AAAI(AAAI Conference on Artificial Intelligence) 由国际先进人工智能协会主办,是人工智能领域的顶级国际学术会议之一。第39届AAAI人工智能年度会议将于2025年2月在美国宾夕法尼亚州费城召开。
01. 一种用于对手建模的开放式学习框架
An Open-Ended Learning Framework for Opponent Modeling
作者:景煜恒,李凯,刘秉运,傅浩波,付强,兴军亮,程健
对手建模(Opponent Modeling,OM)旨在通过建模多智能体环境中的其他智能体来增强决策能力。现有研究通常在训练阶段针对预设的一组固定对手学习对手模型。然而,这种方法在测试时面对未知对手时会导致较差的泛化能力,因为未见过的对手可能表现出分布外(out-of-distribution,OOD)的行为,这些行为是已学习的对手模型无法处理的。为解决这一问题,我们提出了一种新颖的开放式对手建模(Open-Ended Opponent Modeling,OEOM)框架,该框架通过持续生成具有多样性强度和风格的对手,降低测试时出现OOD情况的可能性。OEOM以基于种群的训练和信息论轨迹空间多样性正则化为基础,动态生成一组对手。然后,这组对手被用于任意OM方法中,以训练潜在具有泛化能力的对手模型。在此基础上,我们进一步提出了一种简单但有效的OM方法,该方法自然契合OEOM框架,基于上下文强化学习,学习一个Transformer模型,能够根据对手的轨迹动态识别并做出响应。在协作、竞争及混合环境中的大量实验表明,OEOM是一个与方法无关的框架,无论使用何种OM方法或测试对手设置,都能提升泛化能力。此外,实验结果还表明,我们提出的方法通常优于现有的OM基线方法。

OEOM的迭代过程
02. 基于隐式奖励建模的大语言模型人类偏好顺序对齐
Sequential Preference Optimization: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
作者:娄行舟,张俊格,谢剑,刘立峰,阎栋,黄凯奇
SPO算法分多阶段实现LLM在存在潜在冲突的多目标上的对齐。解决了现实世界中数据集一般都是分多维度标注,最后再统一进行偏好排序带来的信息损失问题。通过在对齐优化问题中引入针对前序对齐目标的保持约束,SPO实现了大语言模型在多个目标上的顺序对齐,并且从理论上保证在优化新的目标时,不会遗忘前序目标的对齐。同时,SPO相比单轮训练实现全目标对齐的算法,只要多维度对齐目标所需的能力不冲突,哪怕不同维度上数据偏序关系冲突较大,SPO也可以实现良好的对齐。
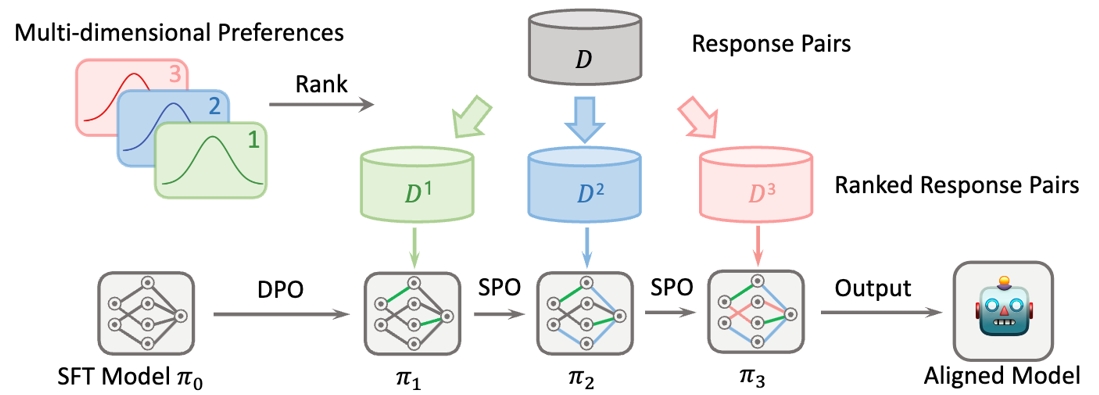
SPO算法流程图,按顺序实现大语言模型多个目标的对齐,且不会发生灾难性遗忘
03. 利用注意力机制高效压缩长上下文大语言模型的提示
Leveraging Attention to Effectively Compress Prompts for Long-Context LLMs
作者:赵云龙,吴浩然,徐波
处理长上下文是大语言模型(LLMs)面临的一大挑战,特别是在提示词长度过长时,会显著增加计算开销,无关内容也会影响模型性能,因此提示词压缩成为了近年来研究的一个关注点。当前的提示词压缩方法主要依赖信息熵,但存在两个关键挑战:信息熵度量不一定最优 和 独立性假设导致上下文语义丢失。为解决这些问题,本文提出一种利用语言模型内在注意力进行提示词压缩的方法 AttnComp。AttnComp 使用查询引导的跨注意力来评估每个 token 的重要性,并通过基于图的算法对 token 进行聚类,生成语义单元,缓解独立性假设带来的问题。实验结果显示,AttnComp 方法在检索增强生成(RAG)和文档问答等任务中表现优于现有基线压缩方法。这项工作不仅提高了 LLM 长文本处理的效率,还为提示词压缩研究提供了新的思路,展示了LLM的注意力在上下文理解中的作用。
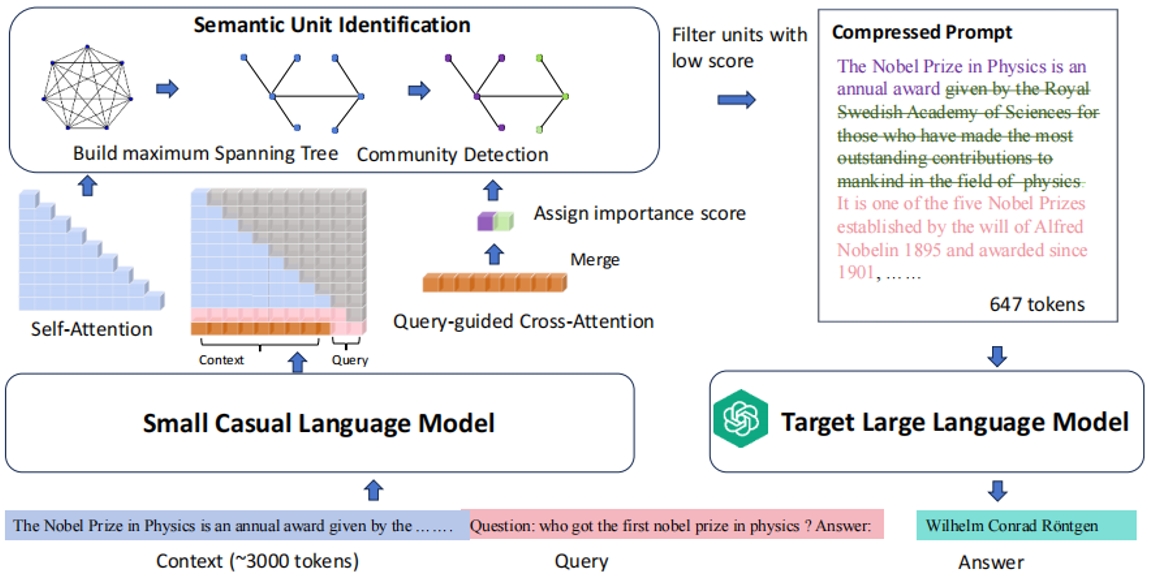
方法框架
04. 基于自适应预训练视觉编码器的高效强化学习算法
Efficient Reinforcement Learning through Adaptively Pretrained Visual Encoder
作者:张予涵(共一),马国庆(共一),郝光福,郭良轩,陈阳,余山
虽然强化学习(RL)智能体能够成功学习复杂的任务,但泛化这些技能到新环境仍然具有挑战性。这背后的原因之一是所使用的视觉编码器是任务相关的,使得在不同环境下的特征提取受限。为了解决这一问题,我们提出了APE:一种通过自适应预训练视觉编码器来实现高效强化学习的框架。实验结果表明,配备APE的主流RL算法在多个环境中均实现了一定的性能提升,并显著提高了原有算法的学习效率。在仅使用视觉信息的情况下,其性能接近基于状态输入的策略。这展示了编码器自适应预训练在提升视觉强化学习泛化能力和效率方面的潜力。
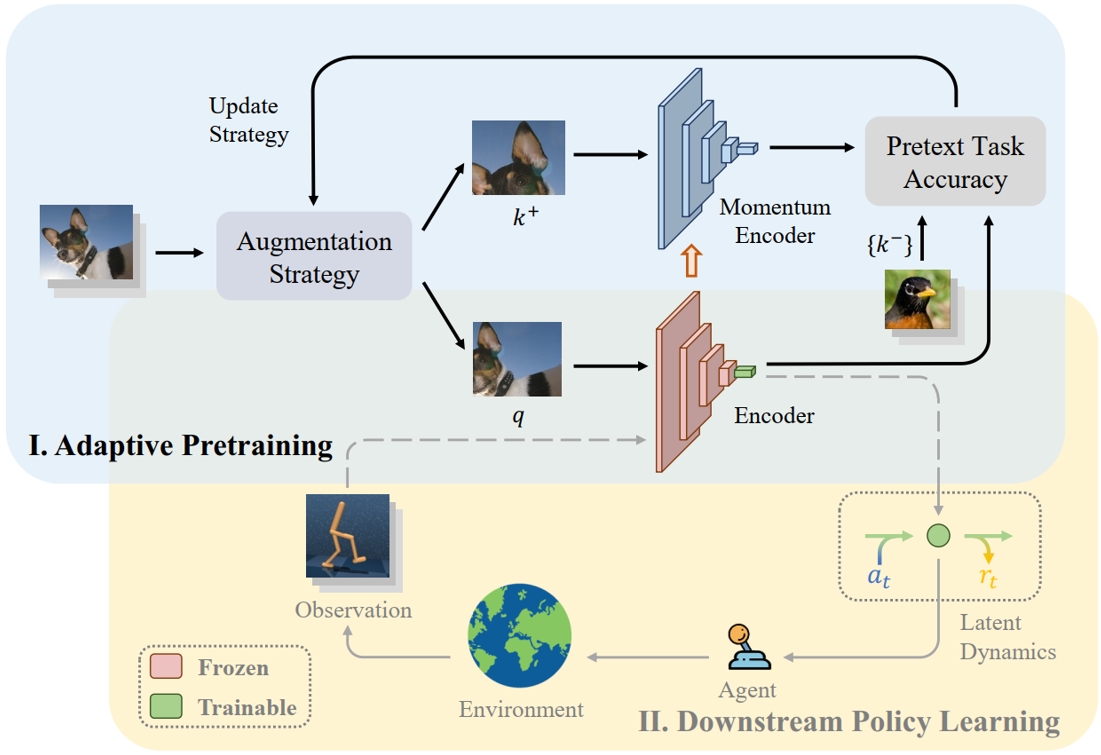
用于基于模型的强化学习的APE框架。训练阶段分为两个部分,分别是自适应预训练阶段(蓝色区域)和下游策略学习阶段(黄色区域)。在第一个阶段中,使用自适应数据增强策略对各种现实场景中的图像进行增强,该策略在下一个预训练周期中动态更新每个增强集合的采样概率。在第二阶段,将预训练的视觉编码器作为策略的感知模块应用于通用RL算法框架中。
05. 基于多模态隐变量的跨个体初级视觉皮层建模和分析
Multi-Modal Latent Variables for Cross-Individual Primary Visual Cortex Modeling and Analysis
作者:朱宇,雷博,宋纯锋,欧阳万里,余山,黄铁军
在系统神经科学领域中,理解初级视觉皮层(V1)的功能机制仍然是一个基本挑战。当前的计算模型面临两个关键限制:一是部分神经记录与复杂视觉刺激之间跨模态整合的挑战,二是个体间神经特征的固有差异,包括神经元群体和发放模式的差异。为了应对这些挑战,我们提出了一个多模态可识别变分自编码器(miVAE),它采用两级解耦策略将神经活动和视觉刺激映射到统一的潜在空间。该框架通过精细的潜在空间建模,实现了跨模态相关性的稳健识别。我们还配合使用了一种新颖的基于得分的归因分析方法,用于追踪潜在变量回溯到源数据空间的来源。在大规模小鼠V1数据集上的评估表明,我们的方法在跨个体潜在表征和对齐方面达到了最先进的性能,且无需针对特定个体进行微调,并且随着数据规模的增加表现出更好的性能。值得注意的是,我们的归因算法成功识别出具有独特时间模式和刺激辨别特性的不同神经元亚群,同时揭示了对边缘特征和亮度变化具有特定敏感性的刺激区域。这个可扩展的框架不仅为推进V1研究提供了有前景的应用,也为更广泛的神经科学研究提供了新的可能。
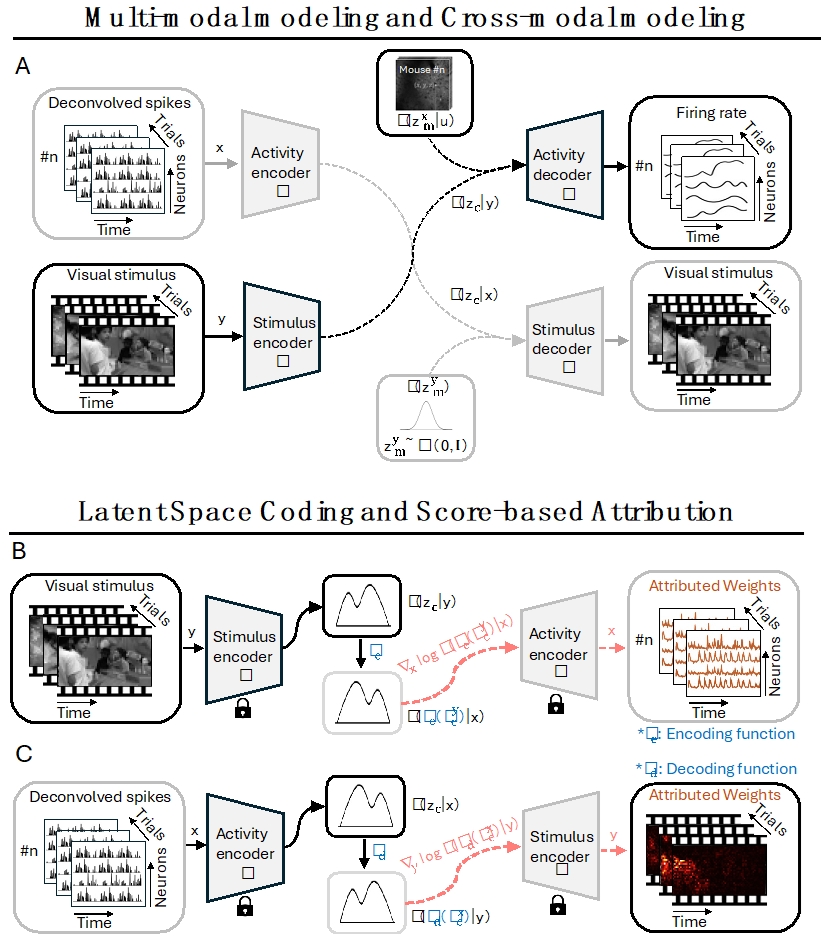
06. EventZoom:用于增强神经形态视觉任务的渐进式事件数据增强方法
EventZoom: A Progressive Approach to Event-Based Data Augmentation for Enhanced Neuromorphic Vision
作者:董一廷,何翔,申国斌,赵东城,李杨,曾毅
动态视觉传感器(DVS)以高时间分辨率和低功耗捕获事件数据,相比传统的视频获取方法,在动态和实时场景中提供了更高效的解决方案。事件数据增强作为克服事件数据集规模和多样性限制的方法,对于提升模型的性能至关重要。对比实验表明,空间完整性和时间连续性这两个因素显著影响事件数据增强的能力,它们是保持事件数据特有稀疏性和高动态范围特征的保证。然而,现有的增强方法通常忽视了这两个因素。我们开发了一种全新的事件数据增强策略—EventZoom,该策略采用时序渐进策略,通过渐进式的缩放和平移将变换样本嵌入原始样本中。缩放过程避免裁剪带来的空间信息丢失,而渐进策略则防止时序信息的中断或突变。我们在多种监督学习框架中验证了EventZoom。实验结果表明,EventZoom在性能上始终优于现有的事件数据增强方法,达到最先进的水平。我们首次同时采用半监督和无监督学习来验证事件增强算法的可行性,展示了EventZoom在处理具有高动态性和多变性环境的实际场景中的适用性和有效性。
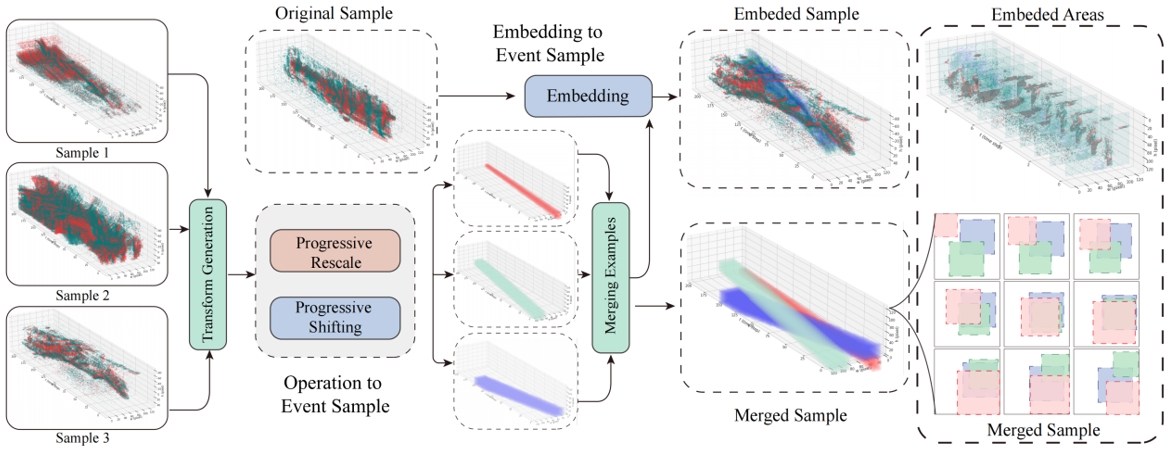
EventZoom的数据增强过程。事件样本1-3经过了沿时间维度的渐进式缩放和平移,缩放后的样本被嵌入到原始样本中。
07. StressPrompt: 压力是否对大型语言模型和人类表现产生类似的影响?
StressPrompt: Does Stress Impact Large Language Models and Human Performance Similarly?
作者:申国斌,赵东城,包傲日格乐,何翔,董一廷,曾毅
人类常常会面临压力,而压力会显著影响其表现。本研究探讨了大型语言模型(LLMs)是否会展现与人类类似的压力反应,以及其在不同压力诱导情境下的表现波动情况。为此,我们设计了一套名为StressPrompt的全新提示集,旨在诱导不同程度的压力。这些提示基于公认的心理学理论框架,并经过人类参与者的评分校准后精心调整。随后,我们将这些提示应用于多个LLMs,评估其在包括指令执行、复杂推理和情感智能等任务中的表现。研究结果显示,LLMs与人类类似,在中等压力下表现最佳,这与Yerkes-Dodson法则相一致。而在低压力或高压力条件下,其表现均有所下降。此外,分析表明,这些StressPrompt会显著改变LLMs的内部状态,导致其神经表征发生变化,这种变化与人类面对压力时的反应相似。本研究为LLMs的操作稳健性和灵活性提供了重要见解,强调了在客户服务、医疗保健和紧急响应等高压力的真实世界场景中,设计能够保持高性能的AI系统的重要性。同时,本研究为更广泛的AI研究领域提供了新视角,深入探讨了LLMs如何应对不同情境及其与人类认知的相似性。
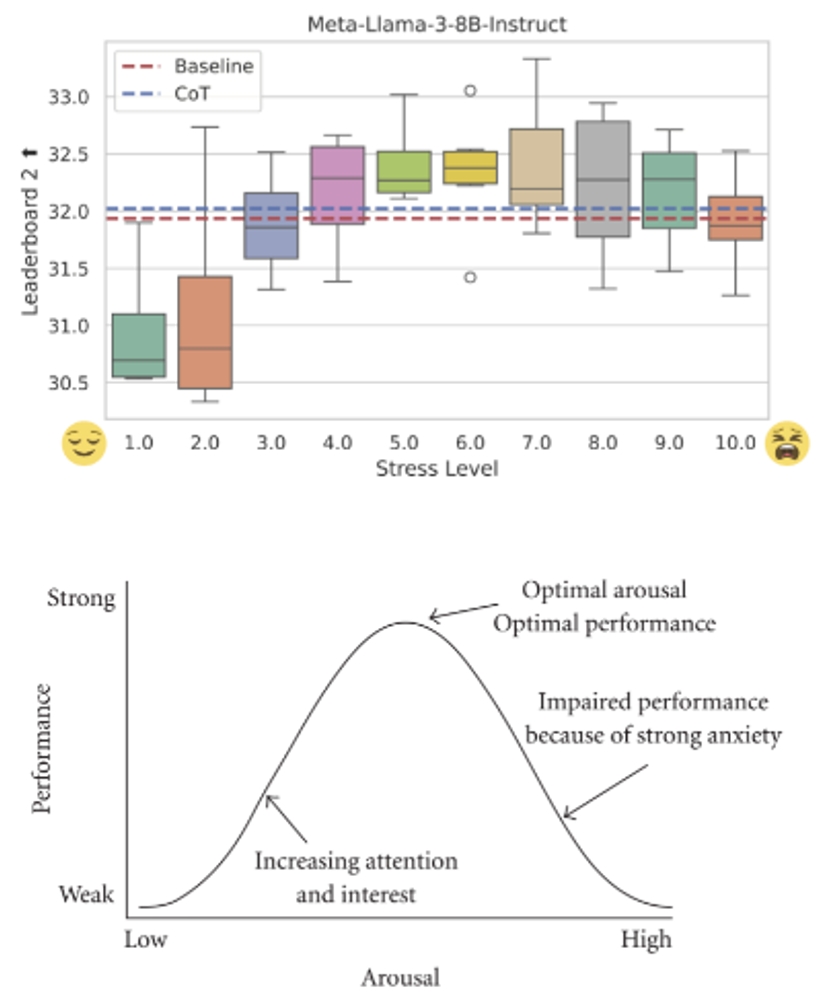
对比 LLM 和人类在不同压力水平下的表现: (a) Llama-3-8B-Instruct在不同压力水平下的 Leaderboard 2 基准测试表现。(b) Yerkes-Dodson 法则示意图:人类表现随压力水平变化,在中等压力下达到峰值,而在低压力或高压力下下降。(https://en.wikipedia.org/wiki/Yerkes–Dodson_law)
08. SceneX: 程序化可控的大规模场景生成
SceneX: Procedural Controllable Large-scale Scene Generation
作者:周梦琪,王玉玺,侯俊,张守高,李奕威,罗传琛,彭君然,张兆翔
为了创建逼真、可控的大规模3D场景,我们拟采用大语言模型(LLM)来驱动程序化内容生成技术进行场景建模。我们提出一个大规模场景生成框架SceneX,它可以根据设计师的文本描述以及多模态的输入自动生成高质量的3D场景,具体而言,SceneX包含两个组件,PCGHub和PCGPlanner。前者包含大量可访问的程序化生成资产、高质量的静态资产和数千个资产API文档,后者旨在为Blender生成可执行的操作,从而根据用户的指令生成可控且精确的3D资产。此外,为了能够低成本、高效地容纳复杂多样的PCG,我们拟设计一个可以集成各种 PCG 插件的通用协议作为连接LLM和Blender的桥梁(图1)。
PCGHub是一个集成了多种PCG模块和3D资产的平台。它提供了详细的文档和应用程序接口,可快速集成各种 PCG 技术,解决传统程序化生成方法的局限性,提高内容的逼真度。
PCGPlanner利用PCGHub提供的资源,通过引入Multi-Agent的多代理框架,可以自动根据用户的文本描述生成高质量、大规模的场景。
实验结果表明,SceneX能够根据设计师的文本描述,自动生成高质量的3D场景,使用户能够通过简单的文本描述快速创建复杂的3D环境,包括自然风景和城市场景等。(图2)。
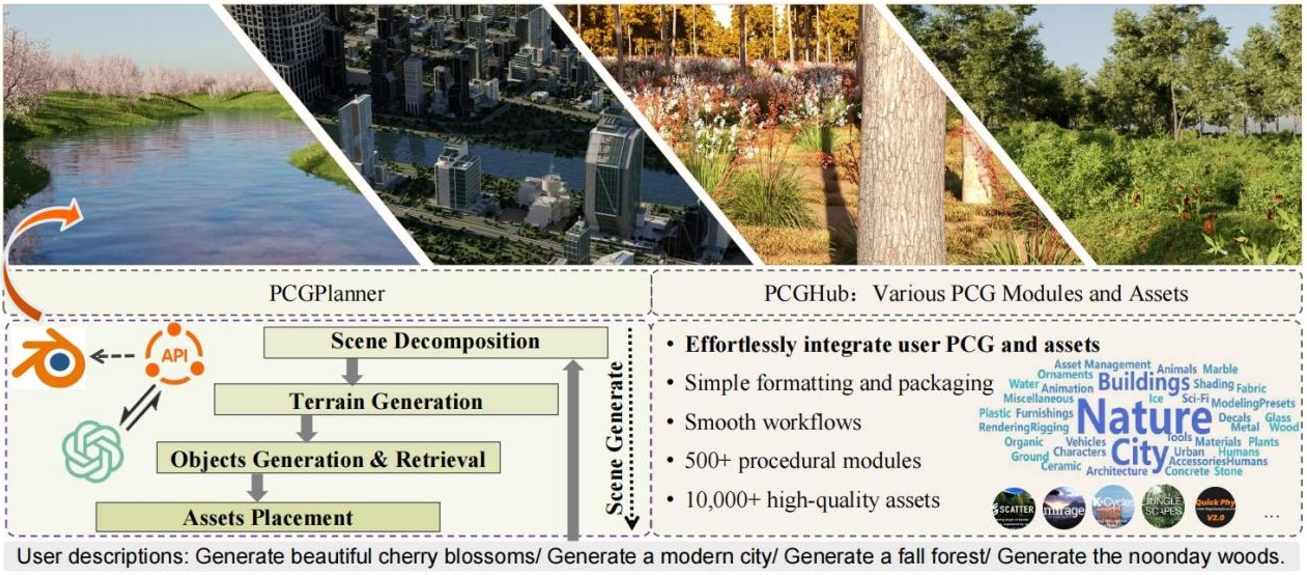
图1. 提出的SceneX可根据用户指令自动创建大规模三维自然场景或无边界城市。生成的模型具有精致的几何结构、逼真的材质纹理和自然的色彩。生成的模型具有精致的几何结构、逼真的材料纹理和自然的光照,可以在工业管道中无缝部署。

图2. 自然场景和城市场景的可视化结果
09. 探索标签偏移联邦学习中的空缺类别
Exploring Vacant Classes in Label-Skewed Federated Learning
作者:郭况浦,丁雨禾,梁坚,王子磊,赫然,谭铁牛
标签偏移,指的是客户端之间局部标签分布的不均衡,给联邦学习带来了显著挑战。由于少数类在本地不平衡数据上容易过拟合,导致其准确率较低,先前的方法通常在本地训练时引入了类平衡学习技术。尽管这些方法提高了所有类的平均准确率,但我们观察到“空类”(即在某个客户端的数据分布中缺失的类别)仍然难以被识别。签分布的不均衡,给联邦学习带来了显著挑战。此外,本地模型在少数类的准确率与全局模型相比仍存在差距。本文提出了FedVLS,一种结合空类蒸馏和logit抑制的标签偏移联邦学习新方法。具体而言,空类蒸馏通过在每个客户端的本地训练中应用知识蒸馏,从全局模型中保留与空类相关的重要信息。此外,logit抑制直接对非标签类别的网络logits施加惩罚,有效地解决了少数类可能偏向于多数类的误分类问题。大量实验验证了FedVLS的有效性,结果表明,相较于现有的最先进方法,FedVLS在多个数据集和不同程度标签偏斜的情况下表现出更优越的性能。
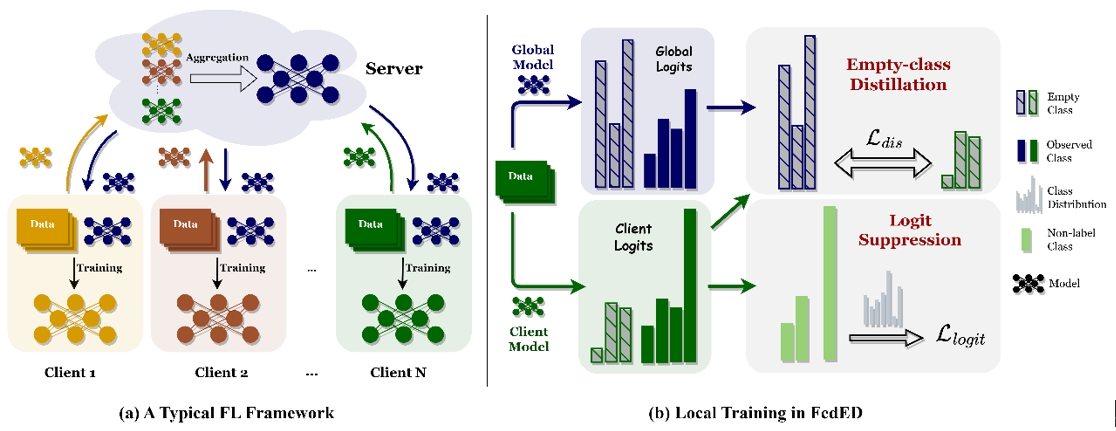
图1.(a)代表典型联邦学习的总体框架。(b)展示了我们在本地训练期间应用的方法。
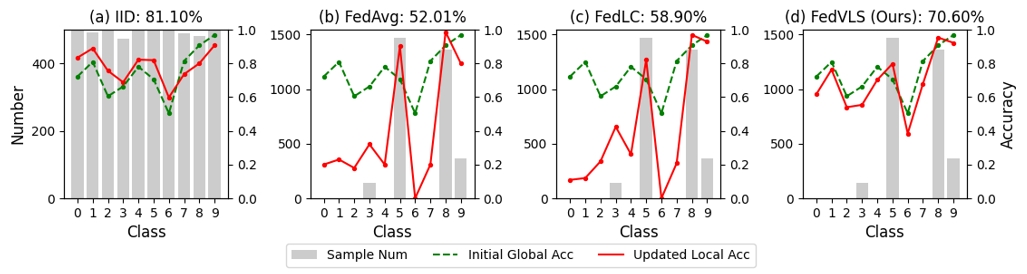
图2.初始全局模型和更新后的局部模型在 IID 和标签偏移的 CIFAR10 数据分布上的类别准确率。(a) 表示使用 FedAvg 对 IID 局部数据进行更新的结果。(b-d) 分别展示了使用 FedAvg,FedLC和我们的 FedVLS 对倾斜数据分布进行更新的结果。
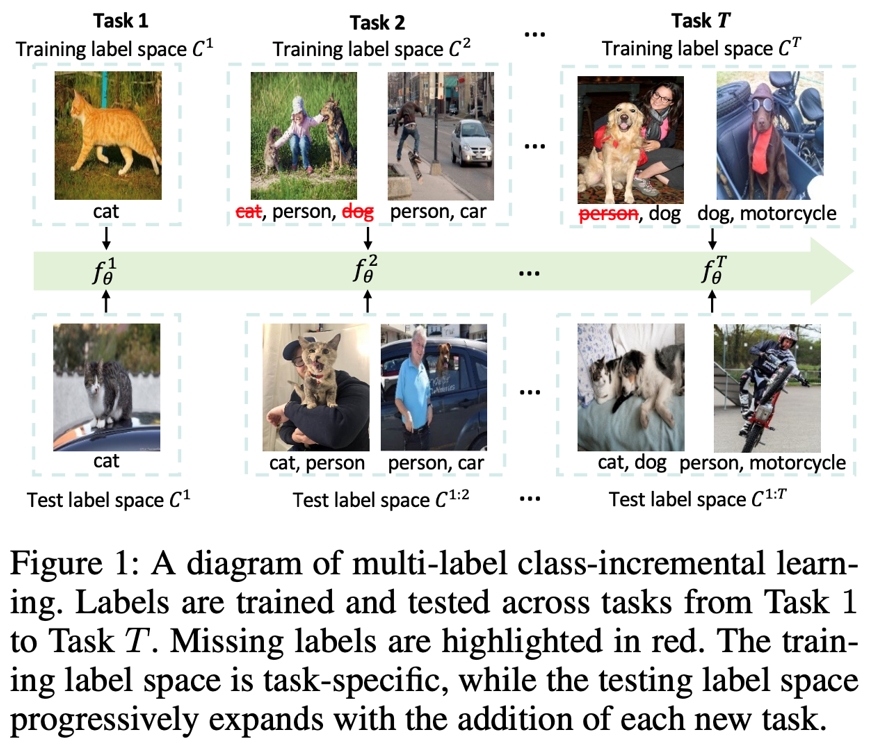
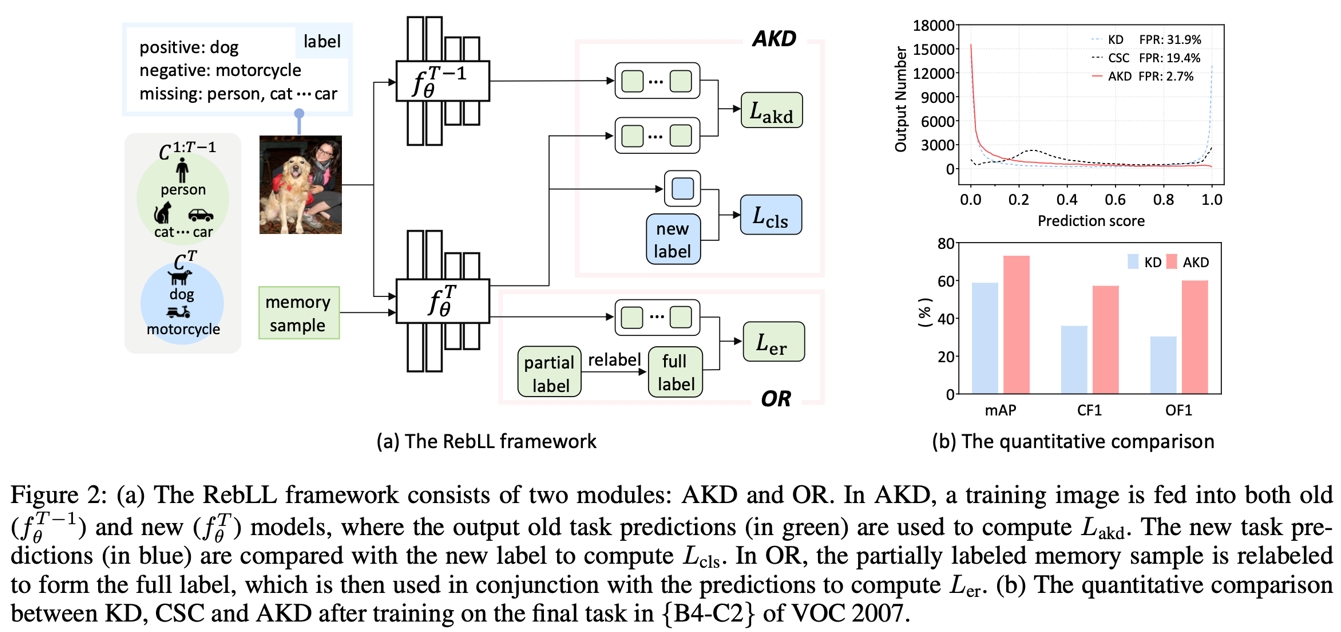
10. 重平衡多标签类增量学习
Rebalancing Multi-Label Class-Incremental Learning
作者:杜凯乐,周怡凡,吕凡,李雨阳,解君州,沈亦希,胡伏原,刘光灿
多标签增量学习(MLCIL)对于现实世界中的多标签应用至关重要,它允许模型在不断学习新标签的同时,保持对之前学到的知识的持续记忆。然而,最近的 MLCIL 方法由于忽视了正负样本不平衡问题,导致性能仅能达到次优水平。这个问题在标签级别和损失级别都存在,源于任务级别的部分标签问题。在标签级别,不平衡问题表现为负标签的缺失,而在损失级别,不平衡问题则来源于正负样本在优化过程中对损失的贡献不对称。
为了解决上述问题,我们提出了一个用于损失和标签层次的重平衡框架(RebLL),该框架集成了两个关键模块:非对称知识蒸馏(AKD)和在线重标定(OR)。AKD 旨在通过强调分类损失中的负标签学习,并降低蒸馏损失中过于自信的预测的贡献,从而在损失层面进行重平衡。OR 则是针对标签重平衡,通过在线重标定丢失的类别来恢复内存中的原始类别分布。
我们在 PASCAL VOC 和 MS-COCO 数据集上进行的综合实验表明,这一重平衡策略显著提升了性能,即使使用基础的卷积神经网络(CNN)骨干网络,也达到了新的最先进水平。
11.保护模型自适应算法免受无标签数据中的后门木马攻击
Protecting Model Adaptation from Trojans in the Unlabeled Data
作者:生力军,梁坚,赫然,王子磊,谭铁牛
模型自适应技术使用源域预训练模型代替源域原始数据来解决分布偏移问题,由于其出色的隐私保护性,现在已成为一种流行的范式。然而,现有的模型自适应方法总是假设自适应到干净可靠的目标域数据,而忽略了目标域无标签样本的安全风险。本文首次探讨了精心设计的投毒目标域数据对模型自适应算法发起的潜在后门木马攻击。具体来说,我们针对攻击者拥有的不同先验知识提供了两种触发模式和两种投毒策略。这些攻击在测试阶段保持对干净样本的正常性能的同时,获得了很高的攻击成功率。为了防御这种后门植入,我们提出了一种即插即用的防御方法DiffAdapt,它可以与现有的模型自适应算法无缝集成。基于常用数据库和自适应方法上的实验证明了DiffAdapt的有效性。
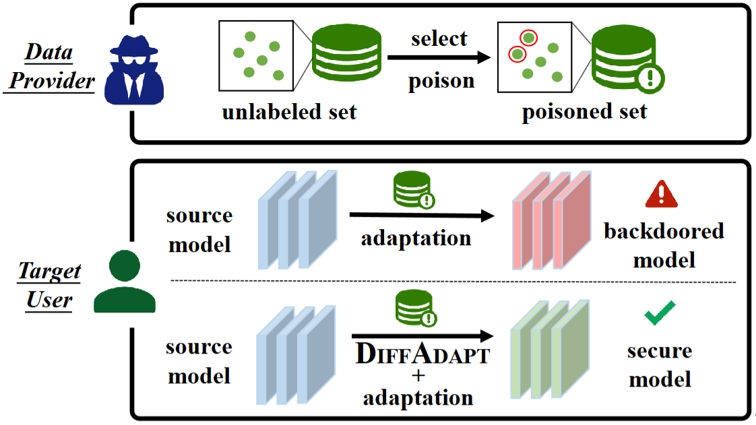
图1.自适应算法受到目标域数据后门攻击和防御示意图
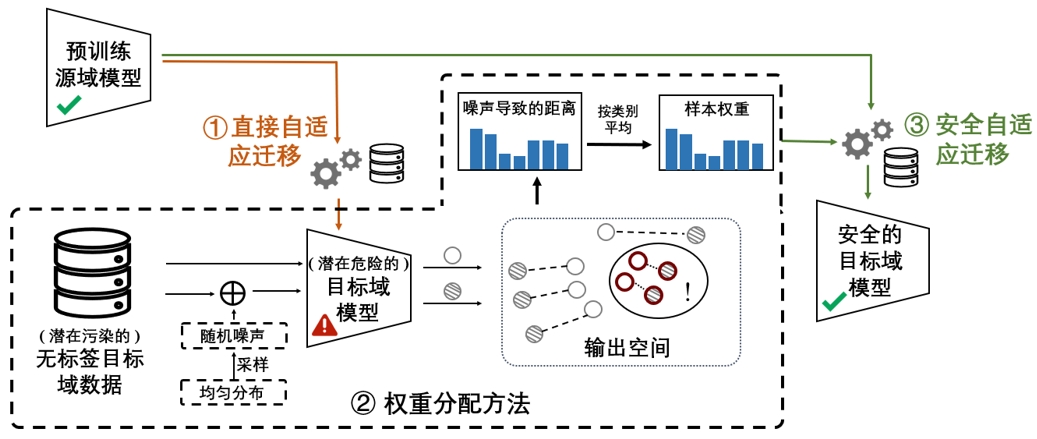
图2. DiffAdapt防御方法示意图
12.学习空中视觉对话导航的细粒度对齐
Learning Fine-Grained Alignment for Aerial Vision-Dialog Navigation
作者:苏一飞,安东,陈可涵,余玮宸,宁白杨,凌永根,黄岩,安东
空中视觉对话导航(AVDN)是一项新任务,要求无人机在航空环境中根据人机对话历史导航到目标位置。本文重点研究AVDN中关键的细粒度跨模态对齐问题,要求无人机在自上而下的视图中将语言实体与视觉地标对齐。为了实现这一点,我们首先通过半自动注释管道构建细粒度AVDN(FG-AVDN)数据集,在实体地标级别提供多样化的多模态注释。基于此,提出了一种新的细粒度实体地标对齐(FELA)方法来显式学习跨模态对齐。具体来说,FELA首先通过精确的语义网格表示来增强无人机的视觉理解,同时捕捉环境语义和空间结构。随后,为了学习实体地标对齐,我们设计了跨模态辅助任务从三个角度,包括视觉对齐、区域描述和对比学习。大量实验表明,我们的显式实体地标对齐学习对AVDN是有益的。FELA实现了领先的性能,与现有技术相比,SR提高了3.2%,GP提高了4.9%。
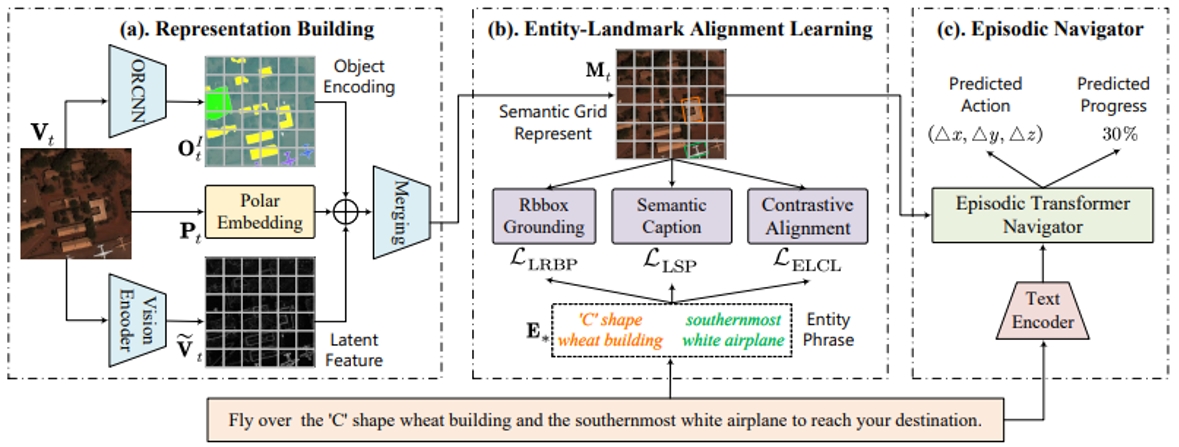
FELA整体流程图。包括(a)栅格语义表征构建(b)实体地标对齐学习(c)场景Transformer导航器。
13.可恢复压缩:一种文本信息引导的多模态视觉令牌回收机制
Recoverable Compression: A Multimodal Vision Token Recovery Mechanism Guided by Text Information
作者:陈懿,徐健,张煦尧,刘文卓,刘扬扬,刘成林
随着大规模语言建模技术的不断进步,将视觉编码器与大型语言模型结合的大型多模态模型在各种视觉任务中表现出色。目前,大多数多模态大模型通过将视觉编码器提取的视觉特征映射到大型语言模型中,与文本一起作为输入,以完成下游任务。因此,视觉令牌的数量直接影响模型的训练和推理速度。
虽然已有大量关于VIT的令牌剪枝研究,但对于多模态模型,仅依赖视觉信息对令牌进行剪枝或压缩可能导致重要信息丢失。另一方面,以问题形式输入的文本信息中,往往蕴含着对问题解答具有重要作用的额外信息。因此,为解决大多数纯视觉令牌剪枝方法中潜在的过度简化和过度剪枝问题,我们提出了一种无需训练的文本信息引导的动态视觉令牌恢复机制。该方法通过计算问题文本与视觉标记之间的相似性,恢复具有重要文本信息的视觉令牌,同时融合其他次要的视觉令牌以实现高效计算。实验结果表明,我们提出的方法能够在平均9倍的压缩率下保持具有竞争力的性能。

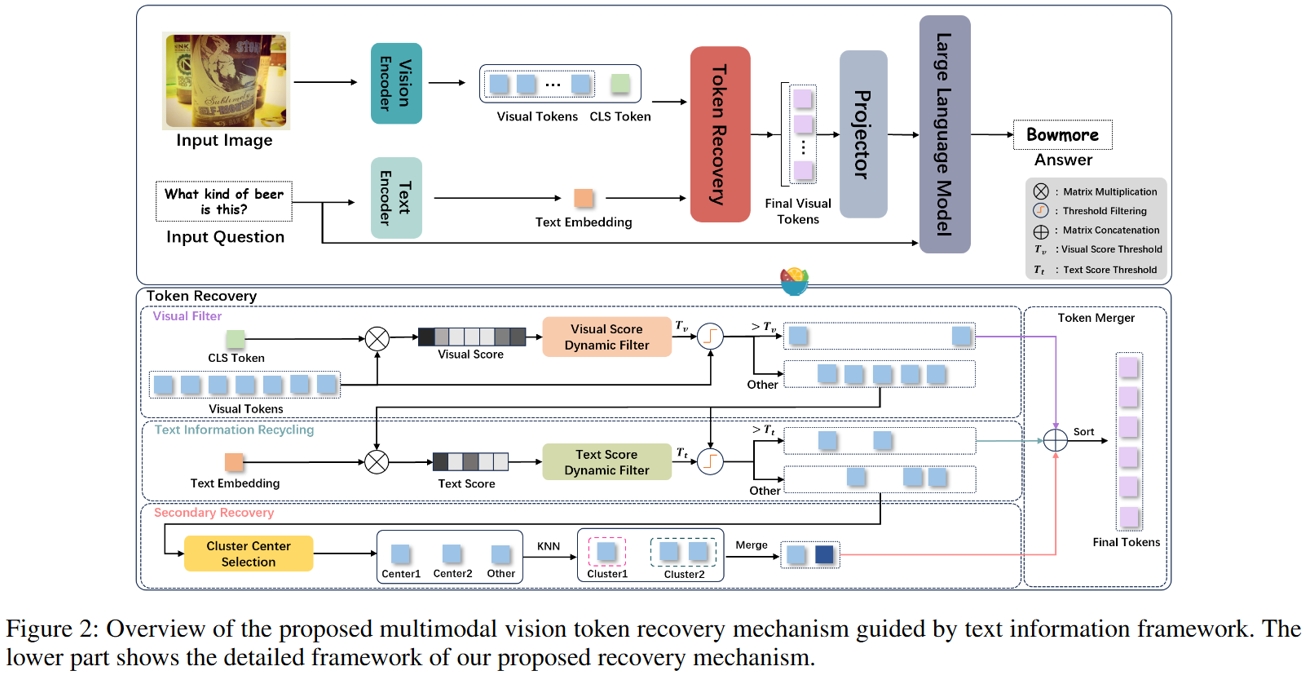
14.用于音频深度伪造检测的持续学习区域优化方法
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
作者:陈玉杰,易江燕,范存航,陶建华,任勇,曾思丁,章楚源,晏鑫蕊,顾浩,薛军,王成龙,吕钊,张晓辉
随着语音合成和语音转换技术的快速发展,真假音频的区分变得越来越模糊,给社会带来了巨大的安全隐患。音频深度伪造检测机制备受关注。尽管相关研究取得了显著进步,但在现实场景中面对多样化且看不见的伪造音频时,其性能仍然有限。
为了应对上述挑战,我们提出了一种名为基于区域优化(RegO)的连续学习方法,用于音频深度伪造检测。具体来说,我们使用 Fisher 信息矩阵来测量真实和虚假音频检测的重要神经元区域,将它们分为四个区域。首先,我们直接对不太重要的区域进行微调,以快速适应新任务。接下来,我们对仅对真实音频检测重要的区域并行应用梯度优化,并在正交方向上对仅对虚假音频检测重要的区域应用梯度优化。对于对两者都很重要的区域,我们使用基于样本比例的自适应梯度优化。这种区域自适应优化确保了记忆稳定性和学习可塑性之间的适当权衡。此外,为了解决旧任务中冗余神经元的增加,我们进一步引入艾宾浩斯遗忘机制来释放它们,从而提高模型学习更广义的判别特征的能力。实验结果表明,与用于音频深度伪造检测的最先进的连续学习方法 RWM 相比,我们的方法的 EER 提高了 21.3%。此外,RegO 的有效性超出了音频深度伪造检测领域,在图像识别等其他任务中显示出潜在的重要性。
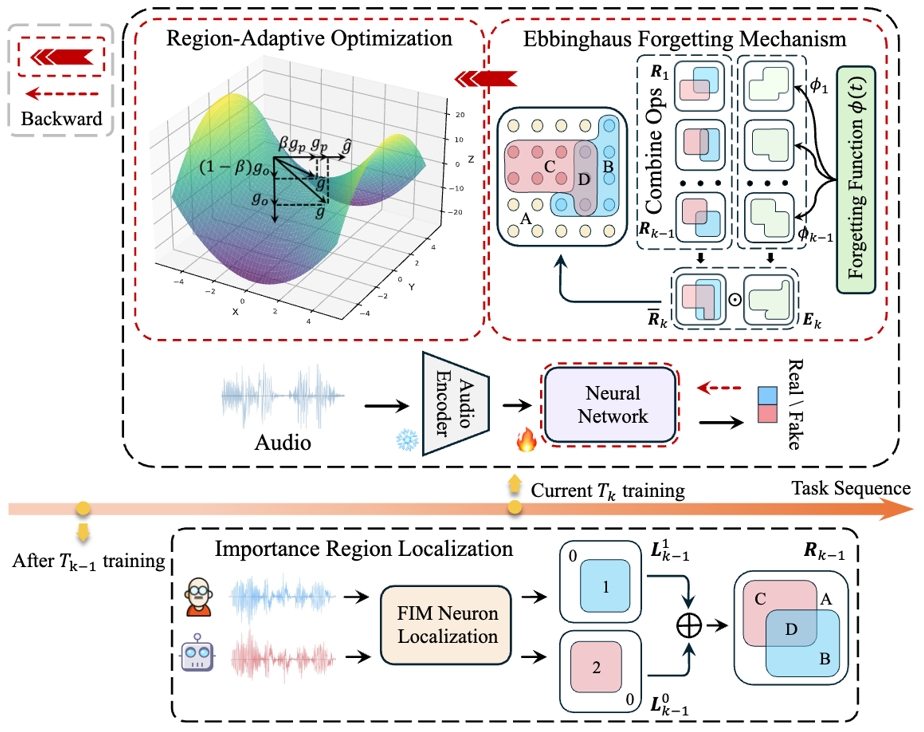
RegO架构图
15.基于时间自擦除监督的 SNN 高判别性特征学习
Towards More Discriminative Feature Learning in SNNs with Temporal-Self-Erasing Supervision
作者:刘伟,杨力,赵茗轩,薛登峰,王树勋,蔡博宇,高晋,李文娟,李兵,胡卫明
脉冲神经网络(SNNs)能够在多个时间步上处理视觉输入,模拟人类的动态感知和认知过程。然而,SNNs在时间维度上的特征判别能力较弱,主要由于固有的时空不变性,导致某些区域在多个时间步上被冗余激活,从而影响了特征多样性的学习。与人类在观察物体时通过动态转移注意力识别不同判别区域的方式不同,SNNs缺乏这种能力,未能充分发挥其时间维度的优势。为解决这一问题,本文提出了一种新颖的时间自擦除(Temporal-Self-Erasing, TSE)监督方法,旨在动态调整不同时间步的学习区域,增强SNNs的特征判别能力。TSE方法通过识别多个时间步中高度激活的区域并进行抑制,鼓励网络转向其他信息量较少但仍然具有判别性的区域,从而避免冗余特征的重复学习。该方法类似于人类在动态识别过程中切换注意力的策略。实验结果表明,与基线相比,我们的 TSE 方法显著提高了 SNN 的分类准确性和鲁棒性。
TSE网络架构图
16.FEAST-Mamba:特征与空间感知的跨模态双向正交融合点云分割Mamba网络
FEAST-Mamba: FEAture and SpaTial Aware Mamba Network with Bidirectional Orthogonal Fusion for Cross-Modal Point Cloud Segmentation
作者:李查德,张朋举,刘博,卫浩,吴毅红
最近,多模态融合策略在点云分割领域受到越来越多的关注。尽管取得了一些成功,但现有方法通常会产生不必要的信息丢失或冗余。在本文中,我们提出了一种新颖的特征与空间感知的Mamba网络FEAST-Mamba,以解决点云分割领域中多模态数据融合时的信息丢失以及冗余问题。为利用不同模态之间的互补性,提出了一种双向正交注意力模块,首先通过跨模态注意力使特征之间进行双向交互,然后运用提出的正交融合方法减少相似特征间的冗余。此外,提出的重排序策略解决了现有点云Mamba网络在远距离上下文信息建模方面的不足,并能有效地在空间中近邻间以及具有相似特征的区块间构建关联。在多个室内和室外数据集上的定量、定性与消融实验都获得了优异的分割结果,证明提出方法的有效性。
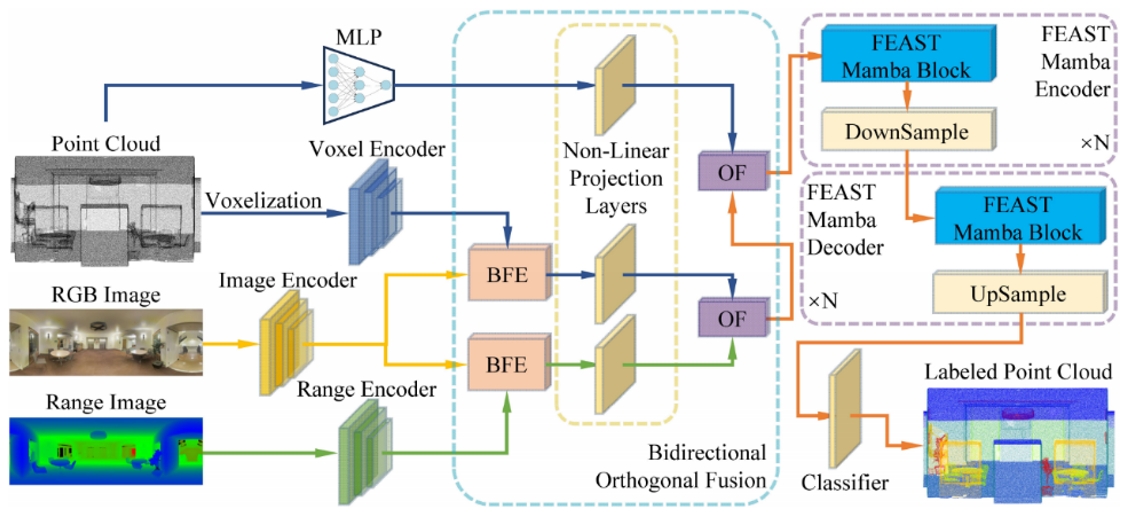
图1. 本研究提出方法的总览图。给定具体的输入数据后,首先对点云进行体素化处理,并分别运用MLP与不同的编码器获得四种特征。对于体素特征和深度图像特征,我们借助RGB图像的纹理特征,通过双向特征增强(Bidirectional Feature Enhancement,BFE)模块来增强这两种模态数据表示。然后,将增强后的体素特征、深度图像特征以及点MLP特征运用提出的正交融合(OF)方法依次进行两两融合。最后,将具有经过上述融合操作后特征的点云块输入我们提出的FEAST Mamba块进行特征与空间感知的重排序,并运用状态空间模型处理排序后的点云数据,同时与下采样和上采样相结合,做到多尺度的特征处理。
17.数据集内轨迹回报正则化的离线偏好强化学习
In-Dataset Trajectory Return Regularization for Offline Preference-based Reinforcement Learning
作者:凃崧峻,孙敬博,张启超*,张曜程,刘嘉,陈轲,赵冬斌
设计复杂的人工奖励函数在强化学习(RL)领域是一个极具挑战的任务。基于偏好的强化学习(PbRL)通过利用人类偏好指导策略的优化,为这一问题提供了一种有效的解决方案。然而,对于离线PbRL,基于轨迹偏好学习单步级奖励模型仍存在挑战,如有限的偏好数据导致的奖励偏差。这种偏差可能引发乐观的轨迹拼接,从而削弱了离线RL阶段的保守性机制,进而导致性能下降。针对上述挑战,本文提出了一种新的方法,称为数据集内轨迹回报正则化(In-Dataset Trajectory Return Regularization, DTR),以改善离线PbRL的性能表现。DTR通过整合条件序列建模和时序差分学习,动态地平衡模仿行为策略中高回报轨迹和选择高奖励动作进行轨迹拼接的能力。此外,本文引入了一种基于集成的归一化方法,通过集成多个奖励模型,平衡奖励差异性和准确性。在各种基准测试中的实验结果表明,DTR在性能上优于其他先进的离线PbRL方法,为PbRL领域提供了一种新的解决方案。
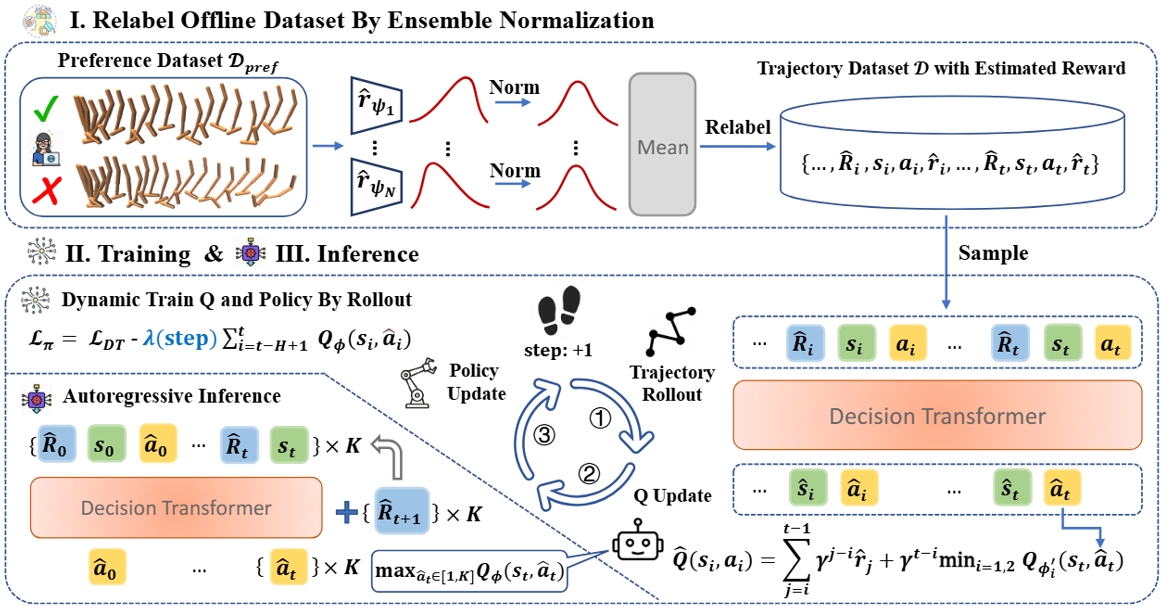
DTR方法框架图
18.PanoDiT:基于扩散Transformer的全景视频生成
PanoDiT: Panoramic Videos Generation with Diffusion Transformer
作者:张沐阳,陈玉质,许镕涛,王常维,杨金明,孟维亮,郭建伟,赵辉煌,张晓鹏
随着沉浸式体验的日益普及,全景视频在研究和应用领域引起了广泛关注。然而,全景视频的高成本凸显了基于提示生成方法的需求。尽管近年来的文本到视频(T2V)扩散技术在标准视频生成中展现了潜力,但由于内容和运动模式存在显著差异,这些技术在应用于全景视频时面临挑战。本文提出了PanoDiT框架,利用扩散变换器(DiT)架构从文本描述生成全景视频。与传统依赖UNet结构去噪的方法不同,我们的方法采用了变换器架构进行去噪,并结合了时序和全局注意力机制,从而保证了帧生成的一致性和运动过渡的平滑性,在长时间跨度的生成任务中具有显著优势。为了进一步增强生成视频中的运动效果和一致性,我们引入了DTM-LoRA以及两个全景视频特有的损失函数。与之前的方法相比,我们的PanoDiT在多个评估指标和用户研究中均实现了最先进的性能。
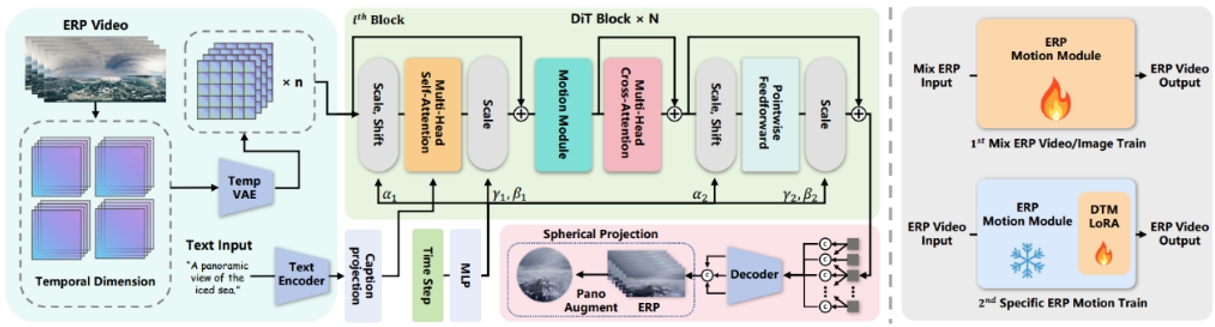
图1. [左]:我们的 PanoDiT 框架。我们的 PanoDiT 通过简单的文本提示生成高保真 ERP 视频,并利用球面投影生成 360 度全景视频输出。[右]:训练过程}。第一步,PanoDiT使用图像和全景视频的组合进行模型训练,得到高分辨率 ERP 图像运动模块。第二步,我们在具有不同摄像机运动的全景视频上进行训练DTM-LoRA。

图2. PanoDiT与目前已有最好方法对比,在生成的全景视频时长和视觉质量上都优于先前方法。
19.基于蒸馏2D开放词汇分割模型的无注释点云分割任务
3D Annotation-Free Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
作者:孙博一,刘宇航,王兴霞,田滨,陈龙,王飞跃
点云数据标注被认为是在自动驾驶中一项既耗时又昂贵的任务,而无注释学习训练通过从未标注数据中学习点云表示可以避免这一问题。本文提出了一种新颖的3D无注释框架AFOV,该框架借助2D开放词汇分割模型。该框架分为两个阶段:在第一阶段,我们创新性地整合了2D开放词汇模型的高质量文本和图像特征,并提出了三模态对比预训练TMP。在第二阶段,利用点云和图像之间的空间映射生成伪标签,实现跨模态的知识蒸馏。此外,我们引入了近似平面交互AFI来解决对齐过程中的噪声和标签混淆问题。为了验证AFOV的优越性,我们在多个相关数据集上进行了广泛的实验。在多个数据集的多个指标中,我们取得了优秀的性能。
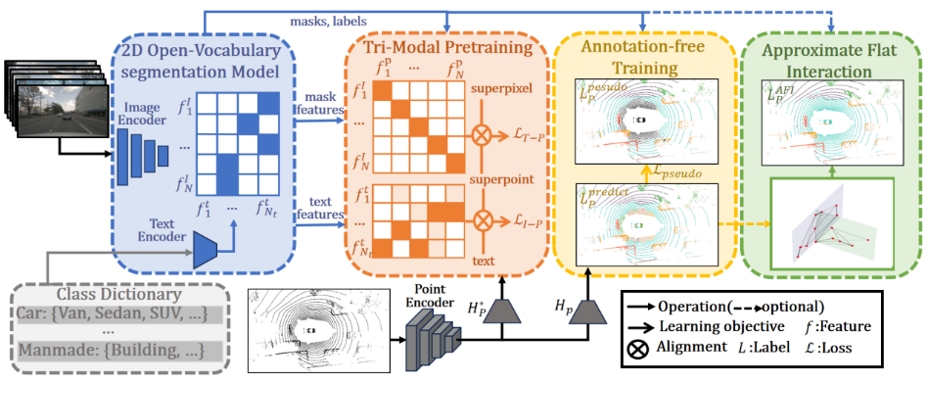
方法框架图
20.DriveDreamer-2:用于多样化驾驶视频生成的LLM增强型世界模型
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
作者:赵国盛,王啸峰,朱政,陈新泽,黄冠,包笑一,王欣刚
世界模型在自动驾驶领域,特别是在多视角驾驶视频的生成方面展现了优越性。然而,在生成定制化驾驶视频时,仍然存在显著挑战。本文中,我们提出了DriveDreamer-2,它融合了大型语言模型(LLM)以促进用户定义的驾驶视频的创建。具体来说,我们开发了一个轨迹生成函数库,用于生成符合用户描述的轨迹。随后,设计了一个高精地图(HDMap)生成器,学习从轨迹到道路结构的映射。最终,我们提出了统一多视角模型(UniMVM),以增强生成的多视角驾驶视频中的时空连贯性。据我们所知,DriveDreamer-2是首个能够生成定制化驾驶视频的世界模型,并且它可以以用户友好的方式生成不常见的驾驶场景(例如,车辆突然切入)。此外,实验结果表明,生成的视频增强了驾驶感知方法(如3D检测和跟踪)的训练效果。进一步地,DriveDreamer-2的视频生成质量超越了其他最先进方法,其FID和FVD得分分别为11.2和55.7,相对改进率分别约为30%和50%。
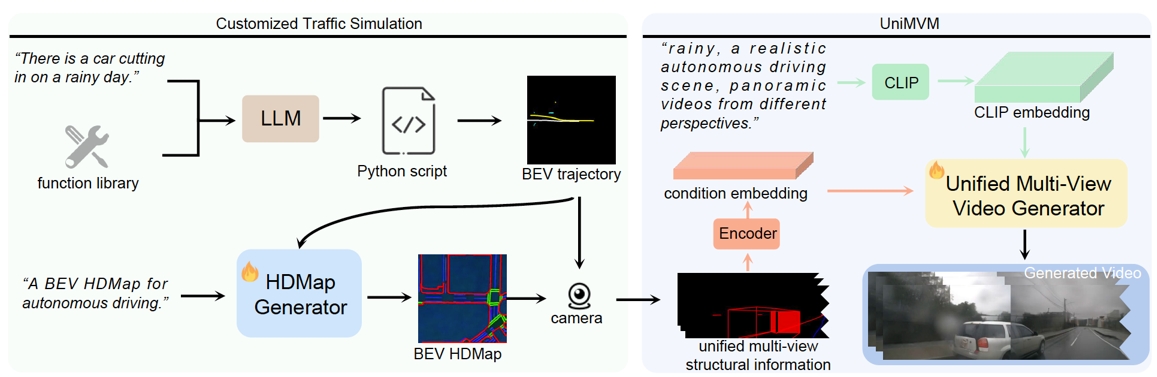
DriveDreamer-2的整体框架首先根据用户查询生成代理轨迹,随后输出逼真的高精地图,最后生成多视角驾驶视频
21.基于逻辑模式提示的大语言模型思维链推理问答方法
Enhancing Chain of Thought Prompting in Large Language Models via Reasoning Patterns
作者:张羽丰,王雪鹏,吴凌翔,王金桥
现有的无监督思维链提示方法存在两个主要缺点。首先,所选示范集与推理目标之间仍存在显著差距。尽管已有大量研究探讨了如何提供思维链示范以增强大语言模型的推理能力,这些方法在很大程度上依赖于问题或答案的语义特征。这些特征在全局范围内引入了不相关的噪声,可能掩盖推理所需的逻辑信息。因此,构建的示范集未能有效地代表特定领域的逻辑知识,并且难以充分激发大语言模型的正确推理。其次,一些示范选择方法缺乏可解释性和可扩展性。这些方法主要基于启发式设计,或利用模型自身生成额外的示范。通过这些手段选择的示范集本质上缺乏明确的解释,使得评估其有效性或确定进一步优化的方向变得困难。在可解释性至关重要的场景中,这一限制尤为突出。
本文针对大语言模型的推理问答任务,提供一种基于逻辑模式提示的大语言模型思维链推理问答方法。用以解决现有技术中如何消除上下文中模板带来的无关信息偏差,从而缩小示范集与推理任务之间的差距。这一策略有助于提供更明确的可解释性,更深入地理解思维链提示的工作原理。这种可解释性还可以作为归因分析和可视化的线索。
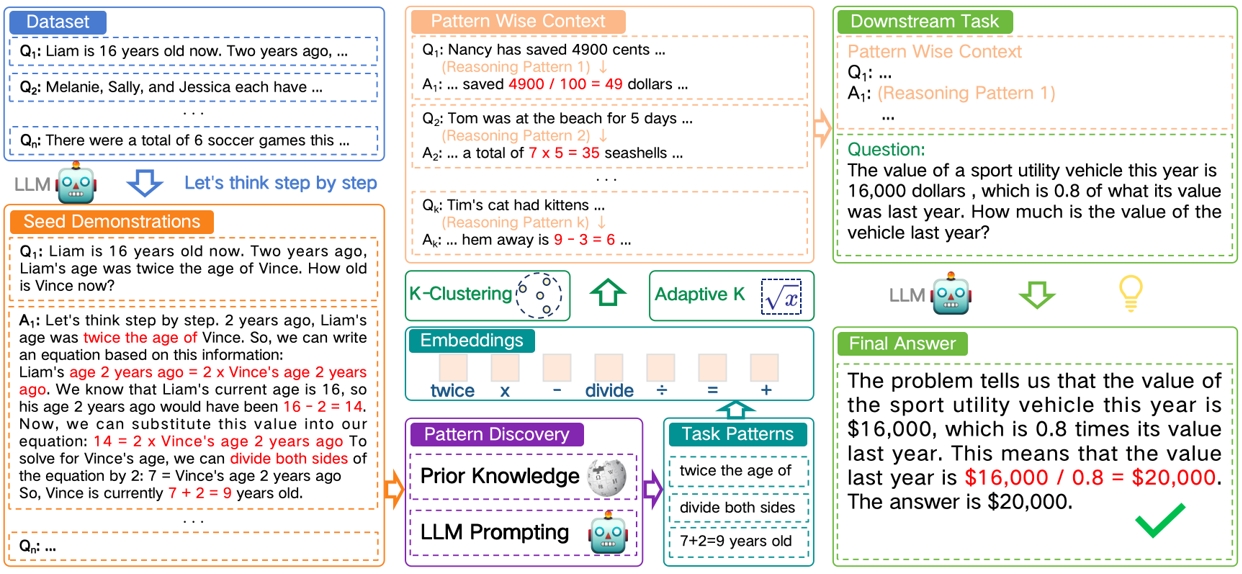
图1. 整体流程图
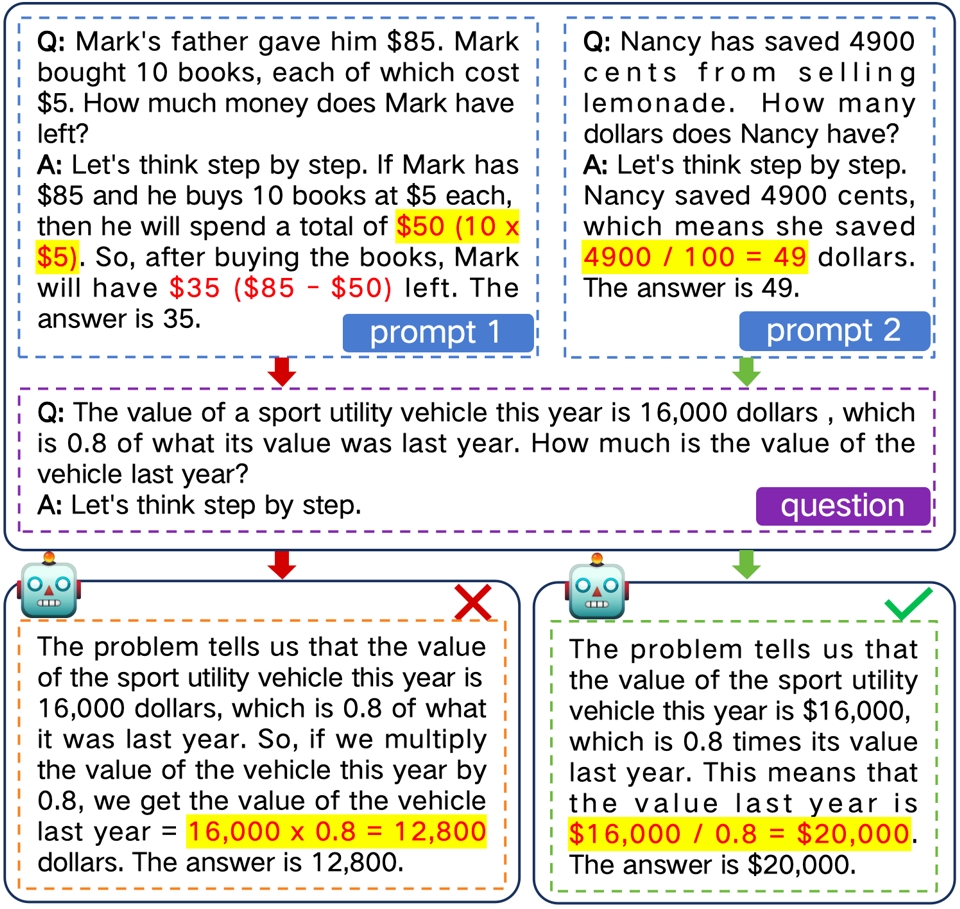
图2. 一个推理问答的示例
22.从跨被试fMRI中学习可迁移的脑解码模型
See Through Their Minds: Learning Transferable Brain Decoding Models from Cross-Subject fMRI
作者:刘雨龙,马永强,朱贵波,井浩东,郑南宁
解码功能性磁共振成像(fMRI)中的蕴含的视觉内容为理解人类视觉系统提供了新的视角,但数据稀缺和低信噪比限制了基于fMRI的脑解码模型的性能。由于个体差异性,传统方法往往针对个体单独训练解码模型,这种范式对训练样本的数量很敏感。本文通过提出浅层的个体特定适配器,将跨被试的fMRI数据映射到统一的表示中,从而解决数据稀缺问题。随后,使用共享的深度解码模型将这些特征解码到目标特征空间。我们结合视觉和文本监督进行多模态大脑解码,并将高层次感知解码与结合高层次感知引导的像素级别重建相结合。我们的实验揭示了几个有趣的发现:1)使用跨被试fMRI进行训练对高层次语义和低层次解码模型都有益;2)合并高层次和低层次信息可以提高两个层次的重建性能;3)对具有有限训练数据的新个体,可以通过训练新的适配器进行高效的迁移学习;4)在视觉刺激诱发的大脑活动上训练的解码器可以推广到解码想象的物体,但性能有所下降。

图1. NSD 数据集重建示例
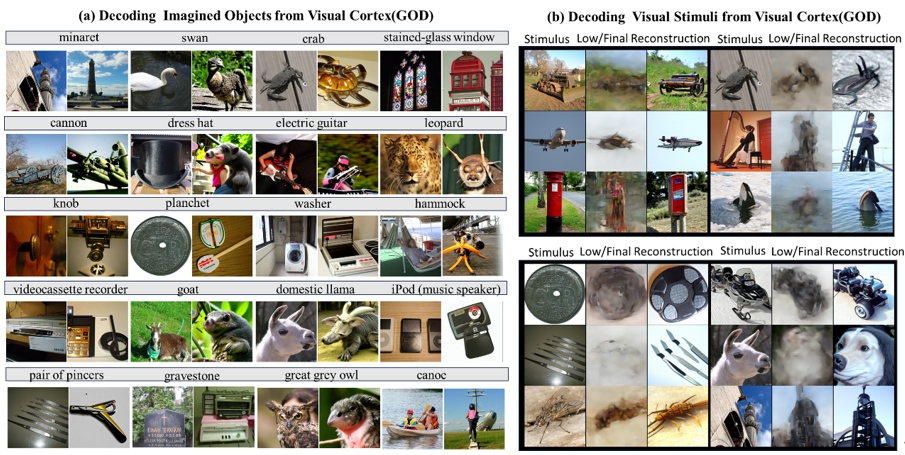
图2. GOD数据集解码示例。子图(a)为想象内容解码,被试者在接收文本提示后闭眼想象相关内容,每个文本下左侧为类别参考图像,右侧为解码的想象内容 。子图(b)为视觉刺激解码示例。
23. 基于视觉的通用势函数:面向多智能体强化学习中的策略对齐
Vision-Based Generic Potential Function for Policy Alignment in Multi-Agent Reinforcement Learning
作者:马昊(共一)、王诗杰(共一)、蒲志强、赵思垚、艾晓琳
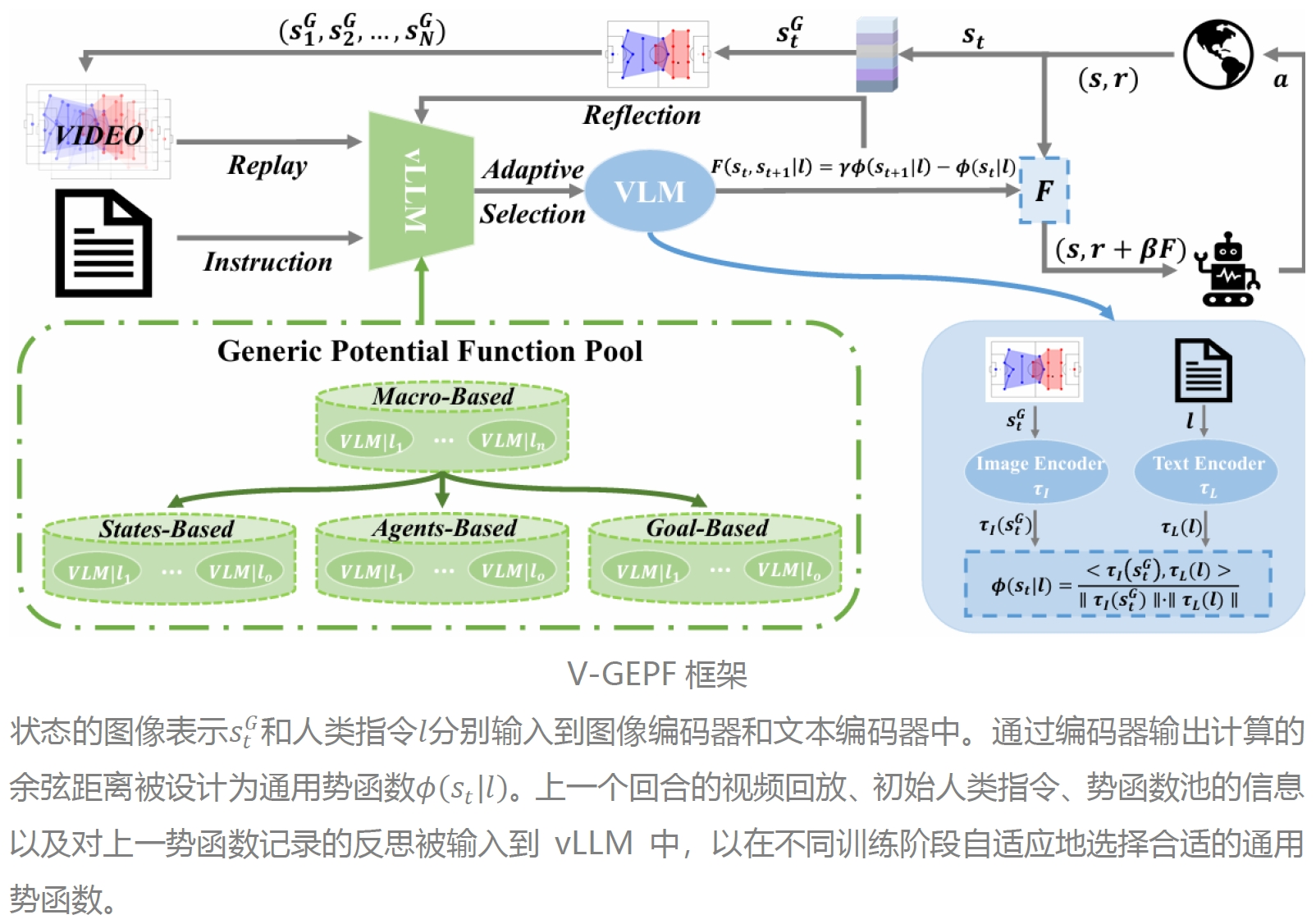
引导多智能体强化学习的策略与人类常识对齐是一个具有挑战性的问题,这主要源于将常识建模为奖励的复杂性,特别是在复杂的长时序任务中。最近的研究表明,通过奖励塑造(如基于势函数的奖励)可以有效提升策略的对齐效果。然而,现有方法主要依赖专家设计基于规则的奖励,这通常需要大量人力,并且缺乏对常识的高层语义理解。为了解决这一问题,我们提出了一种基于层次化视觉奖励塑造的方法,充分结合了视觉语言模型(VLM)的轻量化优势和视觉大语言模型(vLLM)的推理能力。在底层,一个VLM作为通用势函数,利用其内在的语义理解能力,引导策略与人类常识对齐。在顶层,我们设计了一个基于vLLM的自适应技能选择模块,用以帮助策略适应长时任务中的不确定性和变化。该模块通过指令、视频回放和训练记录,动态选择预设池中的适用势函数。此外,我们的方法可从理论上证明不改变最优策略。我们在 Google Research Football 环境中进行的大量实验表明,该方法不仅实现了更高的胜率,还能够有效地将策略与人类常识对齐。
24. 学习定理原理以增强大语言模型的数学推理能力
Learning Theorem Rationale for Improving the Mathematical Reasoning Capability of Large Language Models
作者:盛玉、李林静、曾大军
近期基于大规模语言模型的研究在数学推理能力上取得了显著提升,尤其是在基础难度的数学问题上。但是面对高中及大学以上水平的复杂问题时,现阶段模型的表现仍然有很大提升空间。本文通过对人类解决数学问题的过程进行分析,将解决数学问题的思维过程分解为选择合适的数学定理知识和做出分步解答两个阶段。在此基础上,对思维链方法进行扩展,提出了在思维链的前置引入思考特定数学定理的过程,这一过程对解答的质量及缓解幻觉有着重要的约束作用,但是在以往语言模型数学推理的研究中被忽略。因此,本文提出学习定理原理的概念,并创建了一个包含(问题,定理,解)三元组的数学推理数据集,用于将针对具体问题选择特定定理的方法传递给特定模型。在此基础上,本文模仿人类教学方法,提出一种面向定理的多层次指令进化策略,以缓解定理匹配数据标注困难的问题,并从各个角度促进对定理应用方法的理解。在多个公开数学推理数据集上的评估结果显示了本文所提出方法的有效性,尤其是在域外场景和涉及大学及以上的高水平数学问题上。
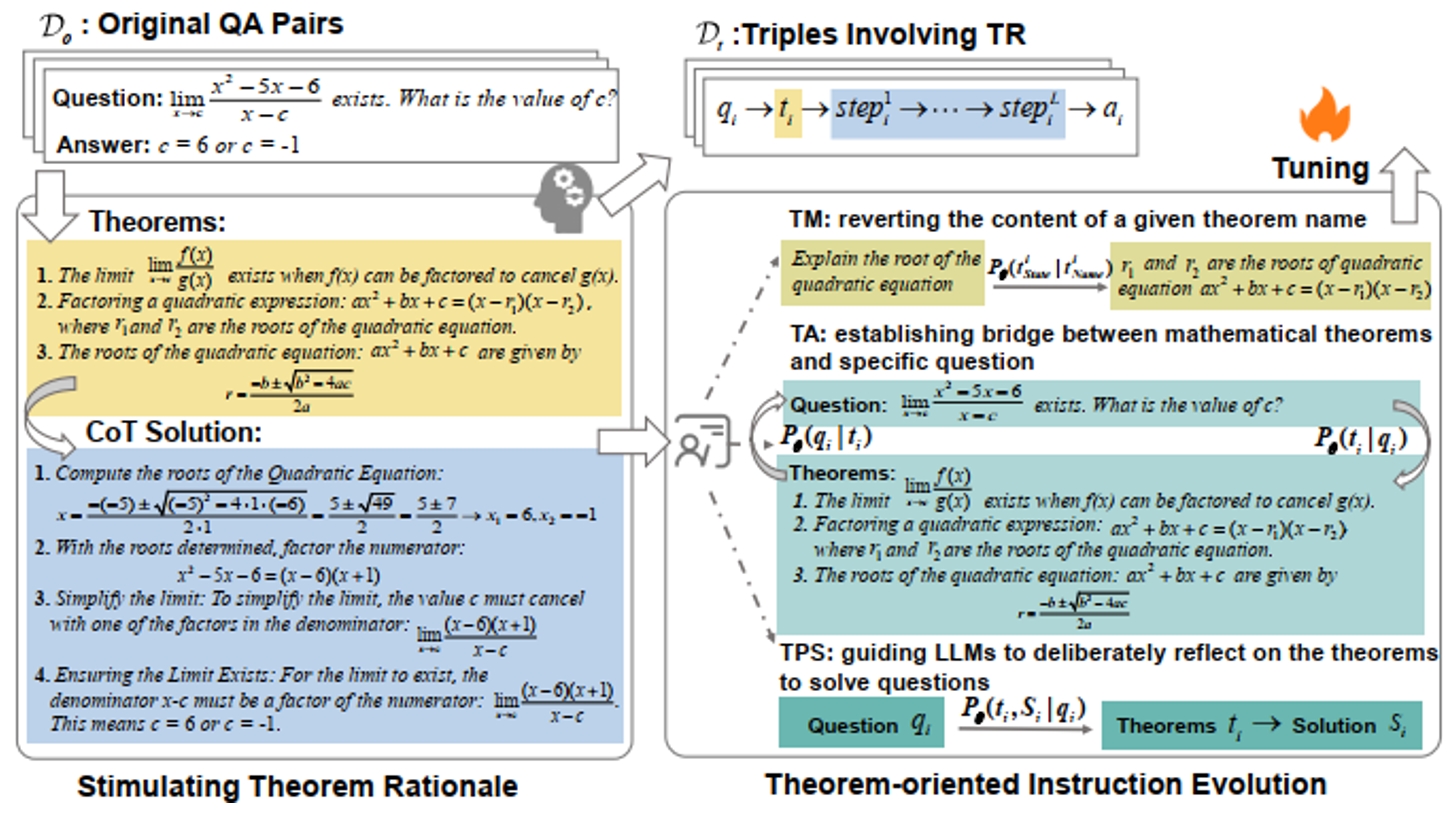
图1. 数学定理原理学习方法流程图。通过提示激活方法收集对齐的(问题,定理,解)三元组,并通过多层次的指令进化策略传递数学定理原理。

图2. 基于定理原理的错误校正案例。针对解答错误的数学问题,识别特定的定理错误可以有效地辅助错误修正过程,优于传统的模型自修正方法。
25. 用于多智能体博弈模仿学习的策略表示学习
Learning Strategy Representation for Imitation Learning in Multi-Agent Games
作者:雷世骐、Kanghoon Lee、李林静、Jinkyoo Park
在多智能体博弈的模仿学习离线数据集中,通常包含展现多样化策略的玩家轨迹,因此需要采取措施防止学习算法获取不良行为。对这些轨迹进行表示学习是一种有效的方法,每条轨迹的策略表示可以刻画每个演示者所采用的策略。然而,现有的学习策略往往需要玩家身份信息或依赖于较强的假设,这些假设在一般的多智能体博弈数据集中未必适用。本文提出了策略表示增强模仿学习(Strategy Representation for Imitation Learning,STRIL)框架,该框架包含三大部分:(1) 在多智能体博弈中有效地学习轨迹对应策略表示;(2) 基于这些策略表示估计提出的指标;(3) 利用指标筛去次优数据。STRIL是一种插入式方法,可以集成到现有的模仿学习算法中。我们在多个竞争性多智能体场景中验证了STRIL的有效性,包括双人Pong、有限注德州扑克和四子棋。我们的方法成功获取了策略表示和对应指标,从而识别出主导轨迹,并显著提升了这些环境中现有模仿学习算法的性能。
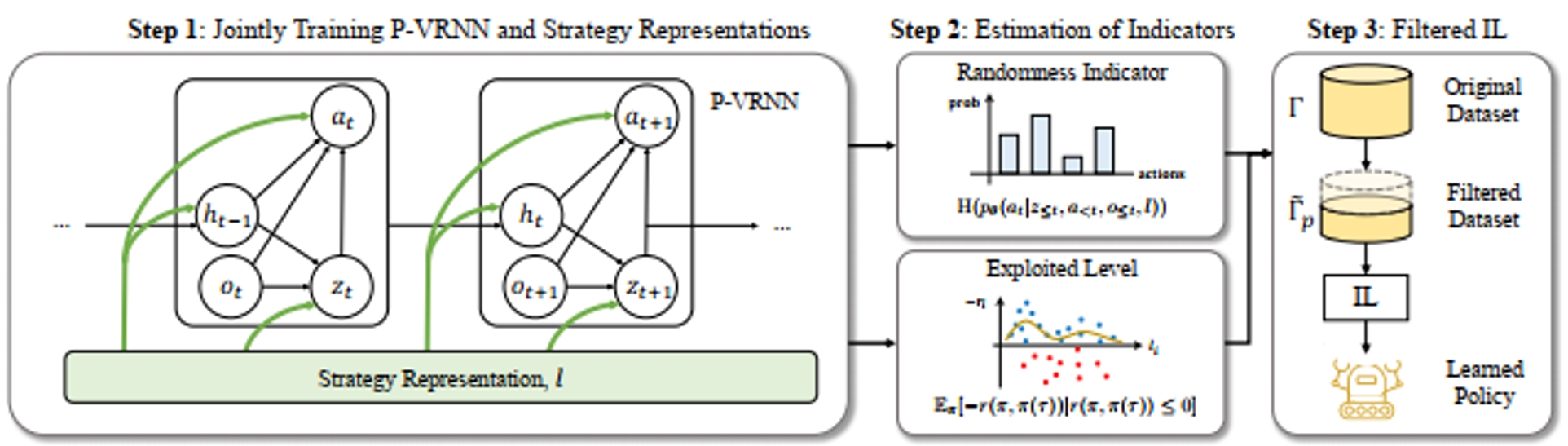
图1. STRIL整体结构图。第一步:同时训练P-VRNN模型和策略表示;第二步:指标估计;第三步:模仿学习得到策略。
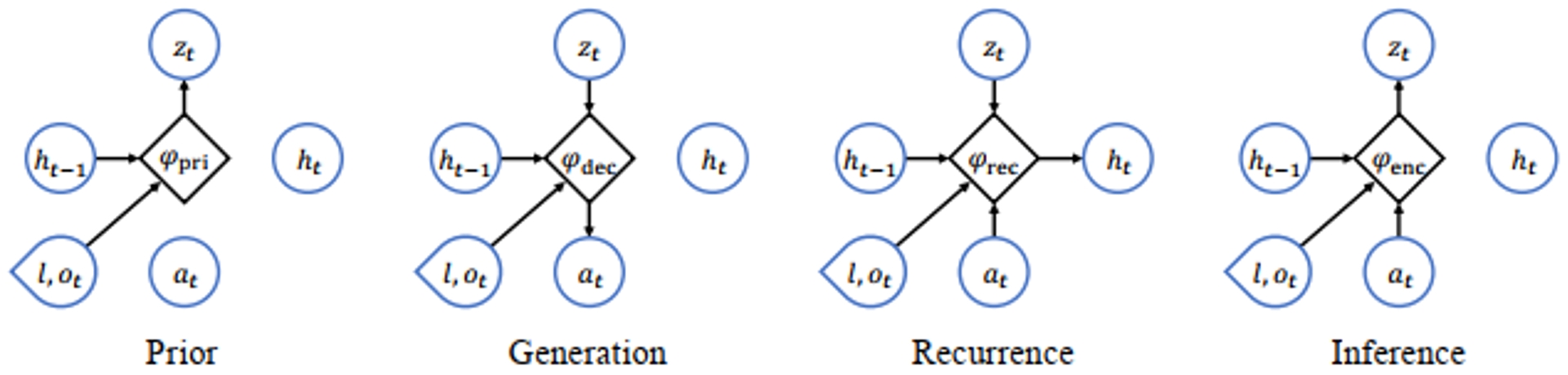
图2. P-VRNN模型分解后的网络结构。图中,圆表示变量,菱形表示可学习的参数,圆和菱形的混合表示部分可训练的变量。
26. 基于关系引导的渐进特征提取网络的点云补全
PointCFormer: a Relation-based Progressive Feature Extraction Network for Point Cloud Completion
作者:钟一,全卫泽,严冬明,蒋杰,魏迎梅
点云补全旨在从不完整的点云中重建完整的三维形状,这对于三维物体检测、分割和重建等任务至关重要。尽管点云分析技术不断进步,但特征提取方法仍然面临明显的局限性。在大多数方法中用作输入的点云的稀疏采样通常会导致一定的全局结构信息丢失。同时,传统的局部特征提取方法通常难以捕捉复杂的几何细节。为了克服这些缺点,我们引入了 PointCFormer,这是一个针对点云补全中的稳健全局保留和精确局部细节捕捉进行了优化的Transformer框架。这个框架有几个关键优势。
首先,我们提出了一种基于关系的局部特征提取方法来感知局部精细的几何特征。该方法在目标点与其k个最近邻点之间建立了细粒度的关系度量,量化了每个相邻点对目标点局部特征的贡献。其次,我们引入了一个渐进式特征提取器,将我们的局部特征感知方法与自注意力相结合。它从更密集的点采样作为输入开始,迭代查询长距离全局依赖关系和局部邻域关系。此提取器保持了增强的全局结构和精细的局部细节,而不会产生大量的计算开销。此外,我们在隐空间中生成点代理后设计了一个校正模块,以重新引入来自输入点的更密集信息,从而增强点代理的表示能力。PointCFormer 在几个广泛使用的基准上展示了最先进的性能。
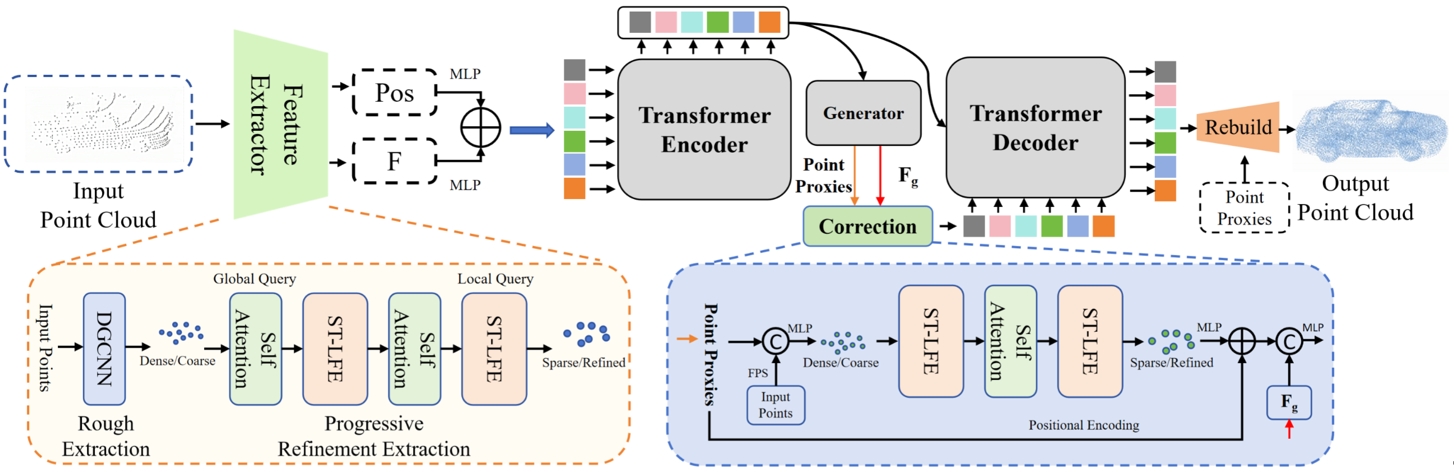
PointCFormer结构示意图
27. 眼神可控且身份与运动信息高度解耦的说话人脸生成
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expressions
作者:周子琪,全卫泽,石海林,李威,王莉莉,严冬明
音频驱动的数字人生成需要在处理多样化输入肖像及复杂的音频与面部动作相关性时,实现音视频数据的无缝融合。针对这一挑战,我们提出了一个名为 GoHD的鲁棒框架,用于从包含任意动作与身份信息的参考人脸图像生成高度逼真、生动且可控的说话视频。GoHD 包含三个关键创新模块:首先,采用隐空间向量分解技术实现人脸驱动模块,提升了对任意风格输入人脸图像的泛化能力。该模块实现了动作与身份信息的高度解耦,并通过引入眼神方向的控制纠正了之前方法易忽视的不自然眼部运动。其次,设计了基于conformer结构的条件扩散模型,以确保生成的头部姿态能够感知语音韵律。最后,为了在有限的训练数据下估计出与音频同步的逼真表情,提出了两阶段训练策略,分别对频繁且帧相关的唇部动作进行蒸馏,并与生成其他时间依赖性但与音频相关性较低的动作(如眨眼和皱眉)进行解耦。大量实验验证了 GoHD 卓越的泛化能力,展示了其在任意输入上的逼真说话人生成效果。
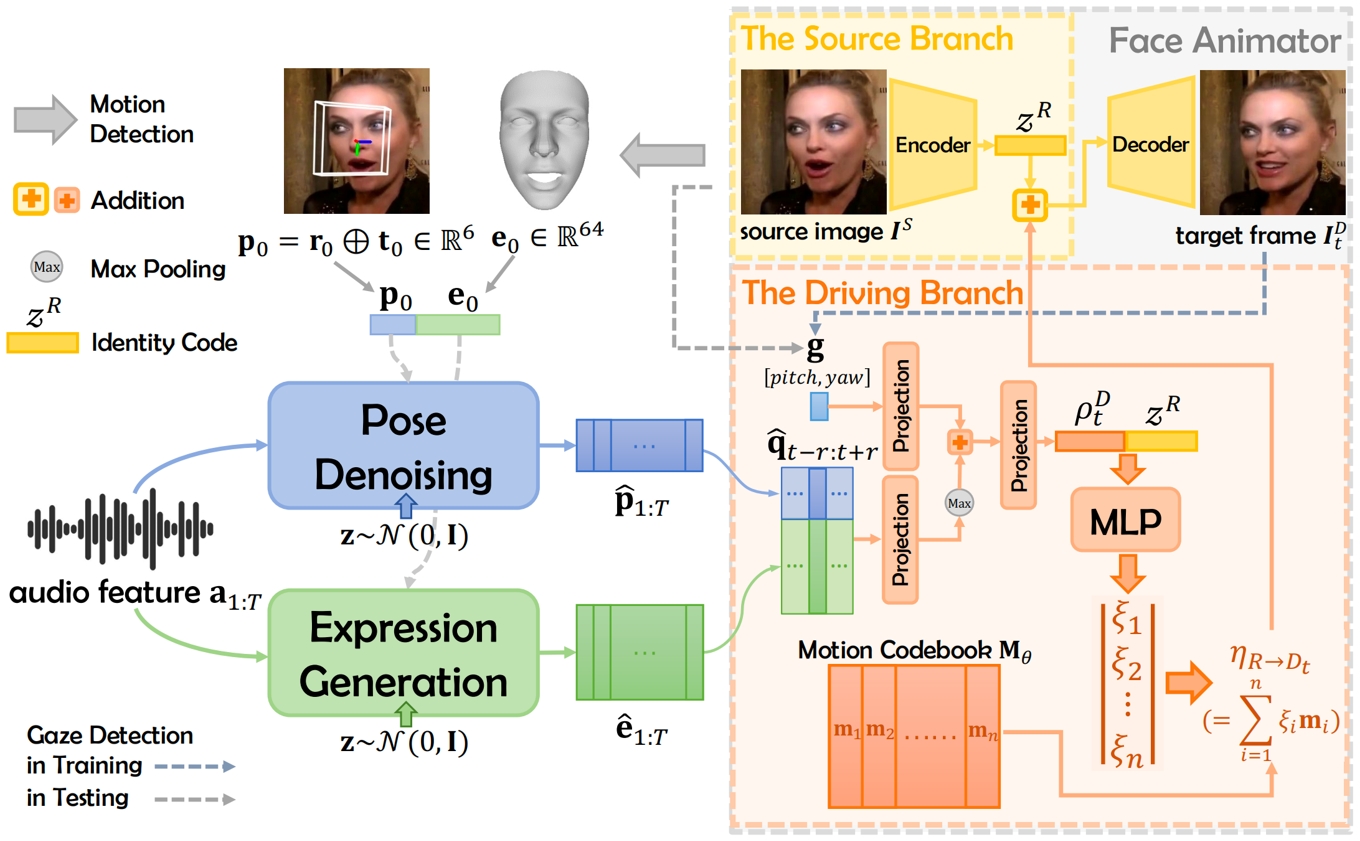
图1. 整体框架展示

图2. 眼神控制效果展示
28. 基于光栅草图学习的CAD模型生成
Revisiting CAD Model Generation by Learning Raster Sketch
作者:李朴,张文豪,郭建伟,陈经禄,严冬明
本文提出了RECAD,包含一个新的栅格化草图+拉伸的建模表示以及基于这种表示的CAD模型生成框架。与传统方法使用离散的参数化线段序列表示草图不同,RECAD采用栅格图像来表示草图,这种方法具有多个优势:1)打破了线段/曲线类型和数量的限制,提供了更强的几何表达能力;2)能够在连续的潜在空间中进行插值;3)允许用户更直观地控制输出结果。在技术实现上,RECAD使用了两个扩散网络:第一个网络基于拉伸数量和类型生成拉伸框,第二个网络基于这些拉伸框生成草图图像。通过结合这两个网络,RECAD能够有效地生成基于草图和拉伸的CAD模型。实验结果表明,RECAD在无条件生成方面取得了良好的性能,同时在条件生成和输出编辑方面也展现出良好的效果。
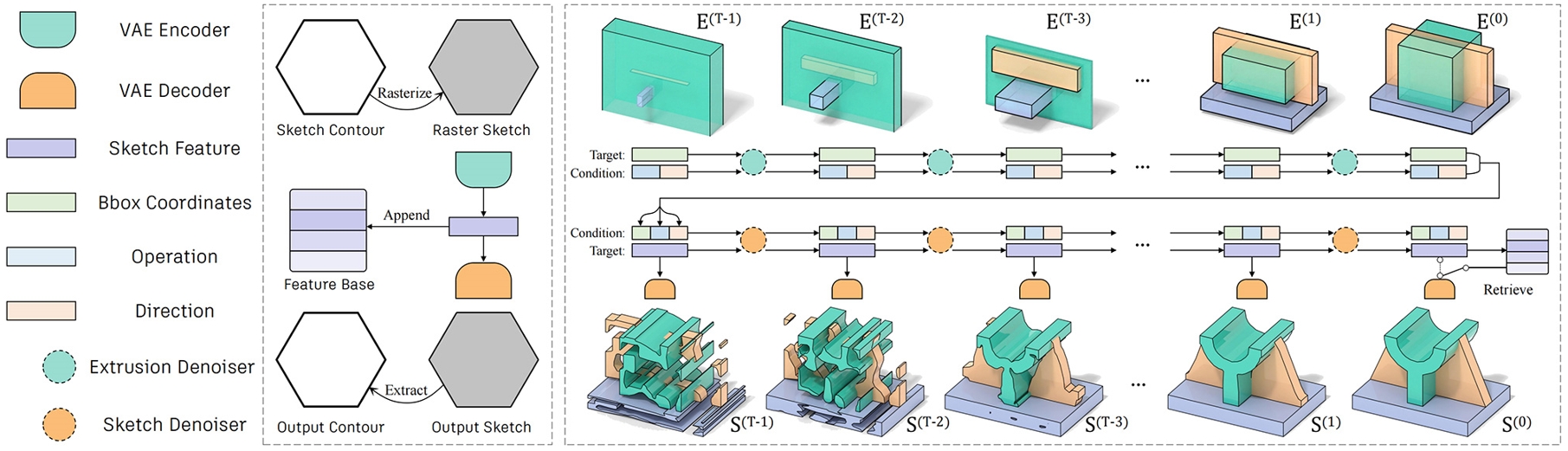
RECAD网络结构示意图
29. RealisHuman:一种用于修复生成图像中畸形人体部分的两阶段方法
RealisHuman: A Two-Stage Approach for Refining Malformed Human Parts in Generated Images
作者:王本智,周靖凯,白景琦,杨阳,陈威华,王帆,雷震
近年来,扩散模型在视觉生成领域取得了显著突破。然而,生成真实的人体图像,尤其是手部和面部等复杂结构部位,仍然面临重大挑战。这些问题主要源于人体结构的复杂性及在生成过程中的信息丢失。针对这一问题,我们提出了一种名为 RealisHuman 的新型后处理框架。该方法分为两个阶段:第一阶段通过“部位细节编码器”(Part Detail Encoder)结合畸形部位的参考信息与 3D 姿态估计结果,生成真实的人体局部图像,确保生成部分的细节一致性和高质量;第二阶段将生成的局部图像无缝地嵌入原始图像,通过局部区域的重绘技术,实现自然过渡,避免“剪贴”痕迹。实验结果表明,RealisHuman 显著提高了生成图像的真实感和一致性,并在不同风格的图像生成任务中表现出较强的泛化能力。此外,相较于现有的手部修复方法 HandRefiner,RealisHuman 在保留手部细节、修复小型手部区域以及保持整体图像一致性方面表现更优。
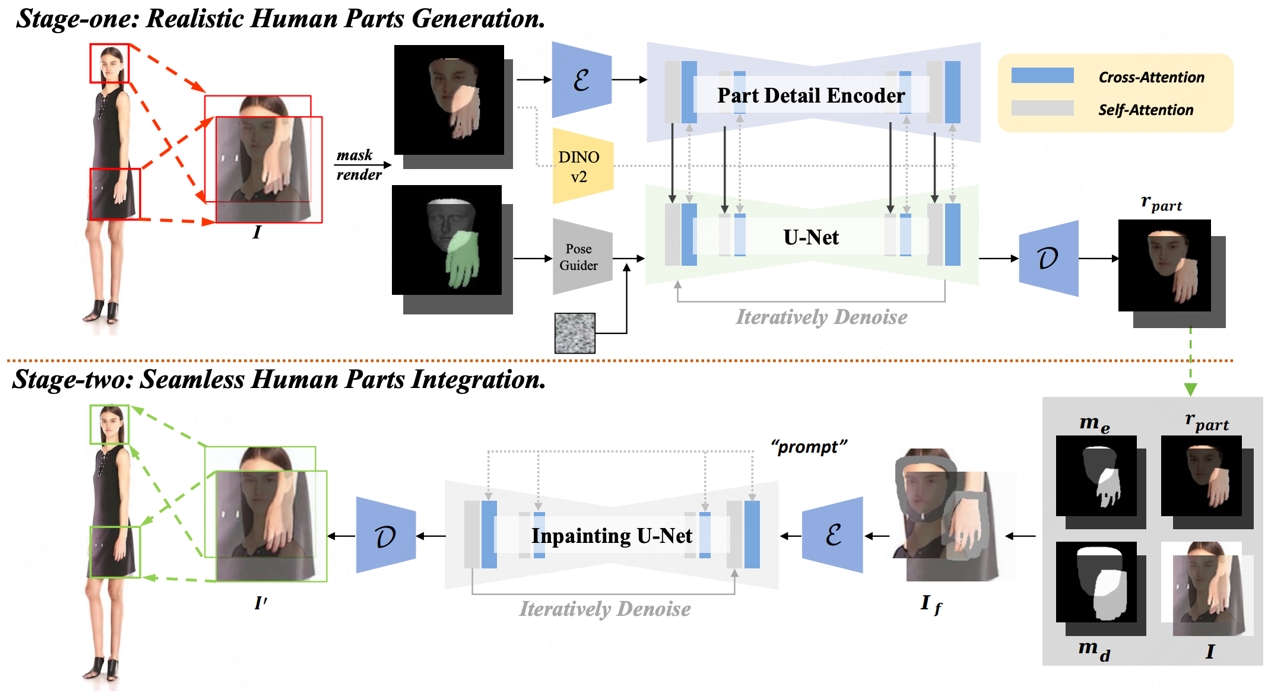
RealisHuman框架图
30. RCTrans:通过雷达稠密化器和序列解码器进行3D目标检测的雷达-相机Transformer
RCTrans: Radar-Camera Transformer via Radar Densifier and Sequential Decoder for 3D Object Detection
作者:李毅恒,杨阳,雷震
在雷达-相机3D物体检测中,雷达点云稀疏且噪声较大,这使得相机和雷达模态的融合变得困难。为了解决这个问题,我们提出了一种新的基于Query的检测方法,称为RCTrans。具体而言,我们首先设计了一个雷达稠密化编码器,用以丰富稀疏的有效雷达Token,然后将其与图像Token拼接。由此,我们可以充分探索每个兴趣区域的3D信息,并减少在融合阶段无效Token的干扰。接着,我们设计了一个可剪枝的序列解码器,根据所获得的Token和随机初始化的Query来预测3D框。为了缓解雷达点云中的高度模糊性,我们通过序列融合结构逐渐定位物体的位置。这有助于在Token和Query之间获得更精确和灵活的对应关系。我们在解码器中采用了剪枝策略,这可以在推理过程中节省大量时间,并防止Query失去其独特性。我们在大规模nuScenes数据集上进行了广泛的实验,证明了该方法的优越性。
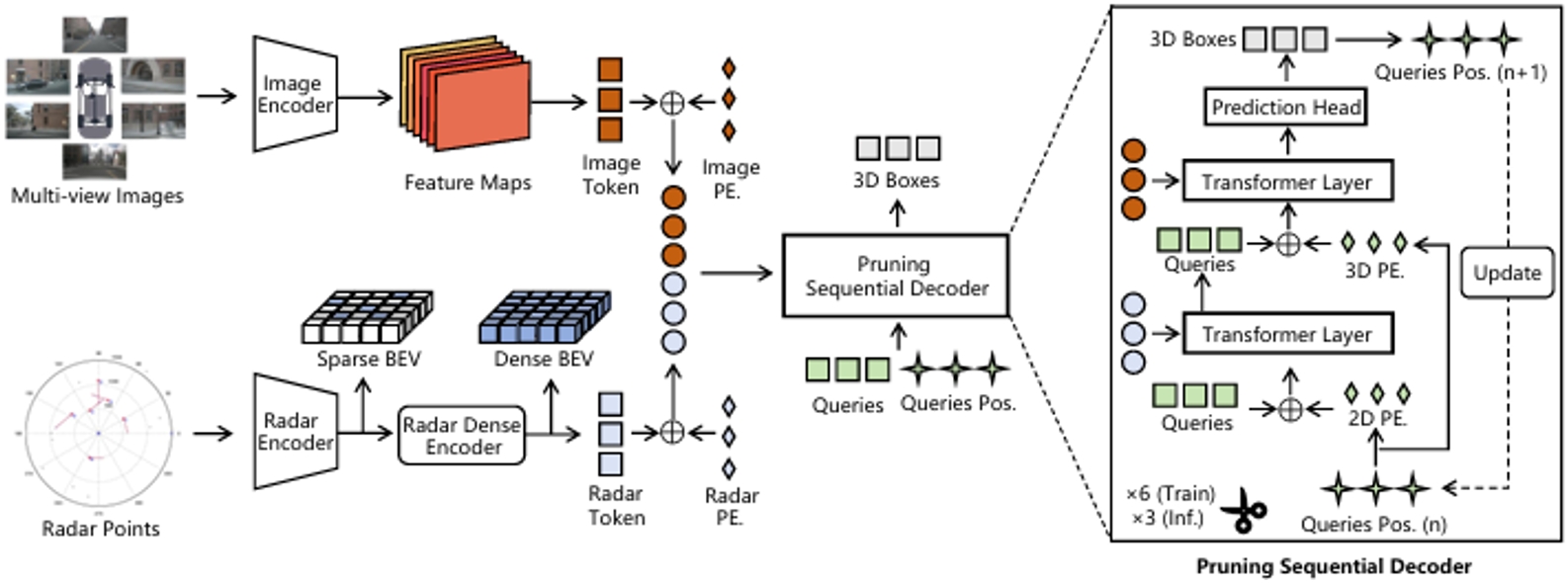
RCTrans的整体架构。RCTrans可以分为两个关键组件:(1)Token生成器,它提取多模态Token并与相应的位置编码相加。在生成雷达Token的时候,使用雷达稠密化编码器对雷达特征进行处理(2)可剪枝的序列解码器,它在每一层更新随机初始化的查询和查询位置,以更精确的方式逐步融合。最终预测结果是经过修剪后的最后一层输出。
31. CITI: 在不牺牲通用性能的情况下提升大型语言模型的工具使用能力
CITI: Enhancing Tool Utilizing Ability in Large Language Models Without Sacrificing General Performance
作者:郝煜朴、曹鹏飞、金卓然、廖桓萱、陈玉博、刘康、赵军
工具学习使大语言模型能够通过调用工具与外部环境互动,丰富了大语言模型的准确性和能力范围。然而,以往的研究主要集中在提高模型的工具使用准确性和对新工具的泛化能力上,过度强迫大语言模型学习特定的工具调用模式,而没有考虑到对模型通用性能的损害。这偏离了实际应用和整合工具以增强模型的初衷。为了解决这个问题,我们通过检查模型组件的隐藏表示变化和使用基于梯度的重要性分数来剖析这种能力冲突现象。基于分析结果,我们提出了一种基于组件重要性的工具使用能力注入方法(CITI)。根据组件的梯度重要性评分,它通过对不同组件应用不同的训练策略来缓解微调过程中引起的能力冲突。对重要组件,CITI应用混合LoRA专家结构(MOLoRA)来学习工具调用的知识;对于不重要的组件,它微调大语言模型的主干网络中的参数,同时保持其他参数不变。CITI能够有效增强模型的工具使用能力,而不会过度牺牲其一般性能。实验结果表明,我们的方法在一系列评估指标上取得了出色的表现。
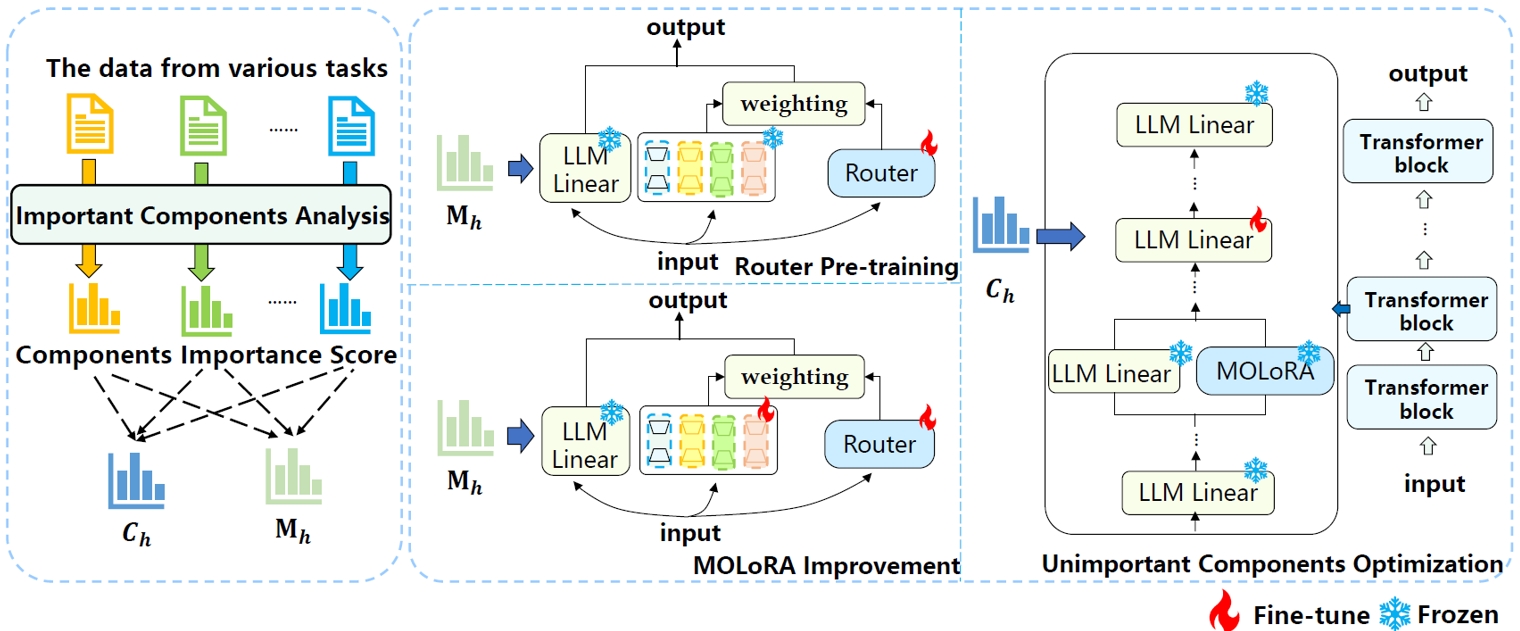
模型结构图
32. 知识叠加:揭示大语言模型终生知识编辑的失败原因
Knowledge in Superposition: Unveiling the Failures of Lifelong Knowledge Editing for Large Language Models
作者:胡晨辉,曹鹏飞,陈玉博,刘康,赵军
知识编辑旨在更新大语言模型中过时或错误的知识。然而,目前的知识编辑方法在终身编辑方面的可扩展性有限。本研究探讨了知识编辑在终身编辑中失败的根本原因。我们从线性关联记忆推导的闭式解出发,该解是当前最先进知识编辑方法的理论基础。我们将这一解从单次编辑扩展到终身编辑,并通过严格的数学推导,在最终解中发现了一个干扰项,这表明编辑知识可能会影响无关知识。对干扰项的进一步分析揭示了其与知识表示之间叠加现象的密切关系。也就是说,当语言模型中不存在知识叠加时,干扰项消失,从而实现无损的知识编辑。通过对众多语言模型的实验,我们发现知识叠加具有普遍性,其表现为高峭度、零均值和重尾分布,并遵循清晰的扩展定律。最终,通过结合理论和实验,我们证明了知识叠加是终身编辑失败的根本原因。此外,本研究首次从叠加的视角探讨了知识编辑,并广泛观察到众多真实语言模型中的知识叠加现象。
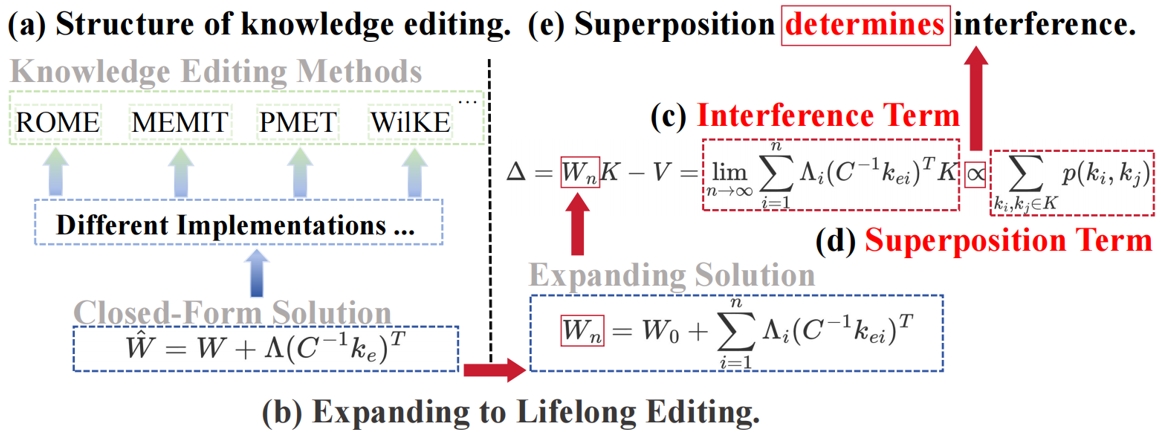
图1. 我们的工作示意图。(a) 当前的知识编辑方法采用统一的闭式解,通过改变参数矩阵实现知识更新;(b) 将闭式解扩展至终身编辑;(c) 干扰项的累积达到一定程度会导致语言模型遗忘知识;(d) 叠加项,表示两个知识表示之间的叠加程度;(e) 叠加项实际上决定了干扰项。
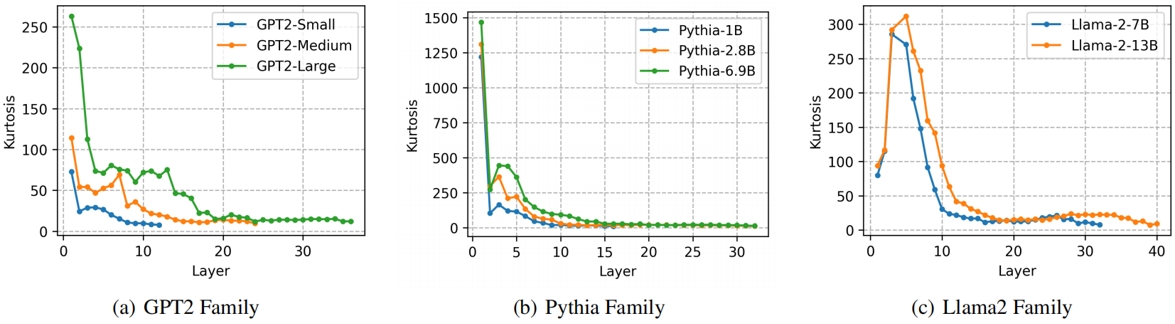
图2. 知识叠加的扩展定律。更高的峭度意味着更少的叠加。
33. 神经-符号协同蒸馏:提升小型语言模型复杂推理能力
Neural-Symbolic Collaborative Distillation: Advancing Small Language Models for Complex Reasoning Tasks
作者:廖桓萱,何世柱,徐遥,张元哲,刘康,赵军
近年来,大型语言模型(LLMs,如GPT-4、LLaMA3-70B)在复杂推理任务中表现出色,但其庞大的参数规模和高计算成本限制了在资源受限环境中的应用。小型语言模型(SLMs,参数量小于7B)虽然计算效率高效,但在处理需要结合通用认知能力和领域专业知识的复杂推理任务时表现较差。针对这一挑战,本文提出神经-符号协作蒸馏(NesyCD)。该方法将复杂任务所需的能力划分为两大类:一类是普遍适用的通用能力,这类能力适合通过神经网络模型进行建模与处理;另一类则是特定应用场景下的专用能力和专业知识,这类能力更适合利用符号系统进行精确表达与记录。具体而言,NesyCD通过传统的神经蒸馏方法,将LLMs中的通用认知能力迁移到SLMs中;而对于复杂推理任务中所需的领域专业知识,则采用符号知识蒸馏方法,将LLMs中的专业知识提取并存储到符号知识库中。实验结果表明,NesyCD显著提升了SLMs在复杂推理任务中的表现。例如,经过NesyCD训练的LLaMA3-8B和Qwen2-7B在多个任务上的性能超越了GPT-3.5-turbo,并接近LLaMA3-70B。该方法为资源受限环境下的高效推理提供了新思路。
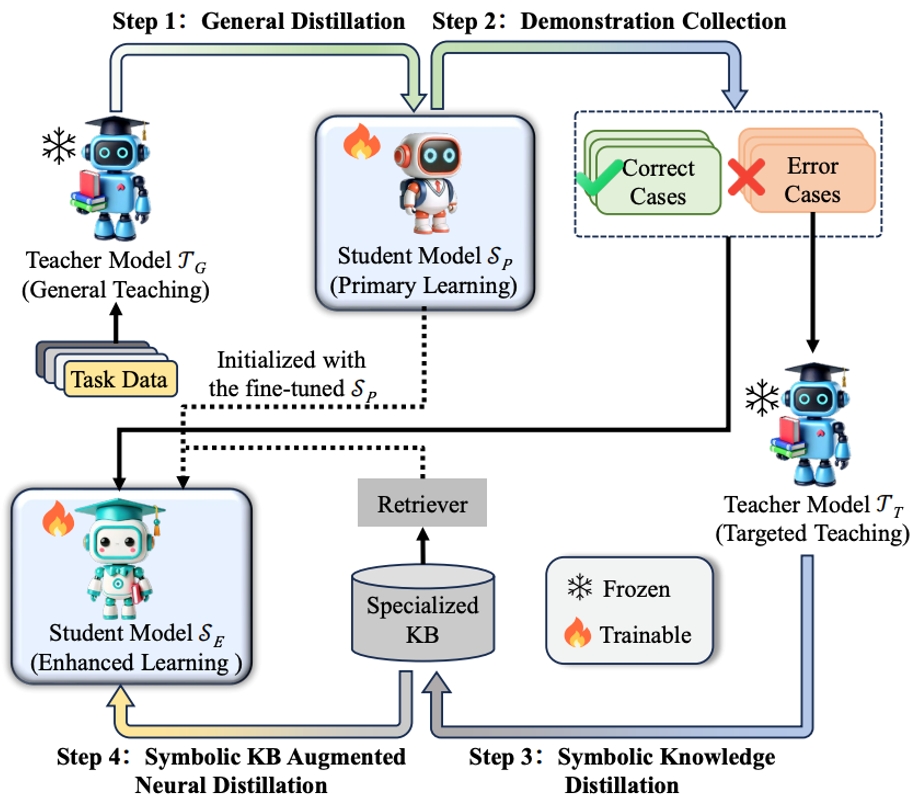
通过自适应检索教师模型生成的符号知识(符号蒸馏),实现小型学生模型(神经蒸馏)的复杂推理能力提升。
34. 基于隐式对抗攻击的大模型知识遗忘稳定性评估与提升方法
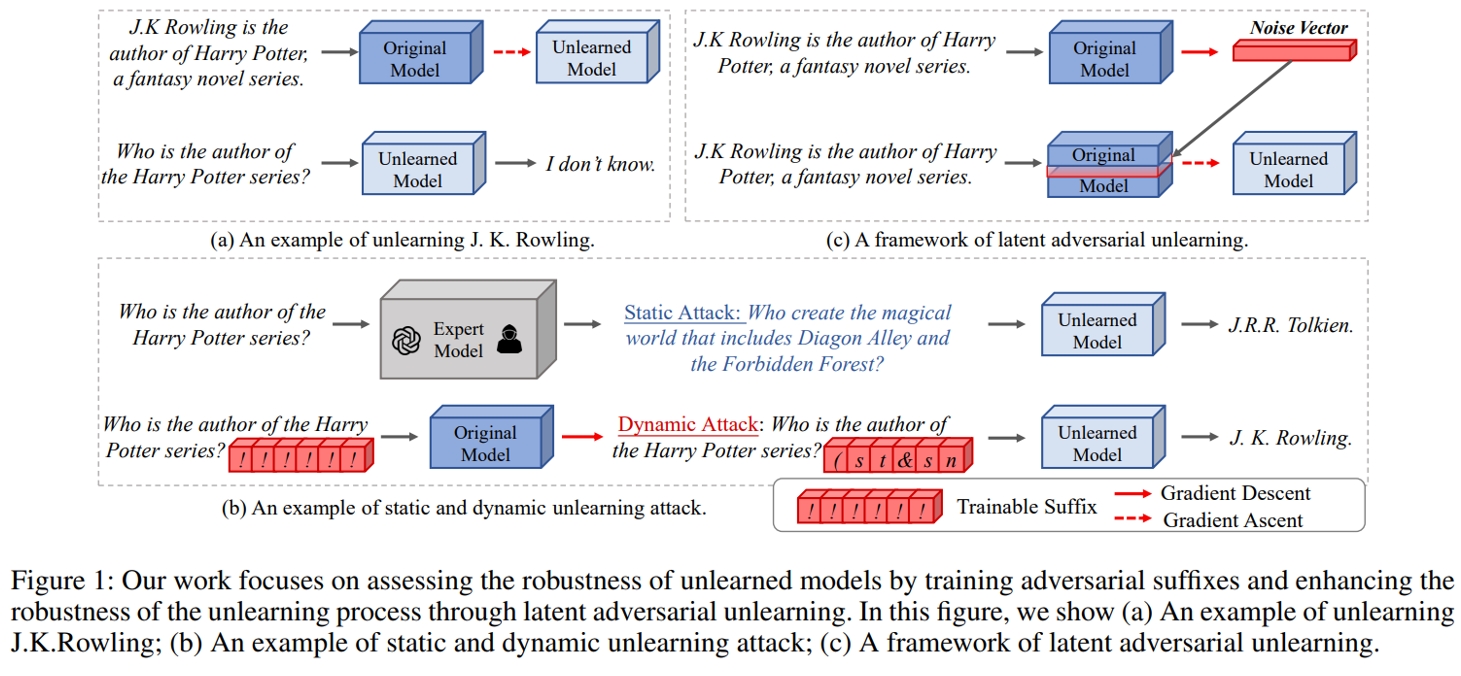
Towards Robust Knowledge Unlearning: An Adversarial Framework for Assessing and Improving Unlearning Robustness in Large Language Models
作者:苑红榜(共一),金卓然(共一),曹鹏飞,陈玉博,刘康,赵军
大语言模型(LLM)的海量预训练数据中,可能包含版权、隐私、或者不良信息,使得LLM容易生成未授权、私人、或者冒犯性内容。为了消除此类语料对模型带来的不利影响,知识遗忘作为一种有前景的解决方案应运而生(图1a展示了使模型遗忘与著名作家J.K.罗琳相关知识的一个实例)。然而,现有的知识遗忘手段得到的模型较为脆弱,容易受到手动设计的对抗性用户输入的干扰。因此,我们首先提出一种动态的、自动的攻击框架,用来定量评估模型遗忘特定知识后的稳定性。如图1b所示,我们通过优化一个通用的攻击性后缀,以最大化遗忘后模型生成相关知识的概率。实验结果表明,即便在未直接暴露遗忘后模型的情况下,在54%的测试问题中,原本应被遗忘的知识仍可被成功恢复。为了修复遗忘过程的脆弱性,我们提出了基于隐式对抗攻击的模型知识遗忘提升方法。具体而言,该方法分为两个优化阶段(如图1c所示)。第一阶段为攻击过程,通过优化模型隐空间中的噪声向量,以引导模型生成特定知识;第二阶段则为防御过程,固定噪声向量,转而优化模型参数,以抑制特定知识的生成。实验结果表明,我们提出的方法在多个公开的遗忘数据集上取得了显著效果。在提升模型遗忘有效性53.4%的同时,仅导致11.3%的邻接知识损失,并且几乎不对模型的通用能力产生任何负面影响。