解码人类视觉神经表征是一项具有重要科学意义的挑战,可以揭示视觉处理机制并促进脑科学与人工智能的发展。然而,目前的神经解码方法难以泛化到训练数据以外的新类别,主要挑战在于现有方法未充分利用神经数据背后的多模态语义知识,且现有的可利用的配对(刺激-脑响应)训练数据很少。
近日,中科院自动化所神经计算与脑机交互团队将大脑、视觉和语言知识相结合,通过多模态学习实现了从人类脑活动中零样本地解码视觉新类别。相关研究成果以Decoding Visual Neural Representations by Multimodal Learning of Brain-Visual-Linguistic Features为题发表于IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI)。人类对视觉刺激的感知和识别受到视觉特征和人们先前经验的影响,例如当人们看到一个熟悉的物体时,大脑会自然而然地检索与该物体相关的知识,如图1所示。基于此,本研究提出“脑-图-文”三模态联合学习框架,在使用实际呈现的视觉语义特征的同时,加入与该视觉目标对象相关的更丰富的语言语义特征,以更好地解码脑信号。
该研究证明,从人脑活动中解码新的视觉类别是可以实现的,并且精度较高;使用视觉和语言特征的组合比仅使用其中之一的解码表现更好;在人脑语义表征过程中,视觉加工会受到语言的影响。
相关发现不仅对人类视觉系统的理解有所启示,也有望为脑机接口技术提供新思路。研究团队介绍,本工作提出的方法具有三个方面的潜在应用:作为一种神经语义解码工具,此方法将在新型读取人脑语义信息的神经假肢设备的开发中发挥重要作用,可为其提供技术基础;作为神经编码工具,通过跨模态推断脑活动,用于研究视觉和语言特征如何在人类大脑皮层上表达,揭示哪些脑区具有多模态属性(即对视觉和语言特征敏感);作为类脑特性评估工具,测试哪个模型的(视觉或语言)表征更接近于人类脑活动,从而激励研究人员设计更加类脑的计算模型。
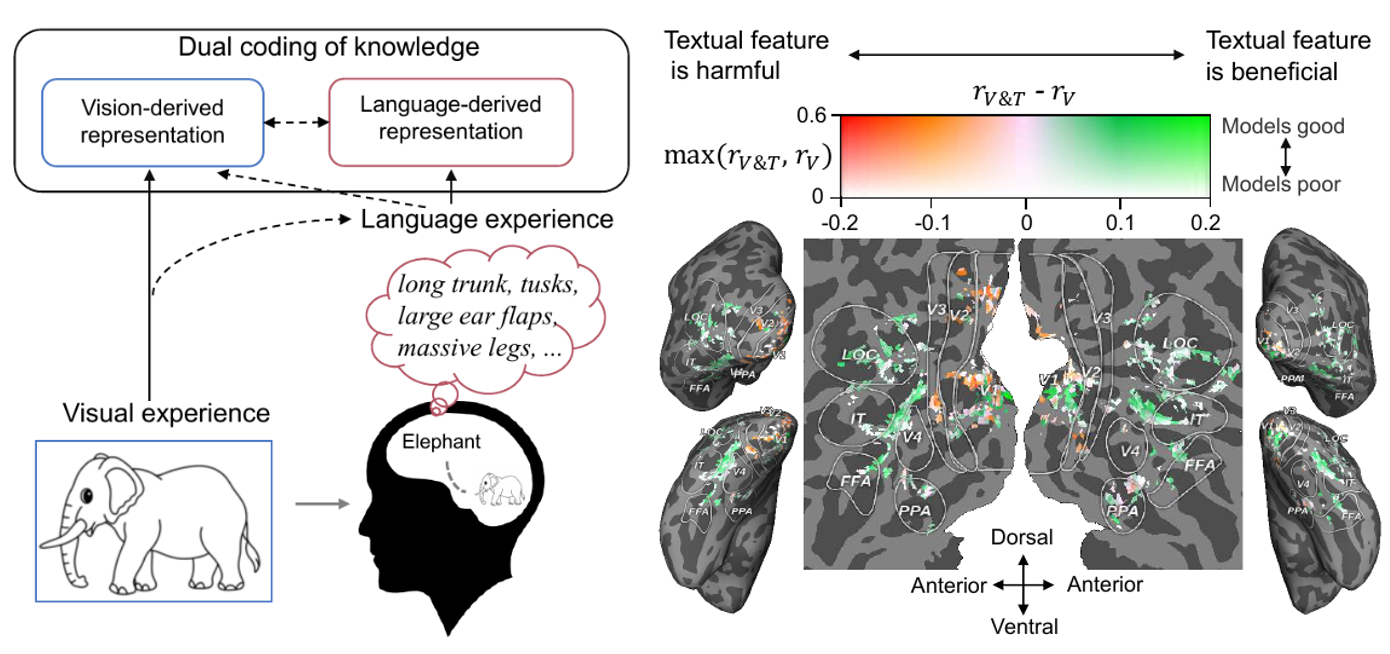
图1.人类大脑中的知识双重编码。当看到大象的图片时,我们会自然地在脑海中检索到大象的相关知识(如长鼻子,长牙齿,大耳朵等)。此时,大象的概念会在大脑中以视觉和语言的形式进行编码,其中语言作为一种有效的先前经验,有助于塑造由视觉产生的表征。
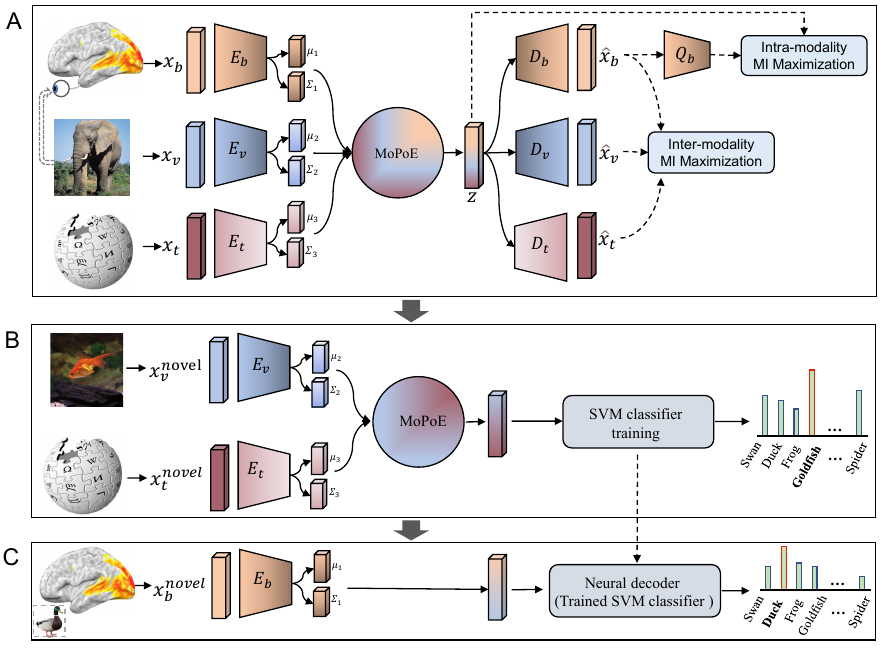
图2.本文提出的“脑-图-文”三模态联合学习框架,简称BraVL
该论文第一作者为中国科学院特别研究助理杜长德,通讯作者为何晖光研究员。研究工作得到了科技部科技创新2030—“新一代人工智能”重大项目、基金委项目、中国科学院自动化研究所2035创新任务以及CAAI-华为MindSpore学术奖励基金及智能基座等项目的支持。为促进该领域的持续发展,研究团队已将代码和新收集的三模态数据集开源。
论文地址:https://ieeexplore.ieee.org/document/10089190