随着全球科研范式加速重塑,“人工智能+科学”正进入以数据驱动的跨越式发展阶段。无论是实现科研自动化、提升知识发现效率,还是构建具备高级推理能力的科学基础模型,科学多模态理解能力正成为决定性要素。
然而,科学图像蕴含复杂结构、实验逻辑与物理机制,文本则包含公式符号、变量指代、背景知识与严谨论证。由于缺乏规模化、专业化、结构化的数据基础,现有多模态模型在真实科研任务中常常难以准确解读实验结果或复现科研逻辑。
中国科学院自动化研究所磐石·科学基础大模型团队正式发布并开源磐石·科学多模态语料库S1-MMAlign 1.0,为科学基础模型打造坚实的数据基础。
S1-MMAlign 1.0:大规模科学多模态语料库
科研场景中的图文理解,并非简单的“看图”或“读句子”,而是需要跨越图像、文本、变量、结构、假设、推断等多层语义关系。要推动科学智能的发展,必须从数据端补齐这一关键短板。
S1-MMAlign 1.0以真实科研语境为基础进行构建,是覆盖了超 1550万高质量图文对、250万篇科研论文的大规模科学多模态语料库,也是目前国内已知覆盖学科最广、规模最大、结构体系最完善的科学多模态数据资源之一。
该语料库覆盖数学、物理、化学、生物、天文、地球科学、医学、工程学、计算机科学等主要学科,系统整理科研图像、标题、正文上下文与图注在内的多层结构化信息,为科学多模态模型提供了前所未有的学科广度与语义深度。
全学科、多类型的科学多模态数据
S1-MMAlign首次系统性地弥合了超大规模科学文本与科学图像之间的跨模态语义鸿沟。数据集所涵盖的科研图像横跨多种尺度,从原子能级变化、晶体衍射等微观机制,到材料形貌与生命过程的中尺度结构,再到地球环境与天文观测等宏观现象,构成了科学研究中高度多样化的视觉体系。
与此同时,S1-MMAlign还收录了科研活动不同阶段的典型图文表达,包括理论建模示意图、实验流程与装置结构、观测场景等,使科学推理链条中“如何提出假设—如何设计实验—如何解释结果”的核心语义结构得以完整呈现。
所有数据均来自具有开放获取许可(Open Access)的科研文献数据库及公开发布的期刊会议论文。研究团队通过大规模文献处理流水线,对标题、摘要、图注及其引用上下文进行了细粒度的结构化抽取,最大限度保留科研表达中的逻辑关联、变量指代和推理线索。这些高质量对齐信号,使模型能够学习跨模态、跨任务、跨领域的知识迁移路径,为构建具备科研理解能力的多模态模型打下坚实而系统的语义基础。
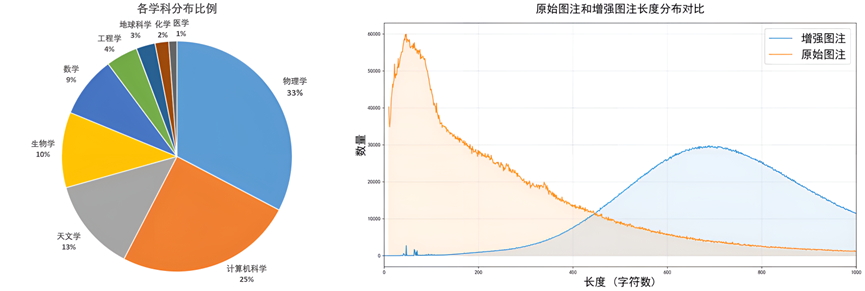
图1.学科分布以及原始图注和增强图注长度分布对比
AI-Ready的图注语义增强策略
科研论文中的原始图注往往存在描述过短、关键信息缺失、上下文不足、逻辑链条不完整、专业性不均衡等天然缺陷,使多模态模型难以完整理解科研图像背后的实验含义。为解决这一长期痛点,研究团队基于多模态大模型体系构建了面向科研语境的自动语义增强机制,并对全部1550万条图注进行了系统化增强解读。
该增强策略综合利用引用上下文、摘要背景与原始图注内容,在严格保持图像科学含义的前提下,自动补全并规范化图像细节、关键结构、实验流程、趋势变化与隐含推理关系等信息,使图文对应关系更加显性、科学语义更加饱满、语言逻辑更加严谨。
增强后的图文语料为多模态大模型提供了更稳定、更加明确的跨模态对齐信号,使模型在大规模训练中能够习得真实科研任务所需的科学认知能力与推理能力。
多维核心能力的系统性提升
为验证语义增强策略的真实效益,研究团队围绕语言一致性与图文匹配能力进行了系统评测。
在科研文本维度,基于SciBERT的pseudo-PPL指标观察到显著下降,同时高困惑度长尾样本也明显减少。困惑度的降低表明增强文本并非趋同化,而是使实验条件、变量指代、科学论述链等关键信息的呈现更加完整、显性,并减少语义缺口。这一变化使得文本的统计结构更容易被模型捕捉,从而提升跨模态对齐时的语言侧可学习性。
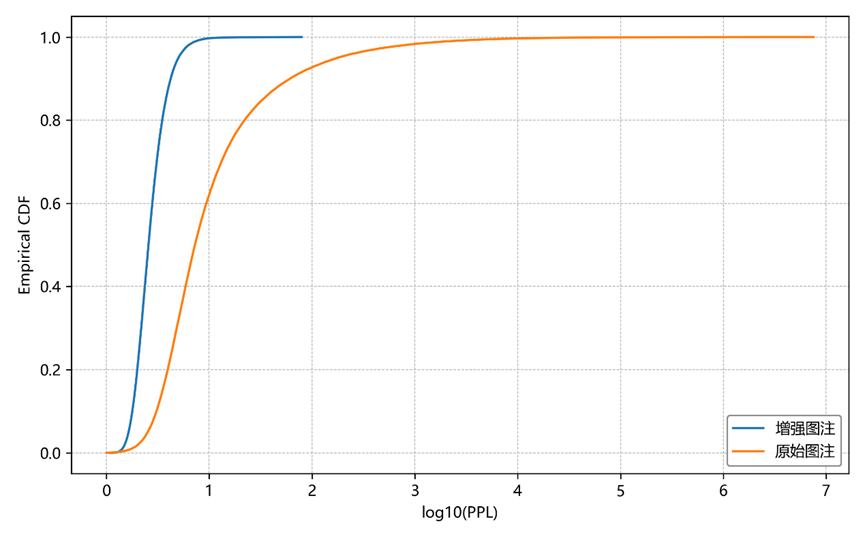
图2. 文本质量经验累积分布曲线。横坐标为log₁₀(pseudo-PPL),表示基于 SciBERT 掩码语言模型计算得到的文本困惑度水平;纵坐标为经验累积分布值。
在图文一致性方面,基于CLIP的语义对齐评测表明,增强后的图文相似度均值提升18.21%,整体分布右移并伴随约27.77% 的方差收缩。这一变化说明增强文本能够提供更明确的跨模态关联线索,使图像中的关键结构、变量与实验语义在文本侧得到更稳定的对应表达,从而提升模型在对齐阶段的信号质量与训练稳健性。
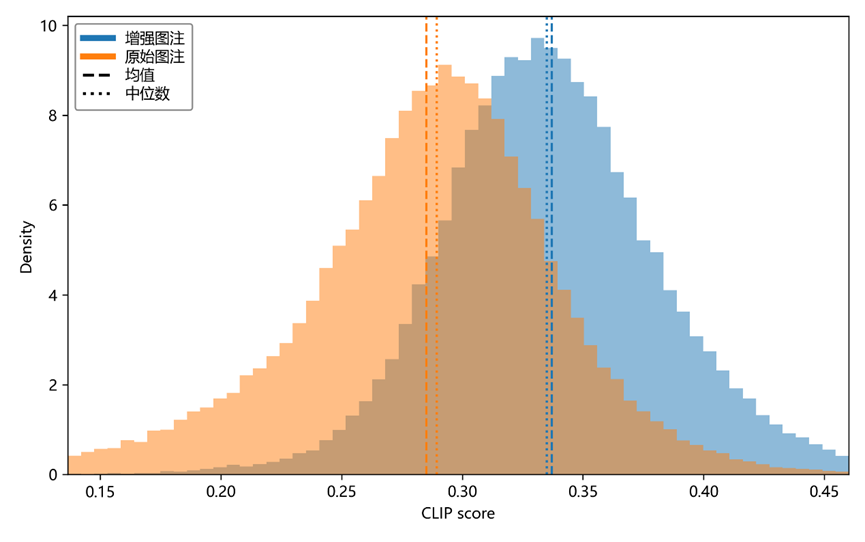
图3. CLIP图文一致性得分分布。横坐标为CLIP余弦相似度,纵坐标为概率密度。
人工审核结果进一步验证了评测趋势。在术语使用、实验语义还原度、变量指代准确性、可读性以及图文一致性等五项指标中,增强文本均获得超过90%的正向评价。
目前,磐石·科学多模态语料库已作为核心基础融入“磐石·科学基础大模型”的训练体系,在实验结果理解、科学图像解析、论文辅助阅读与科研流程自动化等典型任务中提供关键数据支撑。未来,团队将持续拓展S1-MMAlign在更多学科领域的深度覆盖,并进一步优化数据质量与跨模态结构设计,推动我国在科学智能核心技术方向取得持续进展。