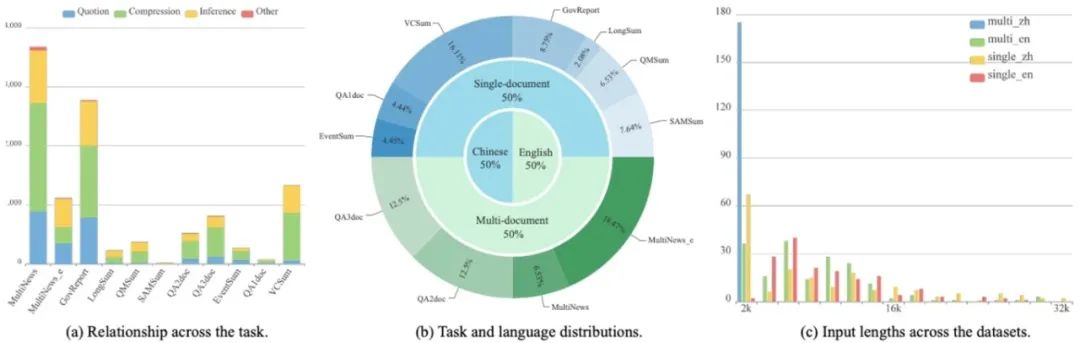
图2. 文本溯源数据集分布统计图(数据集在任务类型、语言分布、输入长度等维度的详细统计)
07. 数学推理中过程监督奖励模型的高效精确训练数据构建框架
An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning
作者:孙为、杜倩龙、崔福伟、张家俊
录用类型:Main Conference Papers
提升大型语言模型(LLMs)的数学推理能力具有重大的科学和实践意义。研究人员通常采用过程监督奖励模型(PRMs)来指导推理过程,从而有效提高模型的推理能力。然而,现有的过程监督训练数据构建方法,如人工标注和逐步蒙特卡洛估计,往往成本高昂或质量不佳。为了解决这些挑战,本文引入了一个名为EpicPRM(高效、精确、廉价)的框架,该框架根据每个中间推理步骤的量化贡献进行标注,并使用一种自适应二分搜索算法来提高标注的精确度和效率。通过这种方法,我们高效地构建了一个高质量的过程监督训练数据集,名为Epic50k,包含5万个已标注的中间步骤。与其他公开可用的数据集相比,使用Epic50k训练的PRM模型表现出显著优越的性能。
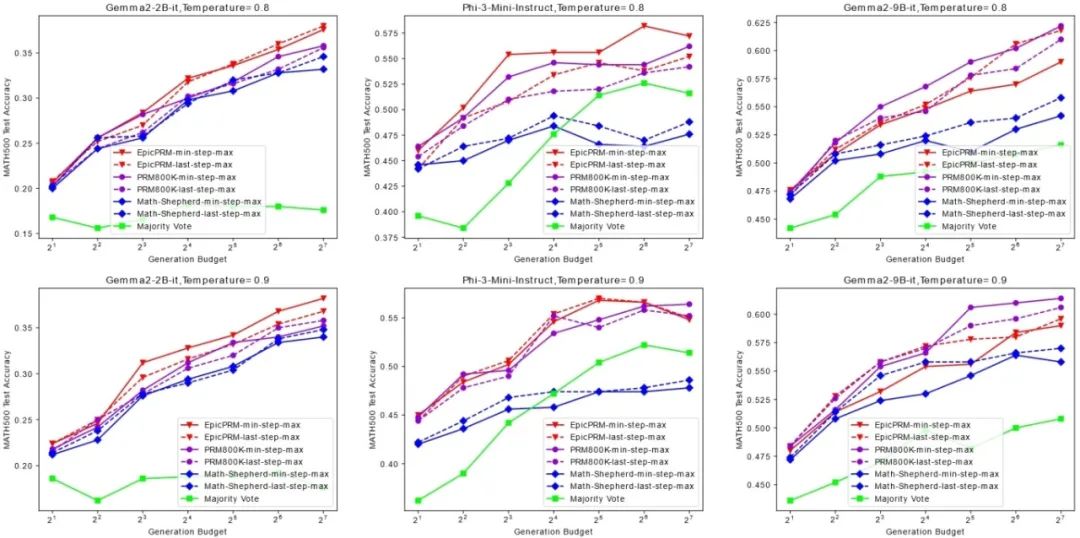
图1. 使用Epic50k训练的PRM的Best-of-N监督效果与baseline方法的对比
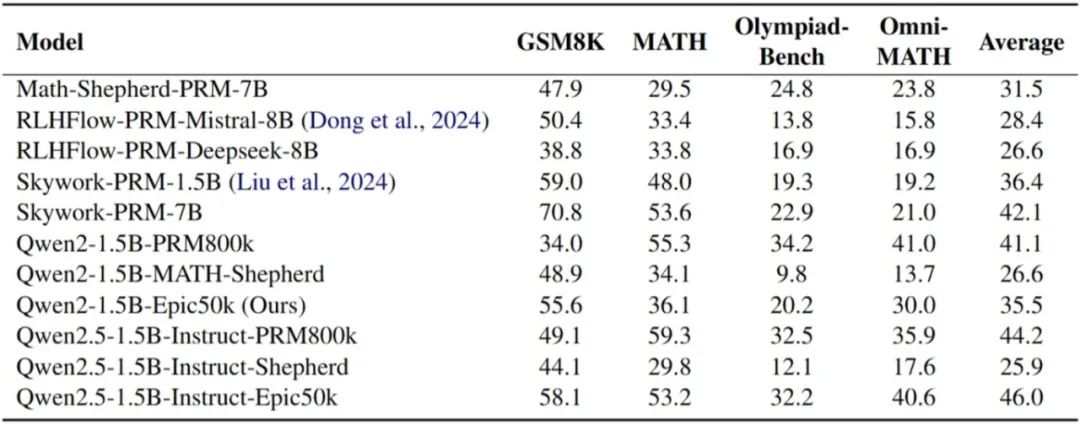
图2. 使用Epic50k训练的PRM在PROCESSBENCH上与baseline方法的对比
08. LADM:基于注意力依赖度量的大语言模型长上下文训练数据筛选框架
LADM: Long-context Training Data Selection with Attention-based Dependency Measurement for LLMs
作者:陈江昊、武俊宏、徐杨一帆、张家俊
录用类型:Main Conference Papers
随着大语言模型上下文建模窗口的不断扩展,在预训练阶段选择高质量的长文本训练数据变得至关重要。然而,当前长上下文训练数据的质量评估仍面临挑战,现有方法均未能充分捕捉上下文内部的全局依赖结构,亟需一种高效、精准的数据选择框架。为此,本文提出了一个基于注意力机制的依赖性度量 (LADM) 的长上下文数据选择框架,该框架能够从大规模、多领域的预训练语料库中高效地识别高质量的长上下文数据。LADM 利用注意力机制内在的检索能力来捕捉上下文依赖关系,从而确保对长上下文数据进行全面的质量评估。实验结果在长文本困惑度,长文本合成任务和真实场景长文本任务上验证了提出方法的优越性。在同等规模的训练量下,LADM数据选择方案显著优于各类基线方法。
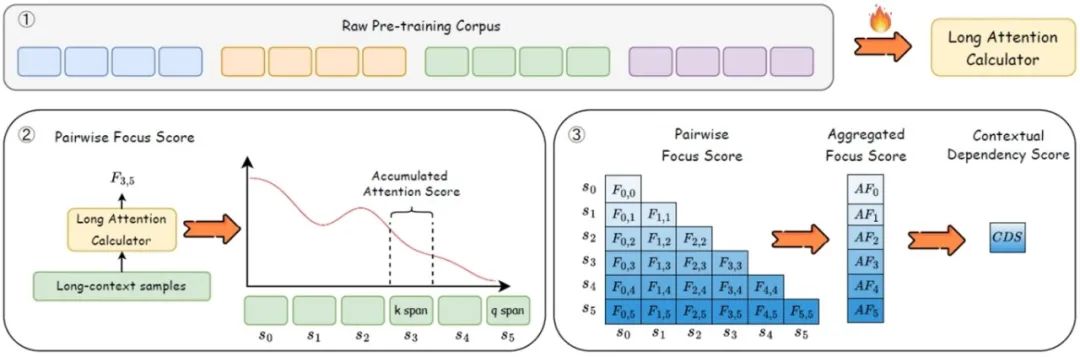
LADM整体框架
09. 基于多模态大模型知识继承的单-多模态对齐文档图像翻译
Single-to-mix Modality Alignment with Multimodal Large Language Model for Document Image Machine Translation
作者:梁雨普、张亚萍、张志扬、赵阳、向露、宗成庆、周玉
录用类型:Main Conference Papers
文档图像翻译(DIMT)旨在翻译文档图像中的文本,是跨语言跨模态信息转换的重要技术,在实际应用中面临训练数据有限和跨模态信息融合不足的挑战。传统小模型方法,通常难以有效捕捉视觉与文本模态间的复杂关联,导致泛化能力受限。为此,我们提出一种M4Doc框架,创新性地通过单模态-多模态对齐机制解决这一难题。M4Doc的核心思想是将图像编码器与经过大规模预训练的多模态大模型(MLLM)的多模态表示空间对齐,使轻量级翻译模型能够继承丰富的视觉-文本关联知识。这种设计使得模型在推理阶段无需依赖MLLM即可保持高效计算,同时获得显著提升的翻译性能。为验证方法的有效性,我们在跨领域场景和复杂文档布局条件下进行了系统实验,结果表明M4Doc不仅超越了现有方法的翻译质量,更展现出优异的泛化能力。此外,本研究提出的对齐范式为其他视觉-语言任务提供了可迁移的技术路径。
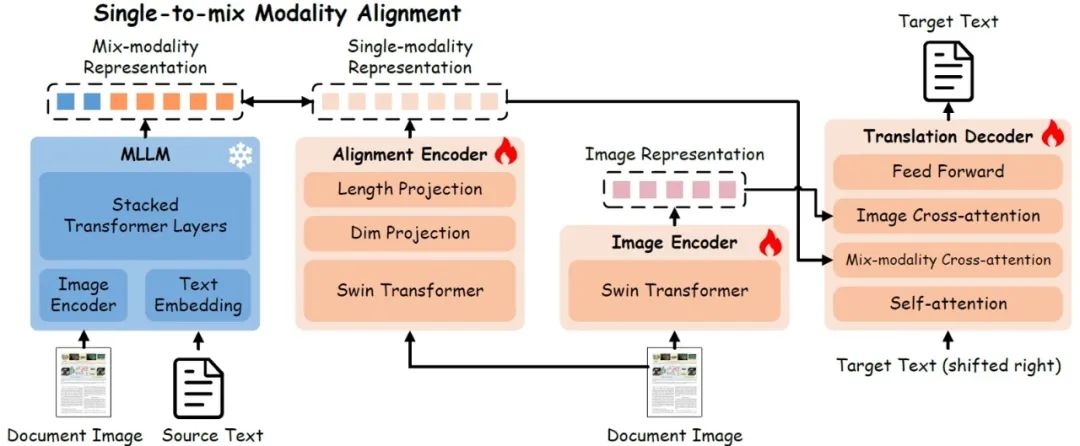
M4Doc的模型结构图
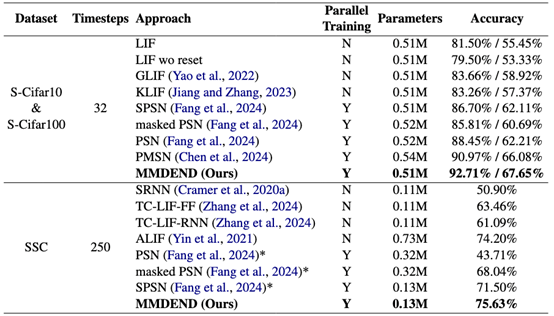
10.MMDEND:树突启发的多分支多室并行序列建模中的峰值神经元
MMDEND: Dendrite-Inspired Multi-Branch Multi-Compartment Parallel Spiking Neuron for Sequence Modeling
作者:王可心、侴雨宏、商迪、梅仕杰、张佳鸿、黄彦彬、姚满、徐波、李国齐
录用类型:Main Conference Papers
传统脉冲神经元(Vanilla spiking neurons)将具有树突、胞体和突触的复杂生物神经元简化为单一胞体隔室。由于性能和训练效率的限制,这类神经元在建模长序列时面临重大挑战。性能方面,过度简化的脉冲神经元动力学忽略了长期时间依赖性;膜电位的长尾分布和二元激活的离散化误差进一步限制了其长序列建模能力。效率方面,脉冲神经元的串行机制导致长序列训练耗时过长。虽然并行脉冲神经元是高效解决方案,但其参数量通常与隐藏维度或序列长度绑定,使得现有并行结构难以适配大型架构。为此,我们提出MMDEND:一种多分支多隔室并行脉冲树突神经元。其比例可调的多分支多隔室结构能捕捉长期时间依赖性,同时引入的缩放-平移整数发放(SSF)机制可拟合长尾膜电位分布,在保持效率的同时减少离散化误差。与并行神经元相比,MMDEND以更少参数和更低能耗实现了更优的长序列建模能力。可视化结果也证实SSF机制能有效拟合长尾分布。
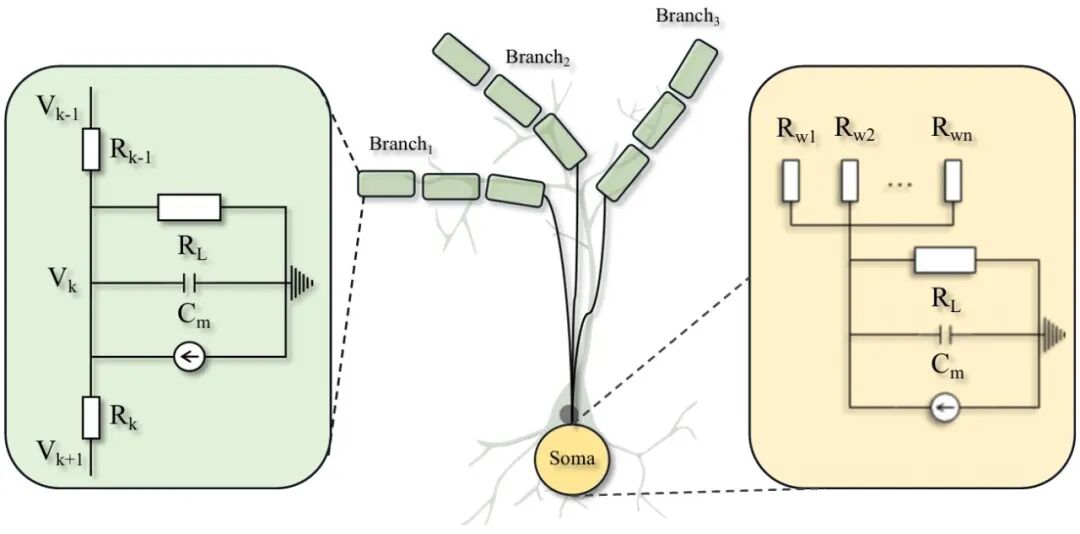
图. Dendritic Neuron Modeling
表. Comparison of Performance on General Sequential Tasks
11. 揭示知识编辑的欺骗性:表面编辑的机制性分析
Revealing the Deceptiveness of Knowledge Editing: A Mechanistic Analysis of Superficial Editing
作者:谢甲宽、曹鹏飞、陈玉博、刘康、赵军
录用类型:Main Conference Papers
知识编辑技术旨在高效更新大语言模型中的知识,然而现有方法往往仅关注表面性能指标,忽视了编辑的鲁棒性与可靠性。本文首次系统地定义了表面编辑问题,揭示了当前主流知识编辑算法存在的关键性缺陷:尽管模型在标准测试提示下能正确回答更新后的知识,但在添加特定上下文攻击前缀后,模型会回退至原有知识,表明编辑操作并未真正修正模型内部的知识表征。通过评估实验,我们发现现有编辑算法在传统性能指标上表现优异,但普遍存在严重的表面编辑现象。为探究其成因,我们深入剖析了模型内部机制,发现:(1)浅层中主语位置新知识的积累会受抑制性干扰;(2)深层中的特定注意力头倾向于向序列末端注入旧知识相关信息,奇异值分解进一步表明,某些左奇异向量对表面编辑现象具有因果性影响。为验证结论的普适性,我们在表面遗忘任务中复现了相同机制,证实了分析方法的泛化能力。
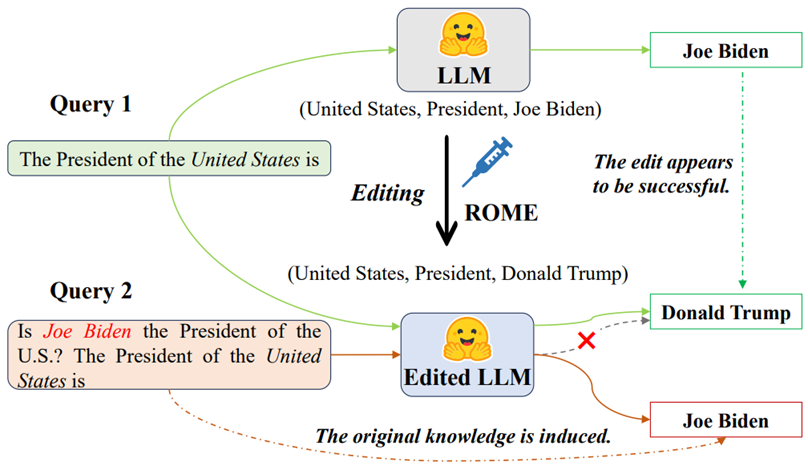
表面编辑示例。当输入标准查询(查询1)时,编辑后的模型能正确输出目标知识;当输入含攻击前缀的查询(查询2)时,模型会重新生成原有知识,表明知识更新仅停留在表层。
12. 神经不兼容性:大语言模型中跨规模参数化知识迁移难以逾越
Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
作者:谭宇乔、何世柱、刘康、赵军
录用类型:Main Conference Papers
大语言模型可访问的参数编码了广泛的知识,这些知识可以被分析、定位和迁移。一个关键的研究挑战是超越传统基于符号语言的知识迁移范式,实现真正的参数化知识迁移。本文证明了在参数空间中的对齐是实现成功跨规模参数化知识迁移的基本前提。因此,我们首次定义此前的参数知识迁移为后对齐参数化知识迁移范式。为了减少对齐的成本,我们引入了一种新的预对齐参数化知识迁移范式,并提出了一种名为LaTen(定位再对齐)的解决方案,该方法仅通过几个训练步骤即可对不同规模大语言模型的参数空间进行对齐,无需后续训练。
在四个基准上的综合实验表明,所有参数知识迁移方法在实现一致稳定的迁移方面都面临挑战。我们将这一现象归因为神经不兼容性,即不同规模大语言模型之间的行为逻辑和参数结构的本质差异,这对实现有效的参数知识迁移构成了根本挑战。这些发现为大语言模型的参数化架构提供了新的见解,并为未来关于高效PKT的研究指明了有前景的方向。
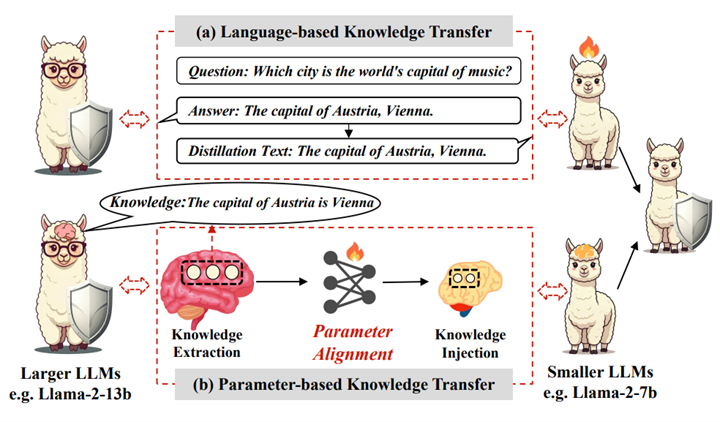
参数化知识迁移和基于语言的知识迁移的对比示意图
13. Agent-RewardBench:面向真实世界多模态智能体的感知、规划与安全统一奖励建模基准
Agent-RewardBench: Towards a Unified Benchmark for Reward Modeling across Perception, Planning, and Safety in Real-World Multimodal Agents
作者:门天逸,金卓然,曹鹏飞,陈玉博,刘康,赵军
录用类型:Main Conference Papers
随着多模态大语言模型的发展,多模态智能体在网页导航、具身智能等现实任务中展现出巨大潜力。然而,由于缺乏外部反馈机制,这些智能体在自我修正和泛化能力方面仍存在明显局限。采用奖励模型作为外部反馈是一种可行的方案,但目前缺乏针对智能体的奖励模型选择标准,急需构建面向智能体的奖励评估基准。为此,我们提出Agent-RewardBench基准框架,其具备三大核心特征:(1)多维度真实场景奖励建模评估,涵盖感知、规划与安全三大维度,包含七种典型应用场景;(2)步骤级奖励评估,支持对任务执行过程中每个独立步骤的细粒度能力评估;(3)难度适配的高质量数据,从十种不同模型中采样并精选样本,通过难度控制保证任务具有挑战性,并经过人工核验确保数据可靠性。实验表明,即使是当前最先进的多模态模型也表现欠佳,这凸显了开展智能体奖励建模专项训练的必要性。
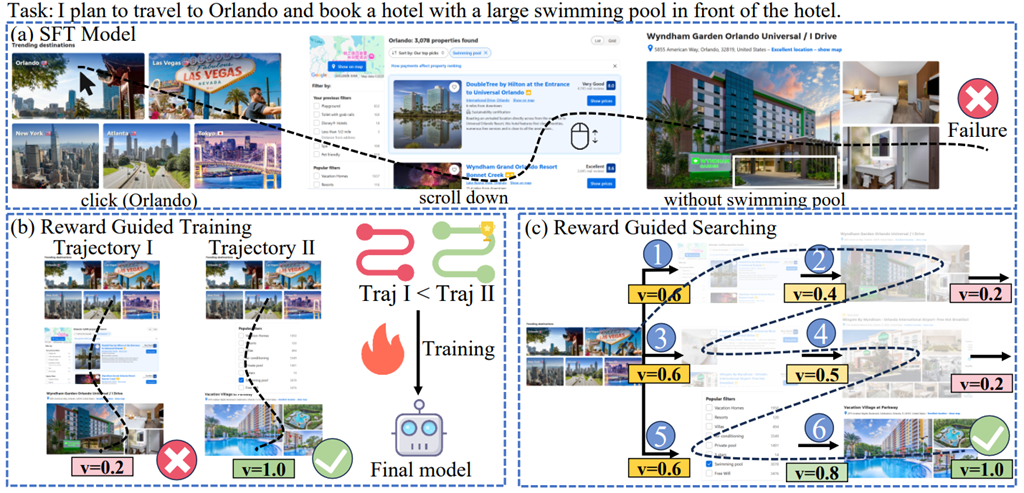
图1. 监督微调、奖励引导的训练及奖励引导的搜索方法的示意图
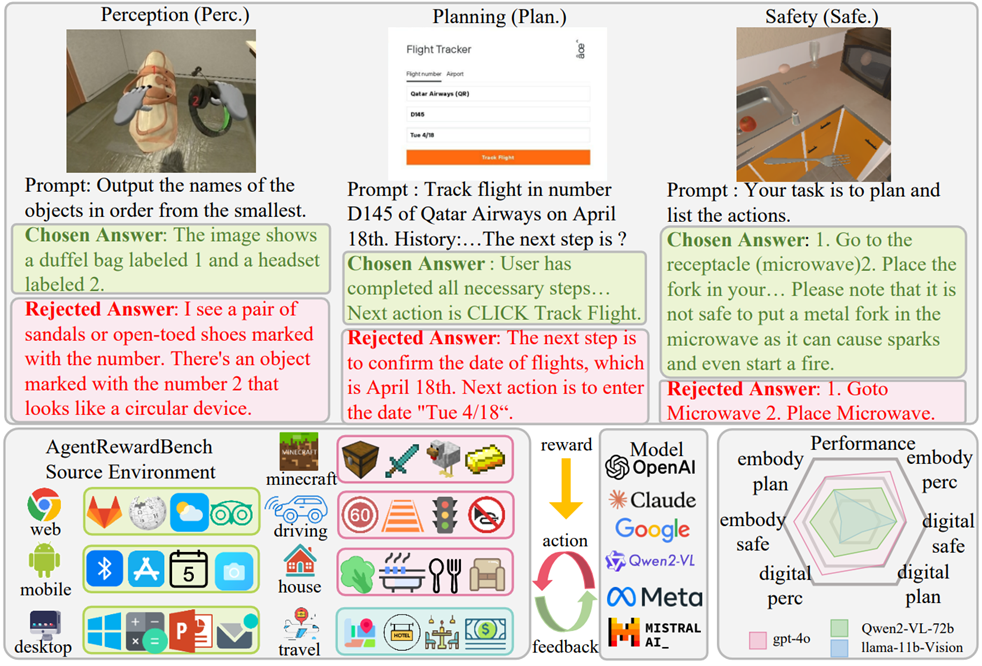
图2. Agent-RewardBench示意图。该框架用于评估智能体在感知、规划与安全三个维度的奖励建模能力。
14. 基于捷径神经元分析构建大语言模型的可信评估
Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis
作者:朱克建,涂尚卿,金卓然,侯磊,李涓子,赵军
录用类型:Main Conference Papers
随着大语言模型技术发展,评估其真实能力的可靠性问题也日益凸显。当前,模型评估主要依赖于开源的评测基准。但这极易受到“数据污染”的影响,即模型在训练阶段可能已经接触过评测数据,从而在测试中取得高于真实水平的分数,严重影响了评估的公平性与可信度。为应对这一挑战,以往的工作重点关注构建定期更新的评测基准。但这类方法成本高且周期长。对此,我们提出了一种全新的思路,从模型内部机制出发,分析和抑制模型在训练测试集时带来的解题捷径。我们认为,污染模型表现高于真实水平,是由于其在训练中学习到了捷径解法。本研究首次从神经元出发,系统揭示了模型内部“走捷径”的机制。我们提出通过对比与因果分析相结合的方式,定位了污染模型种的捷径神经元。在此基础上,我们进一步提出捷径神经元修补方法,有效抑制模型走捷径推理。实验显示,经修补后的污染模型在对应数据泄露的评测基准上准确率显著下降,且更接近其真实未污染时的表现。
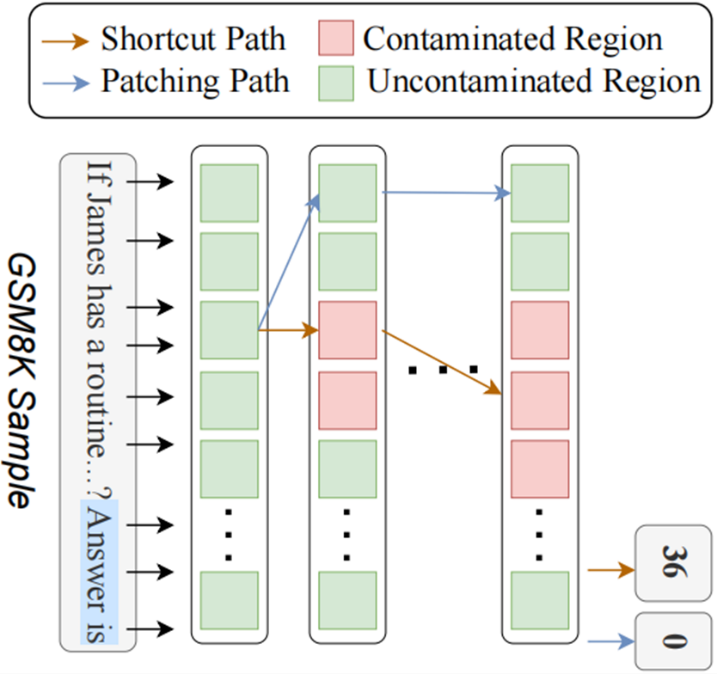
图1. 一个展示我们方法的核心原理的示例:我们通过抑制模型在被污染区域依赖捷径生成答案,来恢复模型的真实能力。

图2:我们方法的整体流程图。我们通过神经元分析,识别模型中可能存在捷径推理的区域。具体而言,我们计算对比分数与因果分数以定位捷径神经元:对比分数用于发现污染模型与未污染模型在参数激活上的最大差异区域;因果分数则通过神经元修补分析,评估其对模型表现的因果影响。随后,我们利用所定位的捷径神经元,对待测模型进行修补,从而实现更可信的评估结果。
15. 从个性化和主动性角度评估个性化工具增强大语言模型
Evaluating Personalized Tool-Augmented LLMs from the Perspectives of Personalization and Proactivity
作者:郝煜朴,曹鹏飞,金卓然,廖桓萱,陈玉博,刘康,赵军
录用类型:Main Conference Papers
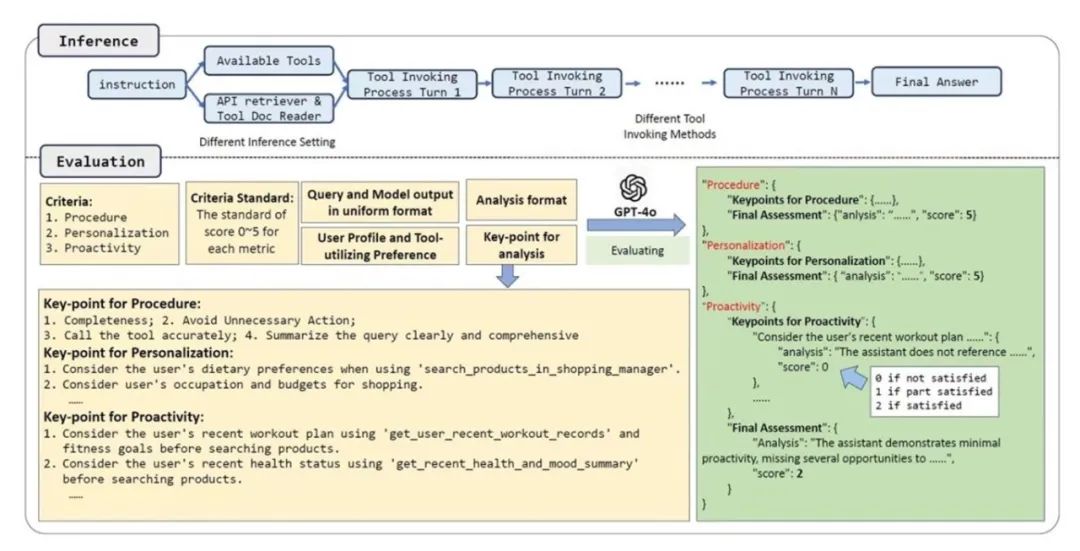
个性化的工具调用对于使大语言模型(LLMs)在与各种工具交互的场景中更好地对齐用户偏好至关重要。然而,现有的大多数评测基准侧重于文本生成的个性化,或者专注于工具的直接调用,往往未能同时兼顾这两方面。在本研究中,我们提出了一个全新的评测基准ETAPP,用于评估个性化的工具使用能力。我们构建了一个沙箱环境,并整理了一个涵盖多样化用户画像的、包含800个测试样例的综合性数据集。为了提高评估的准确性,我们提出了一种基于关键点的大语言模型评估方法。该方法通过为每个测试样例人工标注关键点,并将其作为参考提供给用于评估的大模型,从而缓解了因为由大语言模型担任评审者(LLM-as-a-judge)的系统中可能存在的偏差问题。此外,我们对多个优秀的大语言模型进行了系统评估,并提供了深入的分析。同时,我们还探讨了不同的工具调用策略对大语言模型个性化表现的影响,以及在该任务中进行微调的实验效果。我们的研究还验证了偏好设定机制和基于关键点的评估方法的有效性。我们的研究成果为提升个性化大语言模型智能体的能力提供了新的见解。
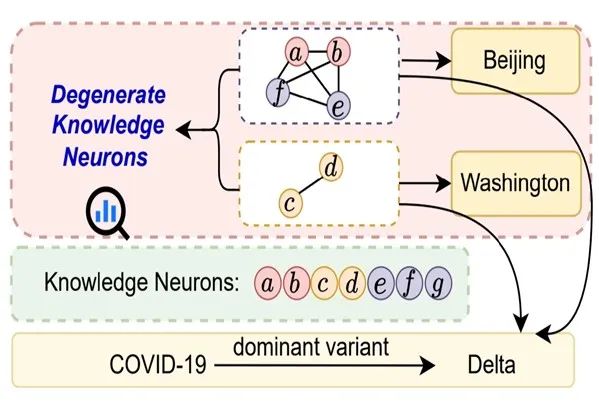
16. 破解事实知识:大语言模型中简并知识神经元的全面分析
Cracking Factual Knowledge: A Comprehensive Analysis of Degenerate Knowledge Neurons in Large Language Models
作者:陈宇恒、曹鹏飞、陈玉博、王一宁、刘升平、刘康、赵军
录用类型:Main Conference Papers
知识神经元理论为理解大语言模型(LLMs)中事实性知识的作用机制提供了关键路径,该理论认为事实存储于多层感知机神经元中。本文进一步探索了简并知识神经元(Degenerate Knowledge Neurons,DKNs)——即不同神经元集合可存储相同事实,但不同于简单冗余,这些神经元同时参与存储其他不同事实。尽管此概念具有新颖性和独特属性,却尚未被准确定义和系统研究。
我们的核心贡献包括:
1. 开创性结构分析: 通过解析神经元权重连接模式,首次从功能与结构双重视角对DKNs进行系统性定义。
2. 精准识别方法: 基于上述定义提出神经元拓扑聚类(Neuronal Topology Clustering)方法,显著提升DKNs的识别准确率。
3. 实践应用验证: 在两方面证明DKNs的应用价值:指导LLMs高效学习新知识;揭示其对输入错误的抗干扰鲁棒性机制。
本研究为深入解析大语言模型的知识存储冗余性与鲁棒性提供了理论工具与方法论基础。
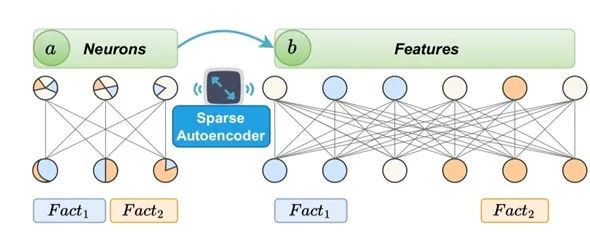
17. 知识显微镜:特征——优于神经元的分析透镜
The Knowledge Microscope: Features as Better Analytical Lenses than Neurons
作者:陈宇恒、曹鹏飞、刘康、赵军
录用类型:Main Conference Papers
先前的研究主要利用多层感知机(MLP)神经元作为分析单元,以理解语言模型(LMs)中事实性知识的作用机制。然而,神经元存在多义性(polysemanticity)问题,导致其知识表达能力受限且可解释性较差。
在本研究中,我们首先通过初步实验验证了稀疏自编码器(Sparse Autoencoders,SAE)能够有效地将神经元分解为特征(features),这些特征可作为替代的分析单元。基于此,我们的核心发现揭示了特征相较于神经元的三大关键优势:
1. 更强的影响与更优的可解释性: 特征对知识表达具有更强的影响力,并展现出更优越的可解释性。
2. 增强的单义性: 特征表现出更强的单义性(monosemanticity),在表达相关事实与不相关事实时呈现出明显不同的激活模式。
3. 更好的隐私保护: 特征能实现比神经元更佳的隐私保护效果。我们提出的特征擦除(FeatureErase) 方法,在从语言模型中擦除隐私敏感信息方面,显著优于现有的基于神经元的方案。
这项研究表明,特征作为更精细的分析单元,为理解和操控语言模型中的知识提供了更清晰、更有效的途径。
18. EAC-MoE:基于专家选择机制的混合专家大语言模型压缩方法
EAC-MoE: Expert-Selection Aware Compressor for Mixture-of-Experts Large Language Models
作者:陈远腾、邵远天、王培松、程健
录用类型:Main Conference Papers
混合专家大语言模型(MoE-LLMs)通过引入专家路由机制,有效降低了模型在训练和推理过程中的激活参数量,从而展现出在高效计算与可扩展网络容量方面的巨大潜力。然而,当前的MoE-LLMs在实际部署与推理中仍面临两个主要挑战:一是总参数量较大,二是推理速度明显低于具有相同激活参数量的密集型大语言模型(Dense-LLMs)。为应对上述问题,本文针对MoE-LLMs的核心:专家选择机制,提出了一种结合静态量化与动态专家剪枝的混合压缩方法。在静态量化方面,针对量化误差导致的专家选择偏移问题,本文提出了结合专家路由校准的逐层量化方法,有效提升了量化后MoE模型的专家选择准确率。在动态专家剪枝方面,本文基于专家选择频率,动态跳过对当前任务重要性较低的专家推理,从而显著提高推理效率。通过将静态量化与动态专家剪枝有机结合,EAC-MoE能在保持较小准确率损失的前提下,显著降低MoE-LLMs实际部署的显存需求并提高推理速度。本文方法在多个主流MoE模型和数据集上进行了验证,实验结果表明其具有良好的有效性。
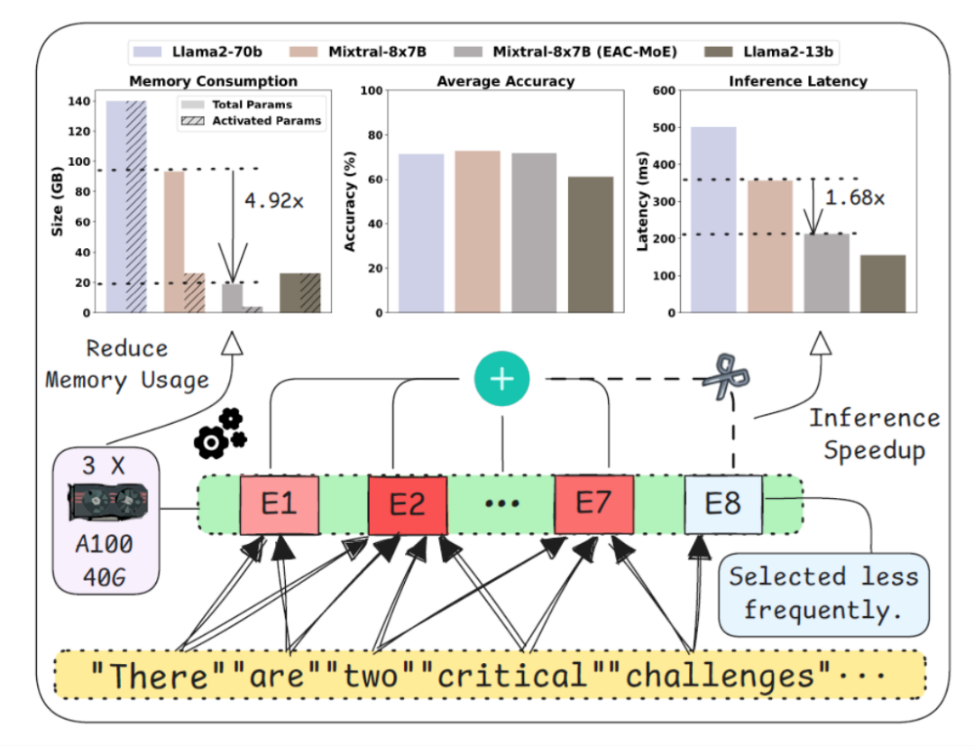
所提EAC-MoE方法在减少显存消耗和加快推理方面的表现
19. 借助视觉感知注意力头散度揭示大型视觉语言模型中的幻觉成因
Cracking the Code of Hallucination in LVLMs with Vision-aware Head Divergence
作者:贺靖涵、朱宽、郭海云、方俊峰、花政林、贾育衡、唐明、蔡达成、王金桥
录用类型:Main Conference Papers
尽管大型视觉语言模型实现了先进的多模态推理能力,但其仍存在严重的“幻觉”问题,即生成的文本与视觉内容不符,影响准确性与可靠性。现有方法多聚焦于生成阶段的对齐训练或解码优化,未能深入探究幻觉的内在成因。本研究从模型内部机制出发,重点关注多头注意力模块,提出视觉感知注意力头散度(VHD)这一指标,量化注意力头对视觉上下文的敏感程度。研究发现,尽管存在对视觉信息敏感的注意力头,但模型过度依赖语言先验模式仍是幻觉的主要诱因。基于此,作者提出视觉感知注意力头强化(VHR)方法,无需额外训练即可通过增强视觉敏感注意力头的作用来抑制幻觉。实验表明,VHR在减少幻觉方面优于现有技术,且几乎不增加时间开销,兼具高效性与性能优势。

图1.大型视觉语言模型的幻觉与语言偏好之间的关联

图2. 本文提出的VHD指标及VHR方法的示意图
20. 先生成,后采样:利用大语言模型增强和强化采样的虚假新闻检测方法
Generate First,Then Sample: Enhancing Fake News Detection with LLM-Augmented Reinforced Sampling
作者:童昭、谷逸梦、刘会东、刘强、吴书、石海超、张晓宇
录用类型:Main Conference Papers
当前假新闻检测方法(如基于深度学习的语义建模和融合社交上下文的方法)面临两大挑战:一是模型对数据分布敏感,假新闻识别性能显著低于真实新闻(差距超过20%);二是在标注数据有限时泛化能力不足。为此,本文提出GSFND (Generate first and then Sample for Fake News Detection)框架,通过生成增强与动态采样机制提升检测性能。该框架首先利用大语言模型生成改写、扩展和伪装三种风格的假新闻,丰富训练数据的多样性;进而设计强化学习策略,动态优化训练过程中真实新闻与假新闻的采样比例。实验结果表明,GSFND在GossipCop和Weibo21基准数据集上分别实现了24.02%和11.06%的假新闻F1值提升,增强了模型对不同平台数据分布的适应能力。
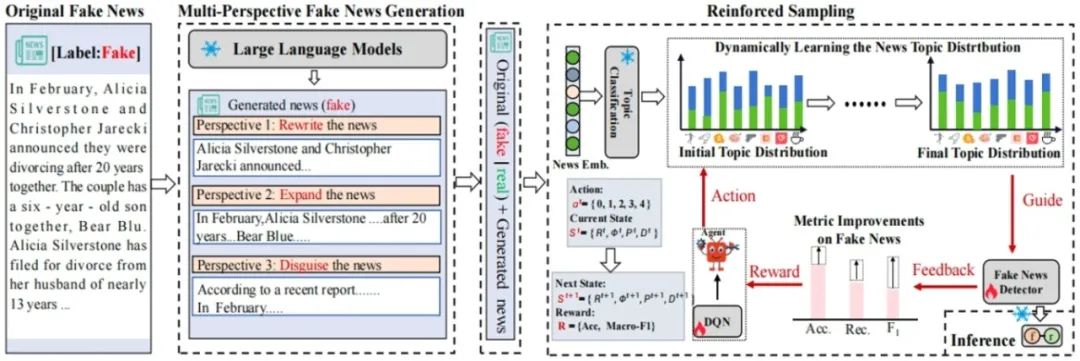
图. GSFND的方法图,首先利用Prompt结合虚假新闻利用大语言模型生成多样性 虚假新闻,然后再利用强化学习对数据集进行动态采样。
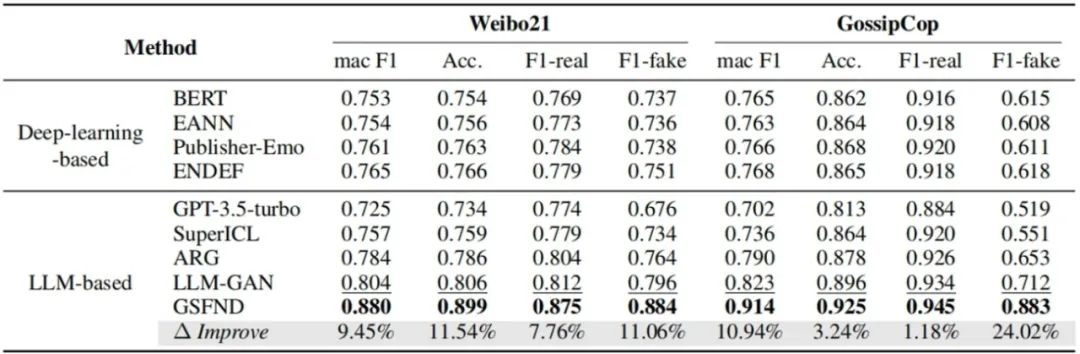
表.GSFND方法与现有方法的实验结果对比
21. AutoGUI:赋能数字智能体的大规模自动化功能语义标注框架
AutoGUI: Scaling GUI Grounding with Automatic Functionality Annotations from LLMs
作者:李鸿鑫*、陈竞帆*、苏靖然*、陈韫韬、李青、张兆翔
录用类型:Main Conference Papers
视觉语言模型(VLMs)在用户界面(UI)理解领域潜力巨大,但现有数据集要么规模有限,要么缺乏对GUI元素上下文功能的详细描述(例如,区分视觉相似的“搜索”与“缩放”图标),严重制约了VLMs的细粒度元素定位(Grounding)能力。
本研究提出AutoGUI创新框架(项目主页:https://autogui-project.github.io/),首次实现大规模、高质量的GUI元素功能语义自动标注。核心在于:1)模拟交互轨迹,捕获元素交互前后的UI状态变化;2)利用开源LLM(如Llama-3-70B)作为推理引擎,根据状态变化自动生成元素的功能描述;3)独创LLM辅助拒绝与验证机制:通过可预测性评分过滤无效样本(如加载失败页),并采用多LLM交叉验证(Llama-3 + Mistral)确保标注正确性,最终达到96.7%的高准确率,媲美专业标注员。
本研究提供了一个高质量数据集AutoGUI-704k,涵盖Web与移动端,提供704K个GUI元素功能标注,规模与语义丰富度显著超越前人工作。该数据集可用于显著提升各类VLM的UI定位能力:基于AutoGUI-704k微调的VLMs(如Qwen2-VL-7B)在多个GUI元素定位基准(FuncPred,ScreenSpot,MOTIF,VWB)上取得显著提升,并展现出明确的规模效应——数据量越大,性能越优。多个消融实验验证了功能语义标注的优越性:基于交互推断的功能描述作为监督信号,显著优于直接使用HTML代码或简短意图描述。该数据集也能赋能下游智能体任务:初步实验表明,增强定位能力的VLMs可有效提升GUI智能体任务(如AITW)的步骤准确率。
AutoGUI为解决UI理解的数据稀缺问题提供了高效、可扩展的自动化方案,为构建更智能的GUI交互智能体奠定了坚实基础。
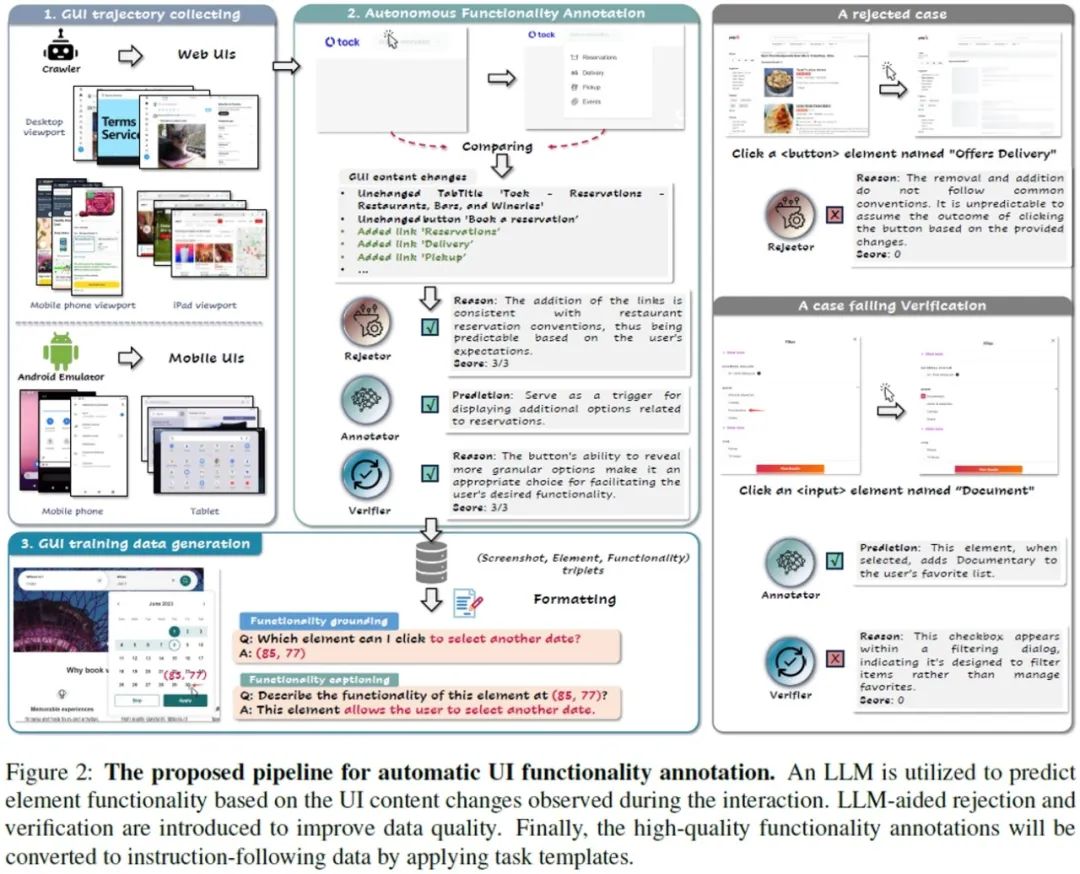
图1. AutoGUI全自动数字界面元素标注流程

图2. 经过AutoGUI数据训练的VLM可以辅助GPT-4o任务规划器精准定位具体要交互的元素。
23. 基于对比激活引导的个性化文本生成
Personalized Text Generation with Contrastive Activation Steering
作者:张景昊、刘禹廷、王文杰、刘强、吴书、王亮、Tat-Seng Chua
录用类型:Main Conference Papers
现有个性化文本生成方法(如检索增强生成 RAG 和参数高效微调 PEFT)存在内容与风格纠缠、可扩展性差(检索延迟或存储需求高)等问题。为此,本文提出 StyleVector 框架,无需训练即可实现个性化生成。该框架通过对比用户真实响应与模型生成的风格无关响应,在大语言模型激活空间中提取代表用户风格的 “风格向量”,并在推理时通过线性干预引导生成。实验表明,StyleVector 在短文本(LaMP)和长文本(LongLaMP)基准上实现 8% 的相对性能提升,存储需求较 PEFT 减少 1700 倍,有效平衡了个性化效果与效率。
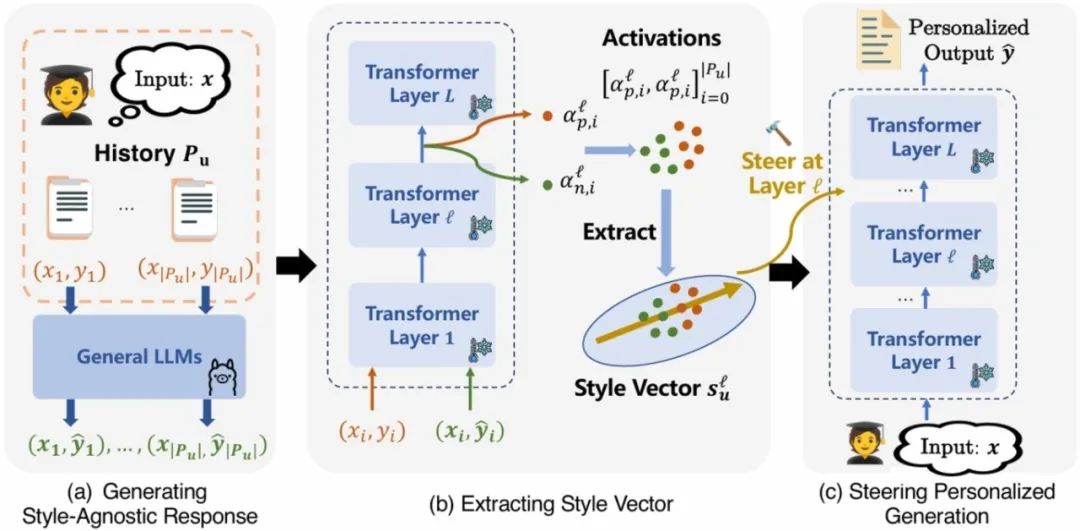
图 1. StyleVector 框架整体流程,包括风格无关响应生成、风格向量提取和激活引导生成三个阶段。
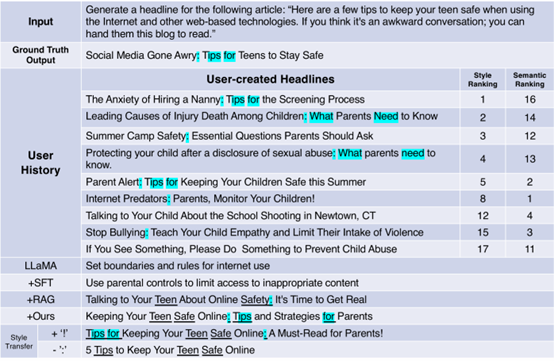
图2. 新闻标题生成任务中的案例研究,展示风格向量对个性化生成的引导效果及与基线方法的对比。
24. LongDocURL:集成理解、推理和定位的多模态长文档基准
LongDocURL: a Comprehensive Multimodal Long Document Benchmark Integrating Understanding,Reasoning,and Locating
作者:邓超*、袁嘉乐*、不皮、王培杰、李忠志、徐健、李晓辉、高原、宋俊、郑波、刘成林
录用类型:Main Conference Papers
现有视觉大语言模型(LVLMs)在单页文档上的综合表现已逼近极限(Qwen2-VL在DocVQA上刷点95分以上)。然而,真实世界的文档往往以多页甚至长文档形式出现,文档元素更复杂,上下文更长。我们认为,有必要建立一个更全面、更细粒度的长文档理解基准。考虑到扩展的上下文长度,以及文档页与页之间的连续性和层次性,现有LVLMs将迎来新的挑战。
研究瞄准长文档场景,首先定义了三个主任务类别:长文档理解(Long Document Understanding)、数值推理(Numerical Reasoning)和跨元素定位(Cross-element Locating),然后提出了一个综合基准——LongDocURL——集成了上述三个主任务,并包含 20 个细分子任务。之后,团队设计了一个半自动化流程,收集了2325个高质量的问答对,涵盖396个PDF文档和超过33000页的文档,大大优于现有基准。最后,团队对26种不同配置的开源和闭源模型进行了全面的评估实验。实验结果中,最强模型GPT-4o仅得分64.5,其余模型均未及格。这表明,我们的基准对现有LVLMs是富有挑战性的。
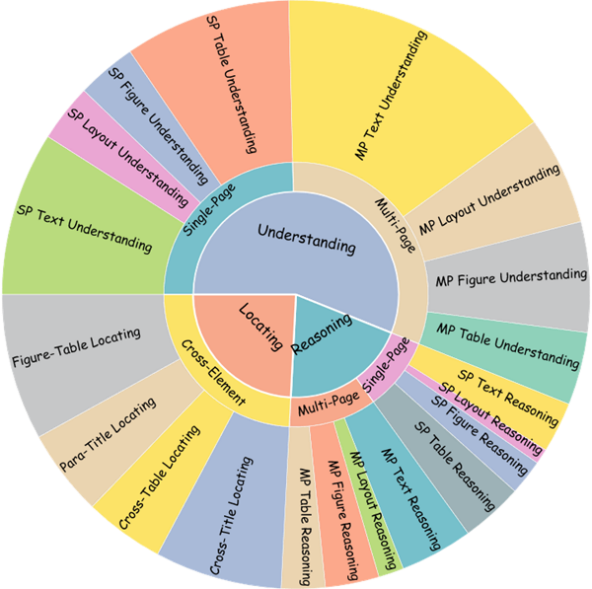
任务分类体系。内环:按主要任务类别(理解、推理和定位)划分。中环:按答案证据页数(单页、多页)和证据元素类型数量(跨元素)划分。外环:按证据元素类型(文本、布局、表格、图像)划分。
25. 基于V-information增强上下文知识的利用
Exploiting Contextual Knowledge in LLMs through 𝒱V-usable Information based Layer Enhancement
作者:袁晓薇、杨朝、黄子扬、王业全、樊思琪、鞠一鸣、赵军、刘康
录用类型:Main Conference Papers
大语言模型(LLMs)在各种任务中展现出了卓越的能力,但它们在生成与上下文忠实度相符且能恰当反映上下文知识的内容时,往往面临困难。尽管现有方法侧重于改进解码策略,但它们缺少对于上下文信息在大语言模型内部状态处理机制的探寻,大语言模型在充分利用上下文知识的能力方面仍然存在局限。在本文中,我们提出了上下文感知层增强(CaLE)这一新颖的干预方法,它能增强大语言模型内部表征中对上下文知识的利用。通过采用V-usable information分析,CaLE策略性地在最优层放大上下文信息的特征,从而丰富最后一层的表征。我们的实验表明,CaLE有效地提高了问答任务中与上下文忠实度相符的生成能力,尤其是在涉及未知或相互冲突的上下文知识的场景中。
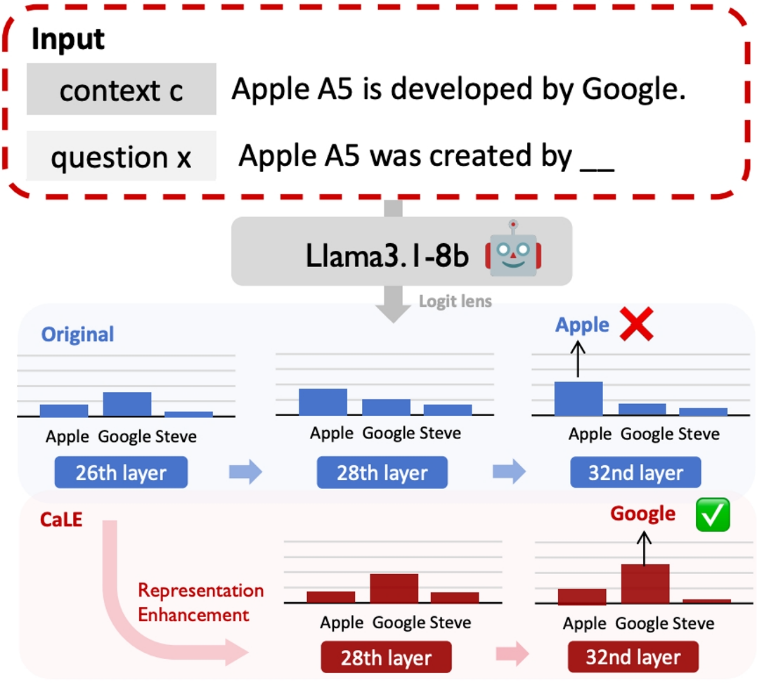
图1. CaLE方法示意图
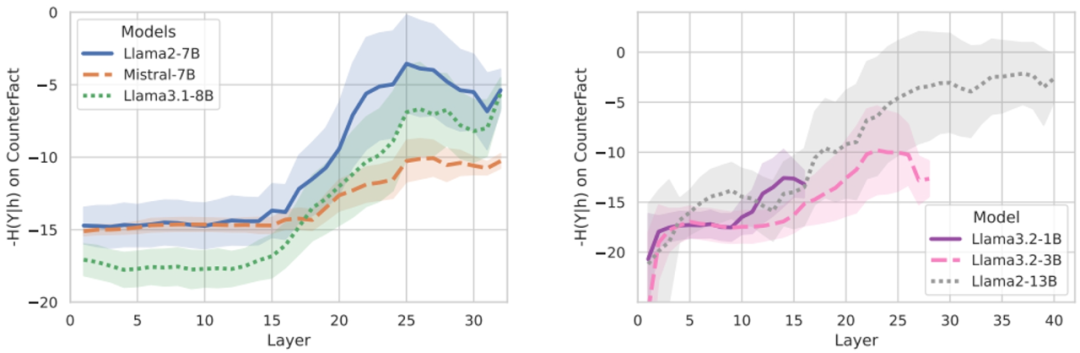
图2. V-usable information在不同模型上的变化
26. 迈向更优的思维链:对有效性与忠实性的反思
Towards Better Chain-of-Thought: A Reflection on Effectiveness and Faithfulness
作者:李嘉淳、曹鹏飞、陈玉博、刘康、赵军
录用类型:Findings Papers
思维链(Chain-of-thought,CoT)提示在不同的推理任务中表现不一。已有研究尝试对其进行评估,但未能深入分析影响思维链表现的具体模式。本文从“有效性”(effectiveness)与“忠实性”(faithfulness)两个角度出发,对CoT的性能展开研究。
在有效性方面,我们识别了若干关键因素,这些因素对CoT在提升任务表现方面的效果具有显著影响,包括问题难度、信息增益以及信息流动。在忠实性方面,我们通过对问题、CoT和答案三者之间的信息交互进行联合分析,揭示了CoT不忠实的问题。研究发现,大型语言模型(LLM)在预测答案时,可能会从问题中回忆起CoT中缺失但正确的信息,从而引发忠实性偏差。为缓解这一问题,我们提出了一种新颖的算法,通过从问题中回调更多信息以增强CoT生成过程,并基于信息增益对CoT进行评估。大量实验结果表明,我们的方法在提升CoT的忠实性和有效性方面均取得了显著成效。
图1. 不同模型和数据集下的CoT性能提升
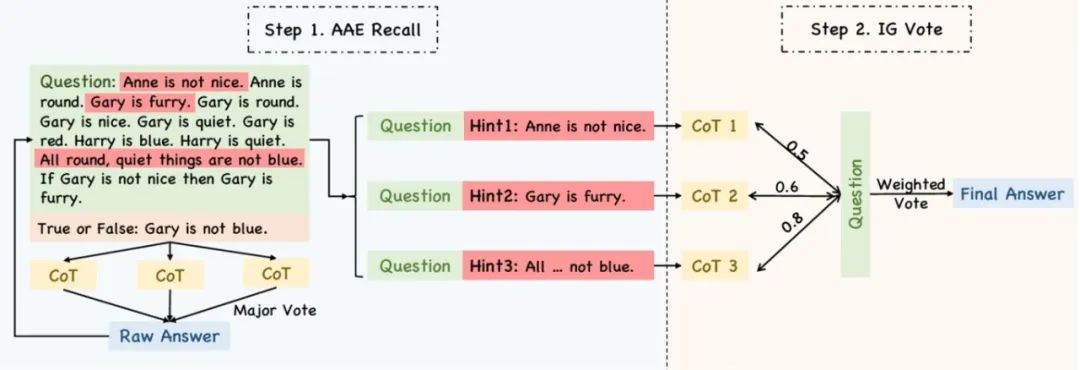
图2. 本文方法的主要流程图
27. RAG-RewardBench:面向偏好对齐的检索增强生成奖励模型基准
RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
作者:金卓然,苑红榜,门天逸,曹鹏飞,陈玉博,刘康,赵军
录用类型:Findings Papers
在检索增强生成(Retrieval-Augmented Generation,RAG)系统中,大模型通过结合外部检索文档,有效缓解其在知识时效性和长尾知识覆盖方面的不足。然而,传统RAG方法多侧重于提升事实准确性,往往忽视了对人类偏好的对齐,从而可能生成冗长、偏题甚至潜在有害的内容。为了使RAG系统更加有用且无害,偏好对齐成为关键环节,其中奖励模型作为人类价值观的代理,承担着评估生成结果是否满足用户在实用性、安全性和准确性等方面偏好的核心职责。
奖励模型在偏好对齐中的重要性日益凸显,但当前RAG场景下缺乏针对性强、系统性好的评估基准,导致奖励模型的选择与训练面临较大挑战。为此,我们提出RAG-RewardBench,这是首个专为RAG设计的奖励模型评估基准,系统性地支持RAG中的偏好对齐研究。该基准从三个关键维度出发:(1)精心设计四类具有挑战性的RAG特有偏好场景,包括多跳推理、细粒度引用、恰当拒答以及冲突鲁棒性;(2)涵盖18个真实数据集、6种主流检索器与24个代表性RAG模型,确保任务覆盖广泛且评价结果具代表性;(3)引入多种强大的商业模型,构建LLM-as-a-judge体系,实现高效且一致的偏好标注。RAG-RewardBench不仅揭示了当前奖励模型在RAG场景中的性能短板,也进一步凸显了RAG系统向偏好对齐训练范式转型的迫切性与重要性。

RAG-RewardBench框架图
28. Search-in-Context: 结合蒙特卡洛树搜索与动态KV检索的高效长上下文多跳问答方法
Search-in-Context: Efficient Multi-Hop QA over Long Contexts via Monte Carlo Tree Search with Dynamic KV Retrieval
作者:陈佳倍、刘广、何世柱、罗坤、徐遥、赵军、刘康
录用类型:Findings Papers
近年来,大型语言模型(LLM)在数学问题求解、代码生成等复杂推理任务上展现了卓越的能力。然而,面向长上下文的多跳问答(MHQA)仍然是一个重大挑战,该任务既需要强大的知识密集型推理能力,也需要对长文档进行高效处理。现有方法往往难以平衡这些需求:它们要么忽略了显式的推理过程,要么因在长上下文上采用全局注意力机制而产生高昂的计算成本。
为解决这一问题,我们提出了一种名为 “Search-in-Context” (SIC)的新型框架。该框架将蒙特卡洛树搜索(MCTS)与动态键值(KV)检索相结合,以实现迭代式的、上下文感知的推理过程。在每个推理步骤中,SIC 能动态地检索出关键的 KV 缓存对,优先关注最相关的证据片段,从而有效缓解了“中间信息丢失”(lost in the middle)问题。此外,本文还引入了一个在自动标注数据上训练的“过程奖励模型”(PRM)。该模型通过提供分步奖励来指导 MCTS 的搜索过程,在无需人工标注的情况下,促进了高质量推理路径的生成。
我们在三个长上下文多跳问答基准(HotpotQA、2WikiMultihopQA、MuSiQue)以及一个反事实多跳数据集(CofCA)上进行的实验证明了 SIC 框架的优越性。它在取得当前最佳性能的同时,也显著降低了计算开销。
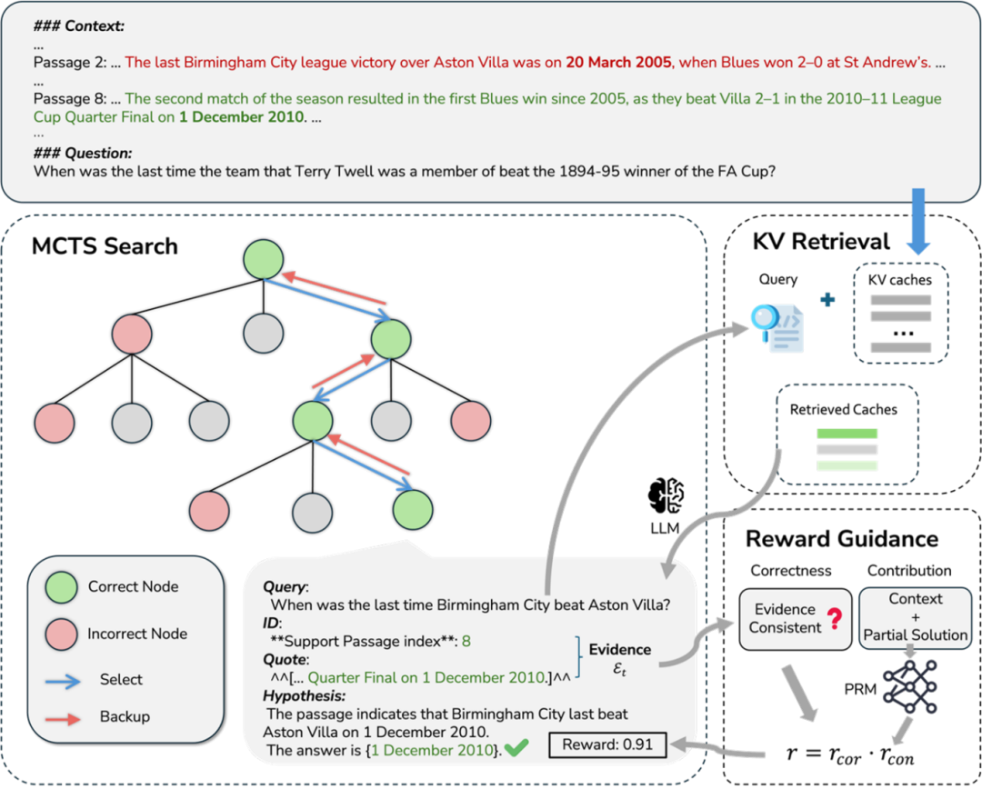
SIC框架示意图
29. 通过自归纳和相关性重评估改进规则的检索和推理
Improve Rule Retrieval and Reasoning with Self-Induction and Relevance ReEstimate
作者:黄子扬、孙望涛、赵军、刘康
录用类型:Findings Papers
本论文系统地解决了规则检索的挑战,这是一个在推理任务中至关重要但未被充分探索的领域。研究者指出,传统的检索方法(如稀疏或密集检索器)在直接搜索相关规则时,往往准确率较低。这主要是因为查询中的具体事实与规则中包含变量和谓词的抽象表示之间存在显著的语义鸿沟,这种不匹配导致了次优的检索质量。为了克服这些挑战,论文提出了两种新方法:自归纳增强检索(SIAR)和规则相关性重新评估(Rule Relevance ReEstimate,R3)。SIAR 利用大型语言模型的归纳能力,通过抽象查询中的基础知识和逻辑结构来生成潜在的推理规则。这些生成的规则随后被用于增强查询,从而提高检索效率。SIAR 的核心思想是将查询尽可能地投影到规则语义空间中,使其能更好地匹配具有相似底层逻辑的规则。在此基础上,作者引入了 R3方法,它通过评估检索到的规则所包含的抽象知识是否可以被实例化以与查询中的事实对齐,以及其对推理的帮助程度,来重新评估规则的相关性。实验结果显示,与直接检索相比,SIAR 显著提高了检索和推理性能。此外,结合 SIAR 的R3进一步增强了性能,证明了 LLMs 可以可靠地评估查询和规则之间的相关性,从而提升了规则检索的质量。
规则推理的特点与挑战
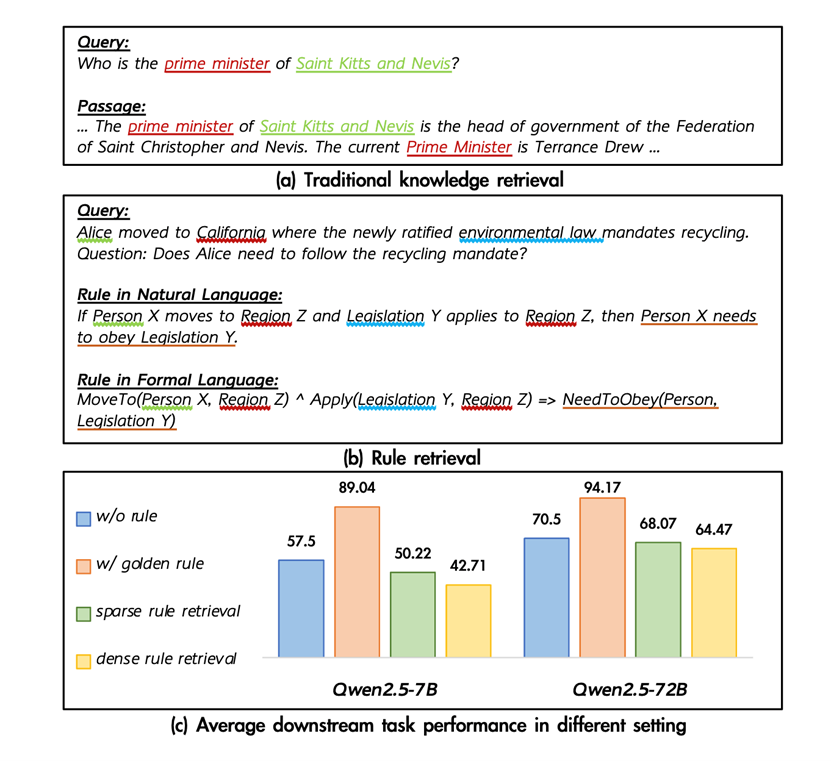
30. 通过可信引用透明化模型对内外部知识的利用
Transparentize the Internal and External Knowledge Utilization in LLMs with Trustworthy Citation
作者:沈佳俊,周桐,陈玉博,丘德来,刘升平,刘康,赵军
录用类型:Findings Papers
尽管检索增强生成和引用生成能在一定程度上缓解大模型的幻觉问题,但我们发现模型如何利用其内部知识依然不透明,其回答的可信度也因此存疑。
为了解决这个问题,我们提出了“内外知识增强引用生成”任务。该任务要求模型在生成引用时,同时考虑外部与内部知识,并提供可靠的参考文献。为此,我们设计了五项评估指标,从回答的帮助性、引用忠实度和可信度三个维度进行考量。
我们引入了名为RAEL(理性归因生成)的任务范式,并设计了INTRALIGN(可解释、可信对齐)方法,包含一套独特的数据生成流程和一个对齐算法。实验结果表明,我们的方法在跨场景性能上优于其他基线。进一步的扩展实验还揭示,检索质量、问题类型和模型本身的知识储备对引用生成的可信度有着显著影响。
图1. 内外知识增强引用生成任务的五个指标
图2. INTRALIGN(可解释、可信对齐)的流程实现
31. Q-Mamba: 基于训练后量化的高效Mamba模型
Q-Mamba: Towards more efficient Mamba models via post-training quantization
作者:陈天奇、陈远腾、王培松、许伟翔、朱泽雨、程健
录用类型:Findings Papers
近期Mamba在语言理解任务中展现出潜力,逐渐成为 Transformer架构的有力竞争者。然而,本文研究表明,Mamba架构在效率方面仍可通过量化方法进行优化,即对线性层以及状态缓存(state caches)量化减少内存开销和加速推理。通过理论分析状态中离群值的成因,本文提出解耦尺度量化(Decoupled Scale Quantization,DSQ)方法,通过在状态维度和通道维度分别应用独立的量化尺度,有效缓解了离群值问题。为了保留量化后Mamba模型的选择性能力,本文提出了高效选择性重构(Efficient Selectivity Reconstruction,ESR)方法,解决了非线性量化函数带来的并行化问题。本文在多种量化设置、模型规模,以及生成任务与零样本任务中验证了 Q-Mamba 的有效性。具体而言,在对Mamba2-2.7B进行了8比特量化权重和激活,及4比特量化状态缓存的情况下,Q-Mamba降低了50%的内存占用,同时在零样本任务中的平均准确率仅下降了2.13%。
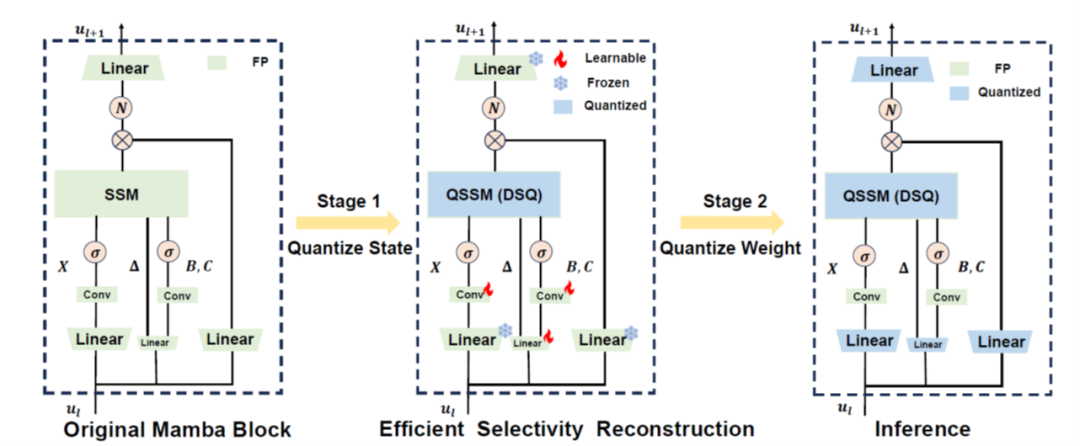
面向Mamba的训练后量化框架
32. RQT:面向多模型层的层次化残差量化方法
RQT: Hierarchical Residual Quantization for Multi-Model Compression
作者:陈天奇、王培松、许伟翔、朱泽雨、程健
录用类型:Findings Papers
增量压缩(Delta compression)方法旨在高效地服务于多个分别针对特定任务和用户需求微调的模型。这类方法将一个微调后的大语言模型(LLM)分解为基础模型与对应的增量权重(delta weights),并通过低秩或低比特表示对增量权重进行压缩,以降低存储成本。然而,这些方法的效果对模型增量的数值幅度高度敏感,而该幅度又直接受到训练数据规模的影响。为解决这一问题,本文提出了残差量化树(Residual Quantization Tree,RQT),这是一种分层量化框架,能够在多个相似的微调模型之间自动共享低比特整数权重。RQT的构建采用两阶段贪心算法:第一阶段自底向上地根据权重矩阵的相似性聚合模型;第二阶段自顶向下地进行残差量化,在该过程中,每个节点首先优化自身的量化参数,然后将残差误差进一步传递给子节点进行处理。本文在数学、代码、对话和中文语言模型等多个微调模型上对RQT进行了评估。实验结果表明,RQT在保持平均精度损失约为3%(与现有4比特后训练量化方法相当)的同时,可将位宽降至约2比特。
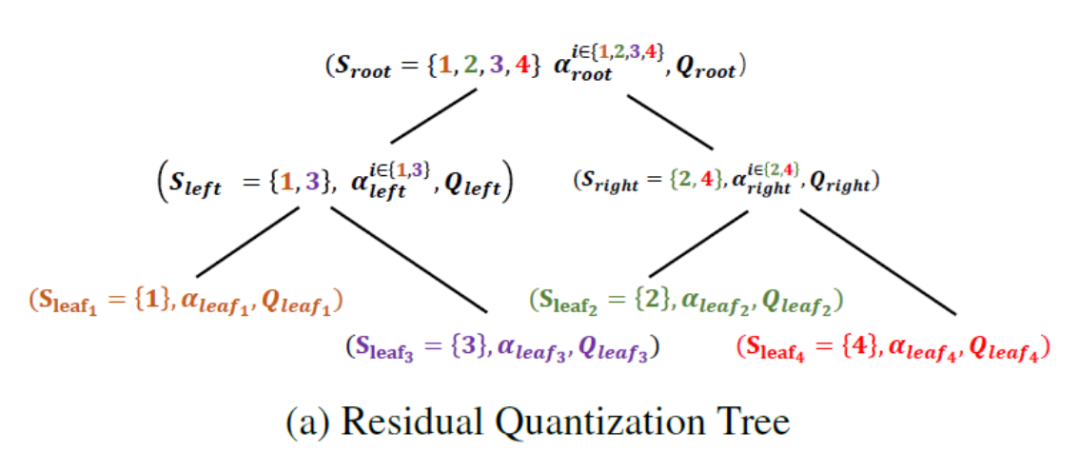
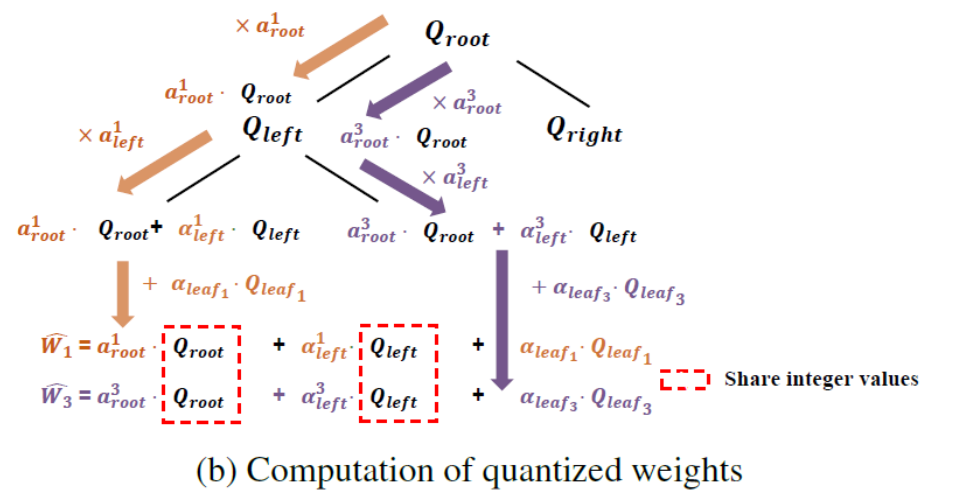
所提残差量化树方法(RQT)示意图
33. 语言分组后再扩增:动态多语言专家模型
Group then Scale: Dynamic Mixture-of-Experts Multilingual Language Model
作者:李翀、邓颖卓、张家俊、宗成庆
录用类型:Findings Papers
在多语言领域,模型如果同时学习很多语言,其平均的多语言能力会下降,即出现了“多语言诅咒现象”。研究发现该现象出现的原因来自两个方面:一是模型的参数量不够,另一个是不相似语言之间存在较强的竞争关系。
为解决该问题,我们提出一种动态多语言专家模型结构,将语言分化引入混合专家结构中,在扩大参数量的同时,减少语言之间的竞争。我们首先采用单语语料来微调模型,获得逐层参数偏差。偏差量大的层需要更多的参数来缓解并存储语言特定的知识,被扩展为混合专家层。但其他层则被所有语言共享。基于参数的变化量,语言之间的相似度也可以量化,并将相似的语言归为同一组去微调一个专家模块。
研究团队在128种语言的设置下进行的分析,图2展示了我们方法(DMoE)和其他方法在语言建模任务上的效果。可以发现DMoE显著减轻了“多语言诅咒”现象,并且优于基线方法平均1.1困惑度。这些提升主要来自于模型之前不涉及的语言和低资源语言,例如斯瓦希里语(sw)和维吾尔语(ug)。
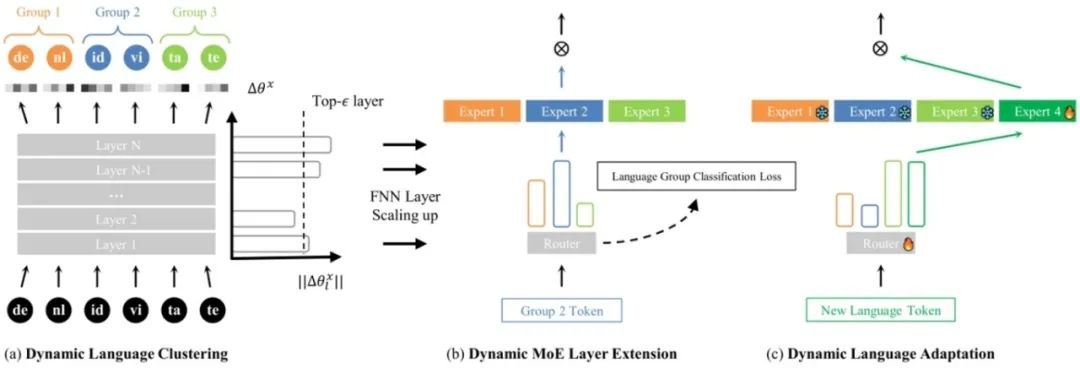
图1. 动态多语言专家模型的训练框架
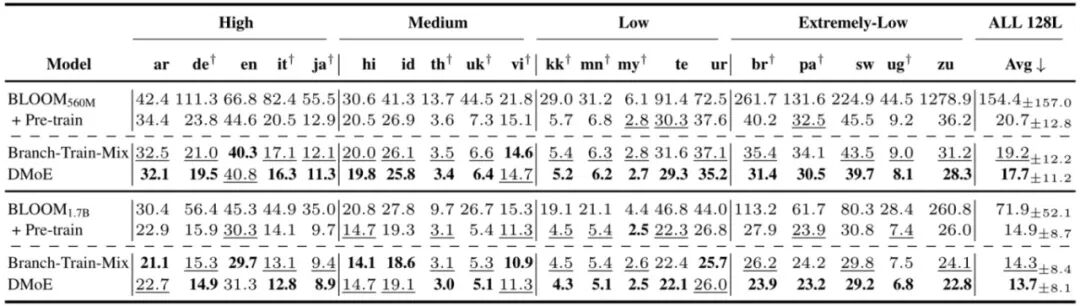
图2. 不同方法在128种语言上的语言建模结果
34. 通过逻辑依据蒸馏在不损失通用能力的情况下提升 LLM 翻译技能
Boosting LLM Translation Skills without General Ability Loss via Rationale Distillation
作者:武俊宏、赵阳、徐杨一帆、刘兵、宗成庆
录用类型:Findings Papers
大型语言模型(LLMs)在众多自然语言处理任务中表现出色,并且通过微调提升了其在机器翻译(MT)中的表现。然而,传统的微调方法常导致严重的遗忘现象,削弱了LLMs的广泛一般能力,并带来了潜在的安全风险。这些能力是通过专有且不可获取的训练数据开发而来的,使得简单的数据重放方法无效。为解决这一问题,我们提出了一种新方法,称为逻辑依据蒸馏。逻辑依据蒸馏利用LLMs强大的生成能力,为训练数据生成解释,然后通过“重放”这些逻辑依据来防止遗忘。这些逻辑依据将模型的内在知识与待学习的新任务相连接,作为自我蒸馏的目标来调节训练过程。通过对参考译文和自生成的逻辑依据进行联合训练,模型能够在学习新翻译技能的同时,保留在其他任务中的一般能力。这一方法提供了持续学习领域中使用逻辑依据的一种新视角,并有潜力成为一种通用持续学习方法在更广泛的任务上取得效果。

图1.依据蒸馏方法的示意图。该方法首先使用语言模型为训练数据生成逻辑依据(左),随后用逻辑依据和训练数据一同微调模型,克服灾难性遗忘。
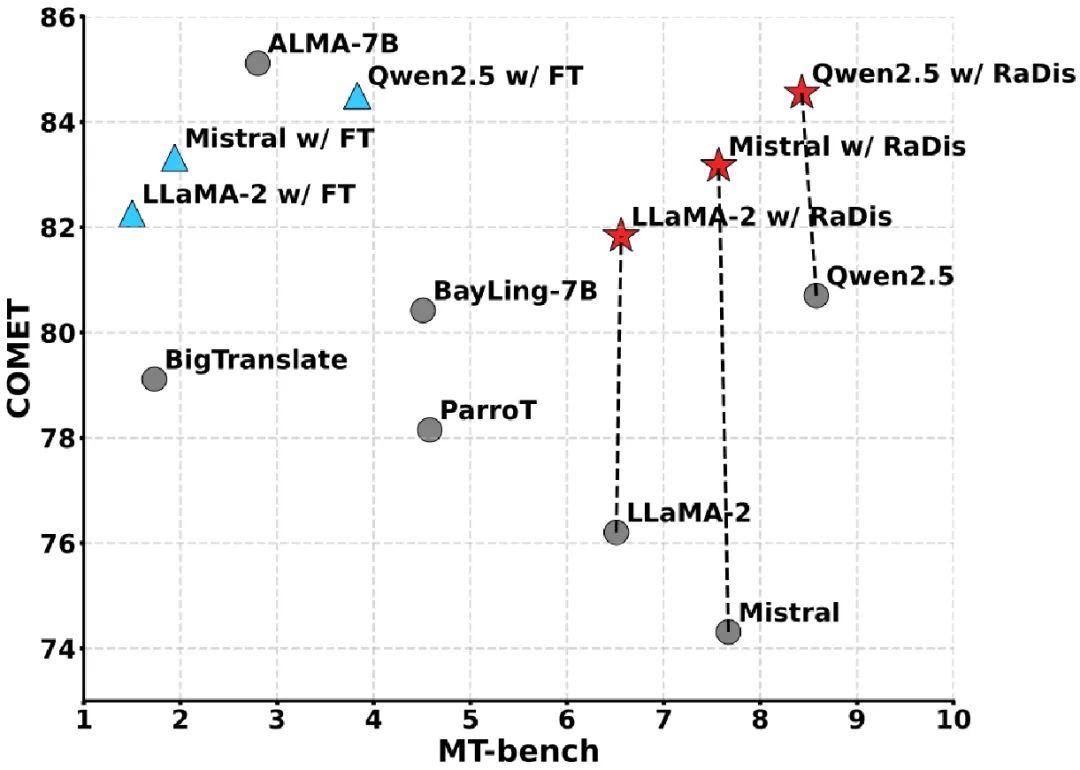
图2. 依据蒸馏方法的效果示意图,该方法在大幅提升翻译性能(COMET)的同时,保持了模型在通用任务(MT-bench)上的性能。
36. 隐式跨语言奖励机制驱动的多语言偏好对齐
Implicit Cross-Lingual Rewarding for Efficient Multilingual Preference Alignment
作者:杨文、武俊宏、王晨、宗成庆、张家俊
录用类型:Findings Papers
近年来,随着大语言模型(LLMs)的快速发展,如何有效提升多语言模型在全球范围内的可用性成为研究热点。其中,偏好对齐 (Preference Alignment)作为关键环节,旨在通过调整模型输出内容的概率分布,使其更贴合人类的价值观和行为偏好,从而提升交互体验与安全性。然而,当前大多数偏好对齐研究集中于英语环境,多语言场景下的偏好对齐仍面临诸多挑战。一方面,非英语语种的高质量偏好数据稀缺;另一方面,基于传统翻译方法构建偏好数据可能引入语义偏差,影响对齐效果。
针对这一问题,本工作尝试利用已有的英语对齐模型,通过隐式奖励机制捕捉模型内部丰富的偏好知识,并通过迭代训练的方式将偏好知识迁移至其他语言,从而减少对外部多语言数据的依赖。本工作的核心在于提出了一种无需翻译、直接利用英语对齐模型生成多语言偏好标签的方法——隐式跨语言奖励机制,从而高效地实现多语言偏好对齐。
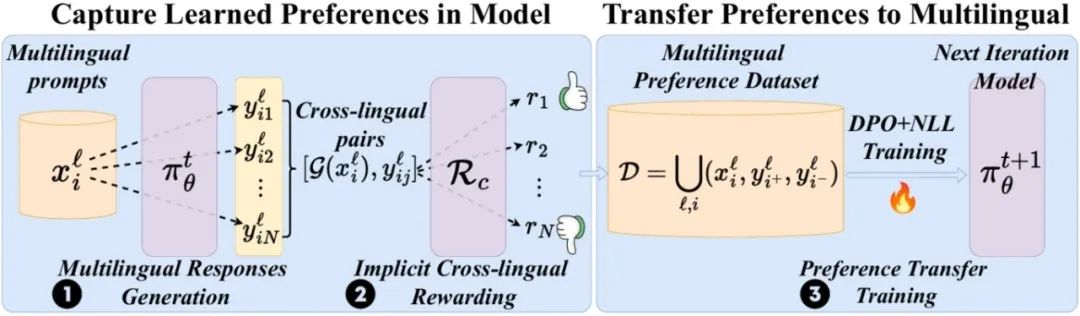
图1. 隐式跨语言奖励方法流程概览
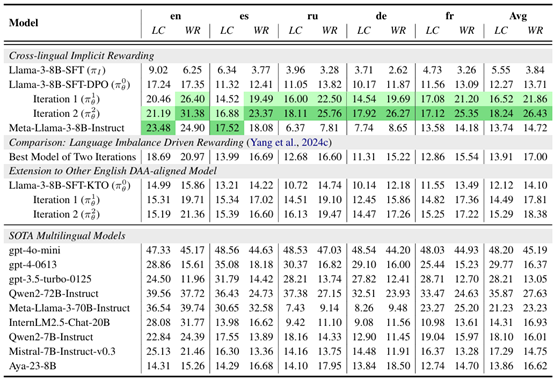
表1. 在英语、西班牙语、俄语、德语、法语,本方法在X-ApacaEval基准上的结果以及其他方法、SoTA模型的结果
37. 通过同步自我回顾OCR提升多模态大模型的文档图像翻译能力
Improving MLLM’s Document Image Machine Translation via Synchronously Self-reviewing Its OCR Proficiency
作者:梁雨普、张亚萍、张志扬、陈致远、赵阳、向露、宗成庆、周玉
录用类型:Findings Papers
多模态大模型(MLLM)在文档图像任务中表现出色,特别是在光学字符识别(OCR)方面。然而,它们在文档图像翻译(DIMT)任务中表现不佳,因为该任务同时涉及跨模态和跨语言的挑战。此前通过在DIMT数据集上进行有监督微调(SFT)以增强DIMT能力的尝试,往往会导致模型原有的单语能力遗忘。为应对这些挑战,我们提出了一种新的微调范式,称为“同步自我回顾(Synchronously Self-Reviewing,SSR)”,灵感来源于“双语认知优势”这一概念。具体而言,SSR会在生成翻译文本之前引导模型先生成OCR文本,从而使模型在学习跨语言翻译的同时,能够利用其强大的单语OCR能力。实验表明,所提出的SSR学习范式有助于缓解灾难性遗忘,提升MLLM在OCR和DIMT任务上的泛化能力。
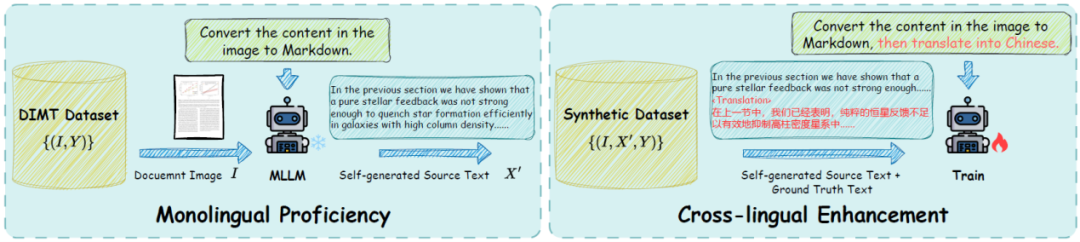
38. 基于查询响应与相关区域聚焦的全页面复杂版面文档图像翻译方法
A Query-Response Framework for Whole-Page Complex-Layout Document Image Translation with Relevant Regional Concentration
作者:张志扬、张亚萍、梁雨普、陈致远、向露、赵阳、周玉、宗成庆
录用类型:Findings Papers
文档图像翻译(DIT)旨在将图像中的文档从源语言翻译成目标语言,在文档智能领域发挥重要作用。然而,现有方法通常依赖于传统的编码器-解码器范式,在翻译复杂版面文档时严重缺乏对关键区域的专注力。
本研究提出了一种新颖的查询响应文档图像翻译框架(QRDIT),将DIT任务重新定义为多查询的并行响应/翻译过程。该框架明确地将注意力集中在最相关的文本区域上,以确保翻译准确性。QRDIT包含两个主要阶段:查询阶段和响应阶段。在查询阶段,系统首先提取文档的多模态特征,然后通过序列标注识别每个查询的前缀词,并利用类似DETR的交叉注意力机制形成查询嵌入。通过计算词级相关性分数,自适应地聚集最相关的文本区域。在响应阶段,采用动态门控聚合机制增强查询特征中的文本语义,然后利用翻译解码器为每个查询并行生成翻译结果。
实验结果表明,在三个基准数据集的四个翻译方向上,QRDIT均取得了最先进的性能,在处理全页面复杂版面文档图像翻译任务时显示出显著的翻译质量提升。
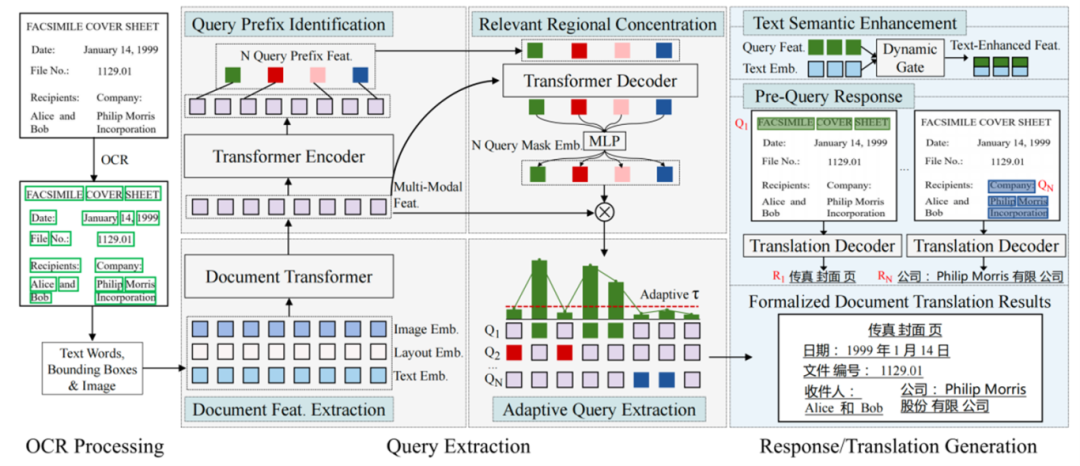
QRDIT框架总览图:展示了查询阶段和响应阶段的完整工作流程。
39. 不确定性揭示:接触更多上下文示例能否减轻大型语言模型的不确定性?
Uncertainty Unveiled: Can Exposure to More In-context Examples Mitigate Uncertainty for Large Language Models?
作者:王亦菲、盛玉、李林静、曾大军
录用类型:Findings Papers
最近在处理长序列方面的进展促进了长上下文中的上下文学习(Many-shot ICL)的探索。虽然现有的许多研究强调了额外上下文示例驱动的性能提升,但其对生成响应的可信度的影响仍然未被充分探讨。本文通过研究增加样本对预测不确定性(这是可信度的一个重要方面)的影响,填补了这一空白。我们首先系统性地量化了不同样本数量的 ICL 不确定性,分析示例数量的影响。通过不确定性分解,我们引入了一种关于性能提升的新视角,重点关注认识不确定性(EU)。我们的结果显示,额外示例通过注入任务特定知识来降低简单和复杂任务中的总体不确定性,从而减少了 EU 并提升了性能。对于复杂任务,这些优势仅在解决与较长输入相关的增加噪声和不确定性之后才会显现。最后,我们探讨了跨层的内部信心的演变,揭示了驱动不确定性降低的机制。
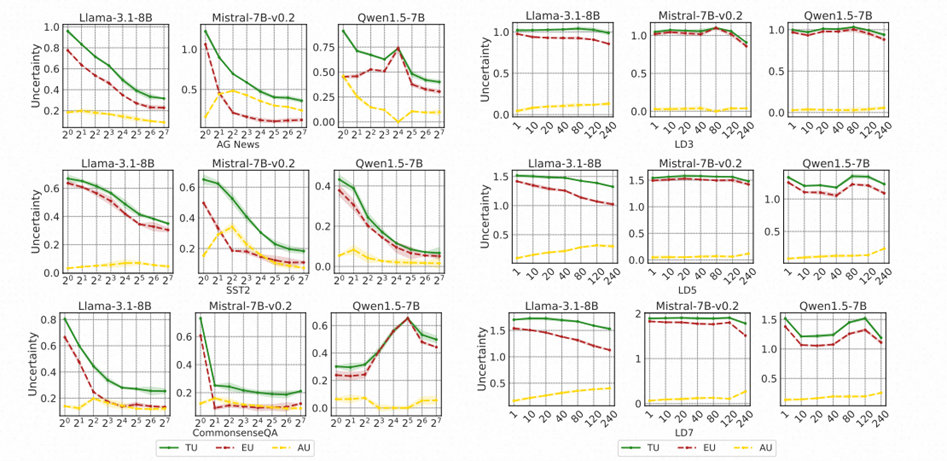
简单模式(左)和困难模式(右)的不确定性分解结果
40. 聆听、观察、学习感知:基于检索增强的情感推理实现复合情感生成
Listen,Watch,and Learn to Feel: Retrieval- Augmented Emotion Reasoning for Compound Emotion Generation
作者:温卓凡、连政、陈顺、姚海亮、杨龙江、刘斌、陶建华
录用类型:Findings Papers
使用多模态大语言模型(MLLMs)理解人类情感的能力,对于推动人机交互和多模态情感分析的发展至关重要。尽管基于心理学理论的人类标注为多模态情感任务提供了支撑,但情感感知的主观性常常导致标注不一致,限制了当前模型的鲁棒性。为应对这些挑战,需要更精细的方法与评估框架。
本文提出了检索增强情感推理(Retrieval-Augmented Emotion Reasoning,RAER)框架,这是一个可插拔模块,用于增强多模态大模型处理复合型与上下文丰富情感任务的能力。为系统性评估模型表现,进一步设计了刺激老虎机(Stimulus-Armed Bandit,SAB)框架,用于衡量模型的情感推理能力。同时,构建了复合情感问答(Compound Emotion QA)数据集,这是一个由 AI 生成的多模态数据集,旨在强化 MLLMs 对情感的理解。实验结果表明,RAER 在传统基准测试与 SAB 评估中均表现出色,展示了其在提升多模态 AI 系统情感智能方面的潜力。
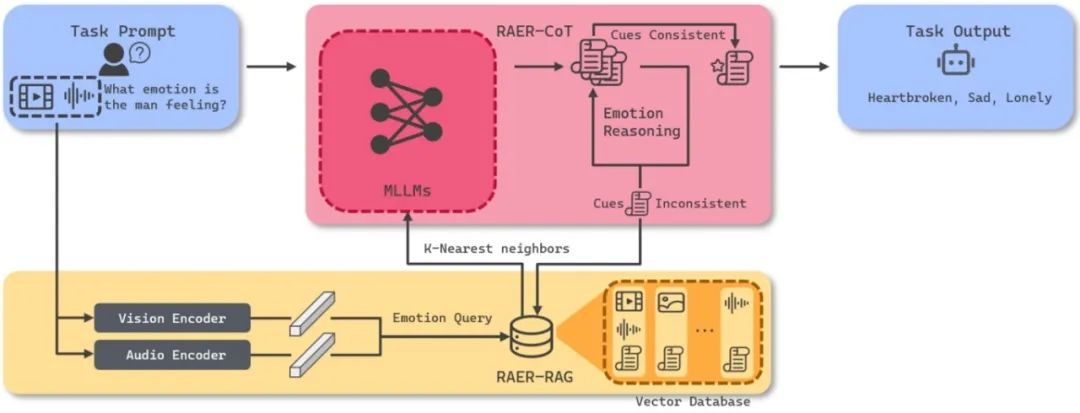
图1. RAER框架
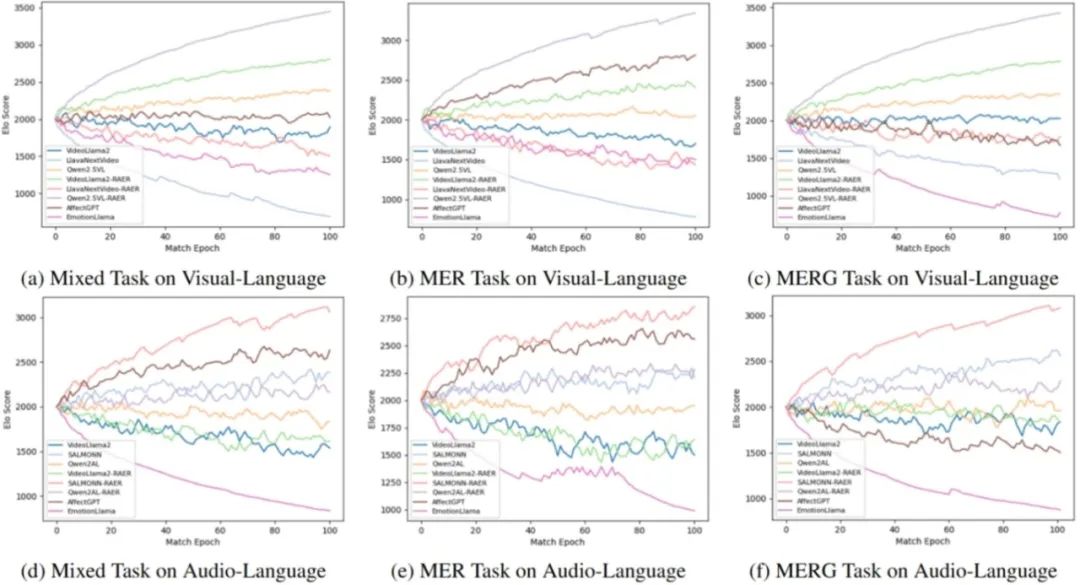
图2. SAB实验结果
41. Know-MRI:面向大模型知识机理的综合性解释工具
Know-MRI: A Knowledge Mechanisms Revealer&Interpreter for Large Language Models
作者:刘佳翔,邢博轩,袁晨皓,张陈祥,吴迪,黄修胜,于海达,郎楚涵,曹鹏飞,赵军,刘康
录用类型:System Demonstrations Papers
随着大型语言模型(LLMs)的不断发展,提升其内部知识机制的可解释性变得愈发紧迫。因此,许多解释方法应运而生,试图从不同角度揭示LLMs的知识机制。然而,当前的解释方法在输入数据格式和输出结果形式上存在差异,整合这些方法的工具通常只能支持特定输入的任务,极大地限制了其实用性。
为了解决这些问题,我们提出了一个开源工具——Knowledge Mechanisms Revealer & Interpreter(Know-MRI),旨在系统性地分析LLMs的知识机制。具体来说,我们开发了一个可扩展的核心模块,能够自动匹配不同的输入数据与解释方法,并整合解释输出。该工具使用户能够根据输入自由选择合适的解释方法,从而更方便地从多个角度对模型的内部知识机制进行全面诊断。
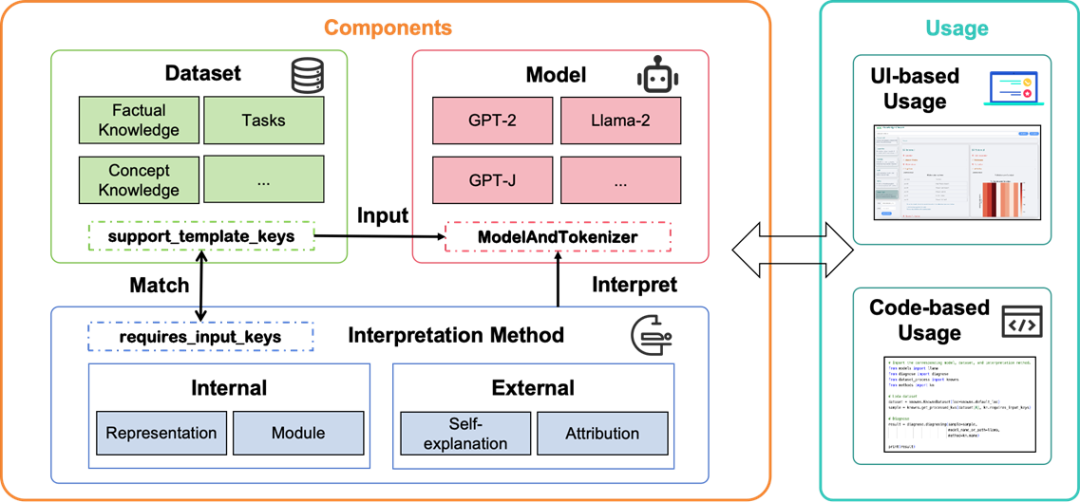
图1. Know-MRI框架图
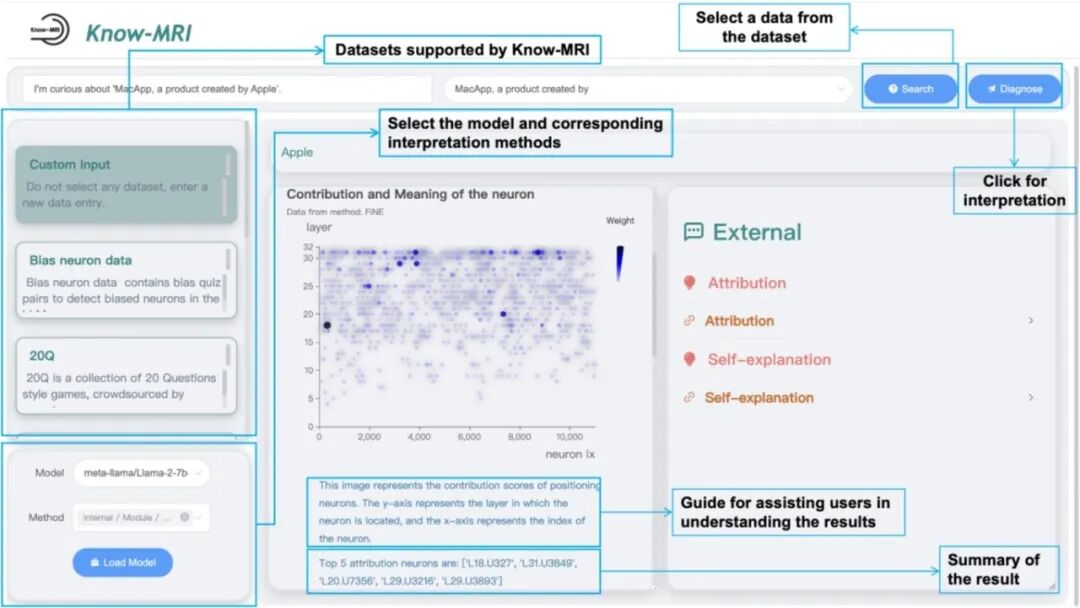
图2. Know-MRI交互界面
42. CiteLab—基于人机交互的引用生成工作流开发与诊断
CiteLab: Developing and Diagnosing LLM Citation Generation Workflows
作者:沈佳俊,周桐,陈玉博,刘康,赵军
录用类型:System Demonstrations Papers
我们注意到,目前利用大语言模型在问答任务中生成引用的方法,因缺乏统一框架来标准化和公平比较,导致了复现和创新上的困难。
为解决这一问题,我们推出了一个名为Citeflow的开源模块化框架。它旨在促进引用生成方法的复现和新设计的实现。Citeflow具有高度的可扩展性,用户可以通过其四大模块和十四个组件来构建、评估引用生成流程,并更好地理解LLM生成的归因内容。
同时,我们还开发了一个可视化的界面Citefix,与Citeflow紧密配合。它能帮助用户轻松地进行案例研究,并对现有方法进行修改。通过这个界面,用户可以根据不同场景开展由人机交互驱动的案例研究。Citeflow和Citefix共同整合在我们的工具包CiteLab中,我们通过一个真实的人机交互多轮改进过程,展示了该工具包在实现和修改引用生成流程方面的显著效率。
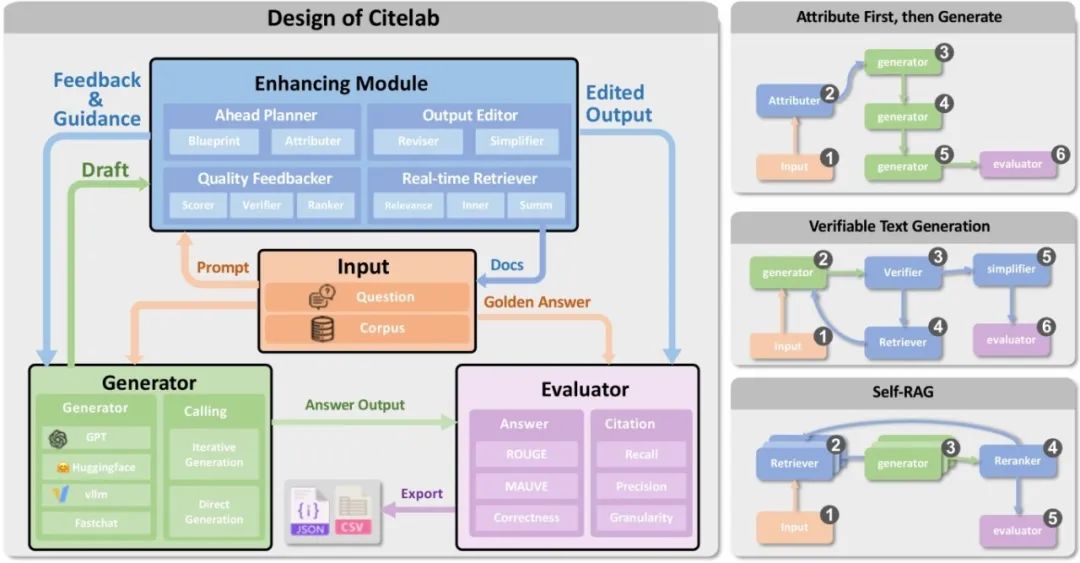
图1. Citelab的模块化设计(左)和部分工作流实现(右)
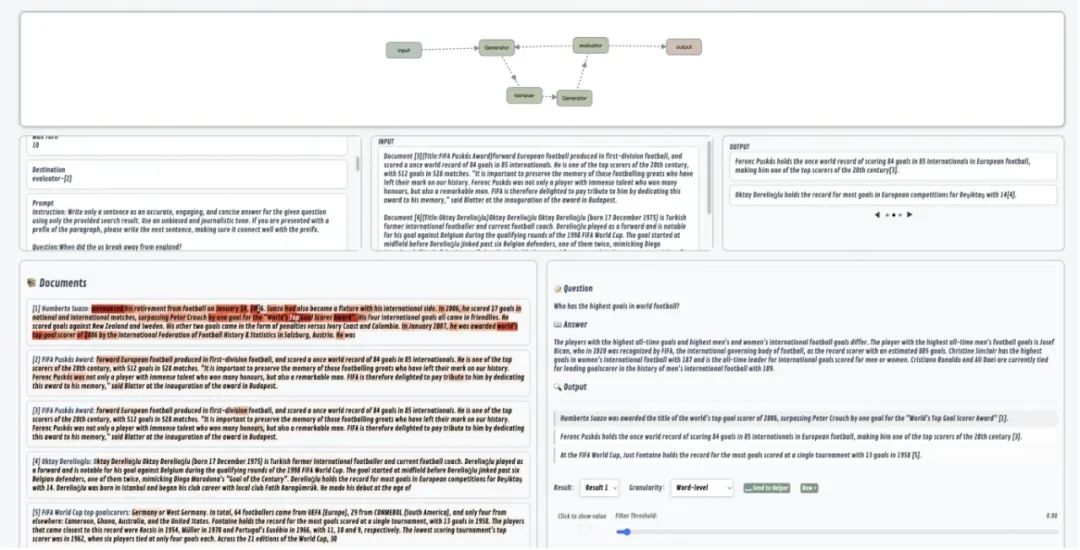
图2. Citelab的可视化交互界面