近日,自动化所智能感知与计算研究中心提出一种新的深度生成模型——自省变分自编码器(Introspective Variational Autoencoder,IntroVAE),用来实现高清图像等高维数据的无条件生成(unconditional generation)。该模型一方面在不引入额外的对抗判别器的情况下,克服了变分自编码器固有的合成图像趋于模糊的问题;另一方面在不使用常用的多阶段多判别器策略下,实现了高分辨率图像合成的稳定训练。实验结果表明,该模型不仅能够稳定生成高分辨率照片级图像(比如1024x1024的人脸图像),而且在生成模型常用的量化指标上取得了目前最好的结果。该论文目前被人工智能顶级会议神经信息处理系统大会(NIPS2018)收录。
深度生成模型是无监督学习最有前景的方法之一,一直是学术界研究的热点问题。目前最为流行的两种深度生成模型是变分自编码器(VAEs)和对抗生成网络(GANs)。变分自编码器是自动编码器的生成版本,通过优化一个变分下界来实现数据到先验分布的近似映射。VAEs的训练稳定,能够进行隐变量推断和对数似然估计,但是生成的样本比较模糊。对抗生成网络通过生成器和判别器之间的对抗,来学习真实数据的分布。GANs可以生成逼真的清晰图像,但是存在训练不稳定的问题,这个问题在合成高分辨率图像上尤其严重。
高分辨率真实图像的生成由于问题困难,计算复杂度大,一直以来只有英伟达(INVIDIA)、麻省理工(MIT)等知名科研机构在研究。目前主流的高分辨率图像合成方法(比如英伟达公司提出的PGGAN模型)通过将高分辨率图像分解,从低分辨率出发,分多个阶段使用多个判别器逐步合成高分辨率图像。这种训练方式增加了模型设计的复杂度,提高了模型收敛的难度。与已有的方法不同,本文采用了一种更为简单有效的方式,能够实现对高分辨率图像的一步到位直接合成。该方法将对抗学习引入VAE内部,实现了一种自省的学习,即模型自身能够判断其生成样本的质量并作出相应改变以提高性能。具体的实现方式是训练编码器使得真实图像的隐变量接近先验分布,合成图像的隐变量偏离先验分布;与之相反的是,训练生成器使得合成图像的隐变量接近先验分布。同时,与GAN不同的是,编码器和生成器除了对抗外还要协同保证对输入图像的重建误差尽量小。对于真实数据来说,该方法的训练目标跟传统VAE完全一致,这极大得稳定了模型训练;对于合成数据来说,对抗的引入提高了样本的质量。
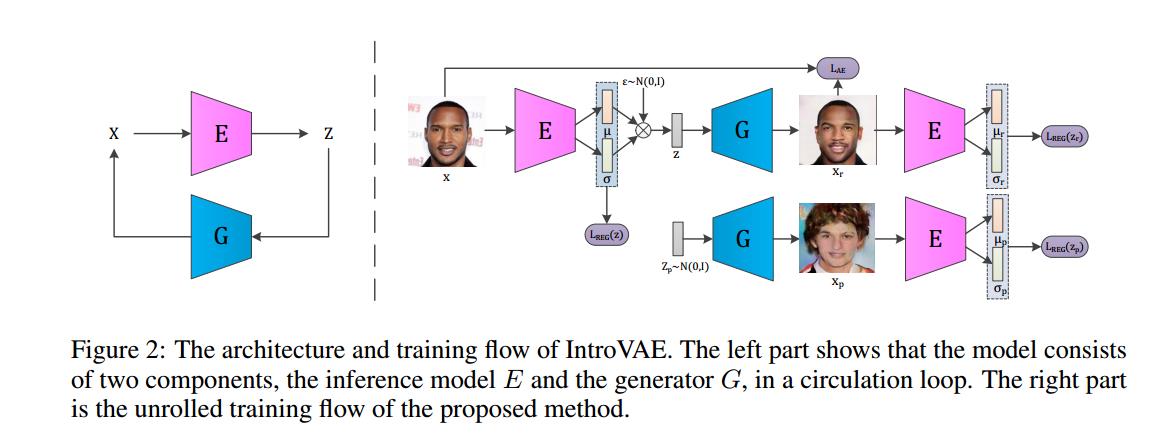
IntroVAE的体系结构与训练流程
实验结果显示,自省变分自编码器能够稳定合成高分辨率照片级的图像,比如1024x1024大小的人脸图像,256x256大小的卧室、教堂、狗等自然图像。该模型不仅在图像质量上,而且在量化指标上都取得了当前最好的结果。